Preliminary remark
This issue has been splitted into several follow up issues:
Bug description
The structure of Stack-overflow's html pages changed (especially for the post summary and very likely for posts too).
Previously posts where included in some div container of class "question-summary", which has changed to classes "s-post-summary and js-post-summary". This results in no posts being extracted from the summary page which finally results in a crash in the model training step.
Comment by the author
The issue will be fixed in a future release, where I will also address some issues that really bother me and I did not have the time yet to implement:
- refactoring the code (see the next paragraph for details)
- add automated unit tests at least for the domain layer
- fully implement the anticipated Error handling framework
- improve code documentation
All these measures will improve the application's maintainability further.
The target architecture
The following image illustrates the target module structure.
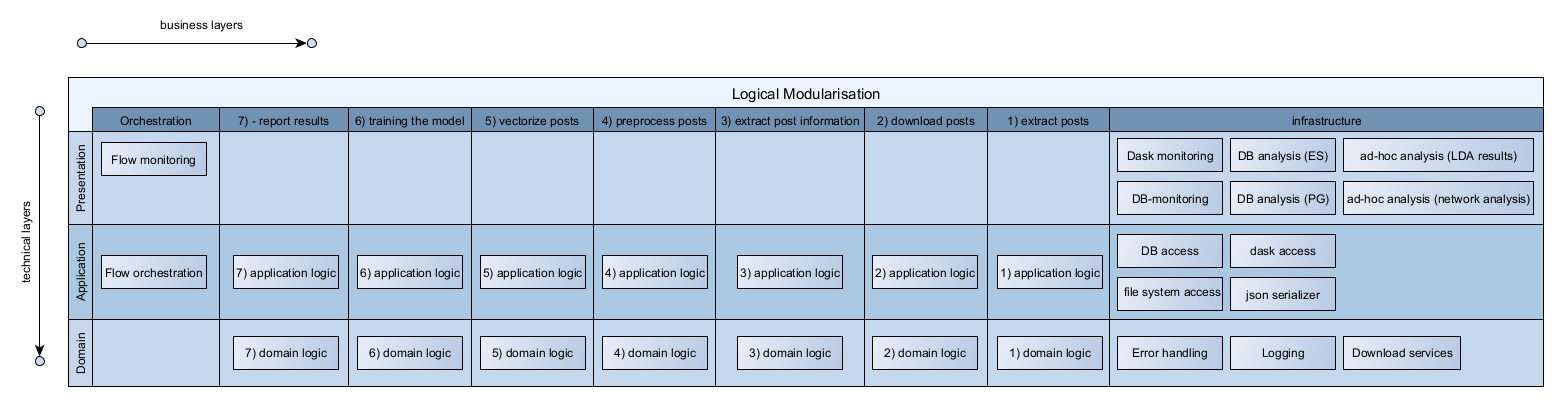
This figure shows the logical layers of the application on a technical level (top to bottom) and a functional level (left to right). It indicates that the domain layer is allowed to use logging, error handling and downloading posts (the last point actually only applies to the modules in the functional layers "extract posts" and "downloading posts" but I did not want to overload the picture by explicitly illustrating the dependencies by using arrows).
When refactoring the application this logical picture will be reflected better by the current code base. I will follow a partition by functional layering, meaning that there will exist packages (or sometimes maybe modules if the entire "table cell" is suitable to be put into a single python file) being named:
- infrastructure.logging
- extract_posts.application
The picture above is in line with the following design decisions:
-
the domain layer is designed in a functional way. Typically, the input and output types are modelled as Python data classes.
Each "step-like module" will provide these types in a dedicated module. The subsequent steps typically load this interface module as there is an input-output dependency between successive steps.
-
the application layer links the domain logic to infrastructure modules on the application level (middle cell in the functional infrastructure layer). This especially addresses database access. The application uses two ( dockerized ) databases, a relational database, postgreSQL, and a text database, Elastic Search .
-
Note that the design follows a bounded parallel processing approach, meaning that the tasks should not increase unboundedly with the number of stack-overflow posts. This is reached by assigning a unique ord_key for each run (which is just an integer starting at 1 and increasing by 1 for each of the following post). This is done within post extraction in step 1. The application level functions typically get two parameters, a max_number of tasks and a batch_id (between 0 and max_number_-1). The application level functions then loop over those posts where mod(ord_key, max_number)=batch_id, apply the domain logic of the corresponding layer and write the results back to the data base.
-
The orchestration layer uses Prefect together with Dask. The results of "task service functions" (as defined in the technical application layer of the "step-like" functional layers) should have input and output types that can be serialized (this is important to guarantee that they can be processed in Prefect/Dask and allows logging them into json fields of postgreSQL). "Task service functions" denotes those functions that are bound to prefect tasks in Orchestration/Application. Note that the infrastructure module provides a typed json serializer and a compatible de-serializer (the functionality uses the well-known Python packages marshmallow and marshmallow-dataclasses. In the target json string one field _type contains the name of the data class or the marshmallow schema and another field, data contains the output of serialisation using marshmallow or marshmallow-dataclasses. The de-serializer has a registry of all relevant data classes within the project, reads the type from the json file and parses the content of the data field into Python base types using marshmallow and marshmallow-dataclasses again.
-
The Presentation layer mainly uses existing tools for the base technologies chosen. This includes prefect UI for flow monitoring, pgAdmin and Kibana for data base analysis and data base monitoring. Dask monitoring is carried out by by Dask's standard tools for Dask monitoring. The ad-hoc analysis of LDA results and network analysis is done using Jupyter notebooks which utilize helper functions from infrastructure.DB access in order to access the data. For flow management a command line application has been created based on the Python package click.
Within this structure the current error is part of the domain logic in step 1), "extract posts". By adding appropriate unit tests for the domain layer, future changes in Stack overflow's page structure can be handled more gracefully. They can be recognized early and code changes are prevented from heavily impacting the remaining application.
Preliminary remark
This issue has been splitted into several follow up issues:
Bug description
The structure of Stack-overflow's html pages changed (especially for the post summary and very likely for posts too).
Previously posts where included in some div container of class "question-summary", which has changed to classes "s-post-summary and js-post-summary". This results in no posts being extracted from the summary page which finally results in a crash in the model training step.
Comment by the author
The issue will be fixed in a future release, where I will also address some issues that really bother me and I did not have the time yet to implement:
All these measures will improve the application's maintainability further.
The target architecture
The following image illustrates the target module structure.
This figure shows the logical layers of the application on a technical level (top to bottom) and a functional level (left to right). It indicates that the domain layer is allowed to use logging, error handling and downloading posts (the last point actually only applies to the modules in the functional layers "extract posts" and "downloading posts" but I did not want to overload the picture by explicitly illustrating the dependencies by using arrows).
When refactoring the application this logical picture will be reflected better by the current code base. I will follow a partition by functional layering, meaning that there will exist packages (or sometimes maybe modules if the entire "table cell" is suitable to be put into a single python file) being named:
The picture above is in line with the following design decisions:
the domain layer is designed in a functional way. Typically, the input and output types are modelled as Python data classes.
Each "step-like module" will provide these types in a dedicated module. The subsequent steps typically load this interface module as there is an input-output dependency between successive steps.
the application layer links the domain logic to infrastructure modules on the application level (middle cell in the functional infrastructure layer). This especially addresses database access. The application uses two ( dockerized ) databases, a relational database, postgreSQL, and a text database, Elastic Search .
Note that the design follows a bounded parallel processing approach, meaning that the tasks should not increase unboundedly with the number of stack-overflow posts. This is reached by assigning a unique ord_key for each run (which is just an integer starting at 1 and increasing by 1 for each of the following post). This is done within post extraction in step 1. The application level functions typically get two parameters, a max_number of tasks and a batch_id (between 0 and max_number_-1). The application level functions then loop over those posts where mod(ord_key, max_number)=batch_id, apply the domain logic of the corresponding layer and write the results back to the data base.
The orchestration layer uses Prefect together with Dask. The results of "task service functions" (as defined in the technical application layer of the "step-like" functional layers) should have input and output types that can be serialized (this is important to guarantee that they can be processed in Prefect/Dask and allows logging them into json fields of postgreSQL). "Task service functions" denotes those functions that are bound to prefect tasks in Orchestration/Application. Note that the infrastructure module provides a typed json serializer and a compatible de-serializer (the functionality uses the well-known Python packages marshmallow and marshmallow-dataclasses. In the target json string one field _type contains the name of the data class or the marshmallow schema and another field, data contains the output of serialisation using marshmallow or marshmallow-dataclasses. The de-serializer has a registry of all relevant data classes within the project, reads the type from the json file and parses the content of the data field into Python base types using marshmallow and marshmallow-dataclasses again.
The Presentation layer mainly uses existing tools for the base technologies chosen. This includes prefect UI for flow monitoring, pgAdmin and Kibana for data base analysis and data base monitoring. Dask monitoring is carried out by by Dask's standard tools for Dask monitoring. The ad-hoc analysis of LDA results and network analysis is done using Jupyter notebooks which utilize helper functions from infrastructure.DB access in order to access the data. For flow management a command line application has been created based on the Python package click.
Within this structure the current error is part of the domain logic in step 1), "extract posts". By adding appropriate unit tests for the domain layer, future changes in Stack overflow's page structure can be handled more gracefully. They can be recognized early and code changes are prevented from heavily impacting the remaining application.