임베디드시스템 프로그래밍[EECS463001]
나이별, 이름별, 지역별(zip code) 분포를 구하시오.
순서는 숫자, 알파벳 오름차순으로 정리
나이 : 10 ~ 89
zip code : 001 ~ 015
파일 내용
24,ABC,KS003
32,BCD,KS005
...
결과 출력 예제
전체 데이터 갯수 1,000,000개 중 이름은 xx,xxx개
나이:
10 ~ 19 : 3,423명
20 ~ 29 : 5,333명
..
80 ~ 89 : xxx명
Zip code
KS001: xxxxx명
KS002: xxxxx명
...
KS015: xxxxx명

나이분포
age = (line[0]-'0')*10 + (line[1]-'0'); //char를 int로
age = age/10; //나이대는 십의자리만 판별하면 되니까
age_arr[age-1]++; //해당하는 나이대에 ++중복하지 않은 이름 개수 세아리기
// 이름이 무조건 3자리니까 3차원 배열에 이름이 존재하지않으면 cnt++
location = (line[10]-'0')*10 + (line[11]-'0');
location_arr[location-1]++;
i = line[3]-'A';
j = line[4]-'A';
k = line[5]-'A';
if(name_arr[i][j][k]==0){
name_arr[i][j][k]++;
cnt++;
}지역분포
//범위가 1~15이기 때문에 크기가 15인 배열을 만들고 해당 하는 곳에 ++
location = (line[10]-'0')*10 + (line[11]-'0');
location_arr[location-1]++;행렬의 곱셈을 연산할 때 걸리는 시간, 쓰레드를 이용해서 행렬의 곱셈을 연산할 때 걸리는 시간

행렬의 곱셈을 연산할 때 걸리는 시간, 쓰레드를 이용해서 행렬의 곱셈을 연산할 때 걸리는 시간
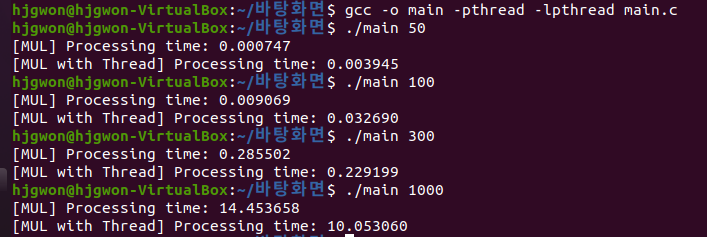
: 실행결과 데스크탑이 라즈베리파이보다 실행속도가 빨랐고, 데스크탑에서는 입력값이 작을때는 쓰레드를 이용하지 않았을때가 속도가 더 빨랐는데 입력이 커질수록 쓰레드를 이용했을때 실행속도가 빨랐습니다. 라즈베리파이의 경우 쓰레드를 이용한 경우가 더 빨랐고, 입력값이 클수록 쓰레드를 이용한 행렬곱셈과 이용하지 않은 곱셈의 실행시간 차이가 크게 나타났습니다.