I've been wanting to explore the world of Machine Learning so I wanted to look into some very basic ML algorithms and implement them into a functional program.
To do this I have used online sites such as Kaggle and Multiple tutorials on YouTube. I intend to re-use some of these into new datasets and implement them into other projects. This should fit nicely with the K Means Clustering Algorithm Visualiser I am currently working on.
Linear Regression is a machine learning algorithm based on supervised learning. It performs a regression task. Regression models a target prediction value based on independent variables. It is mostly used to see if there if a relatiosnship between two variables and if a predicition can be made. Different regression models differ based on – the kind of relationship between dependent and independent variables, they are considering and the number of independent variables being used and this is completly dependent on what data you have.
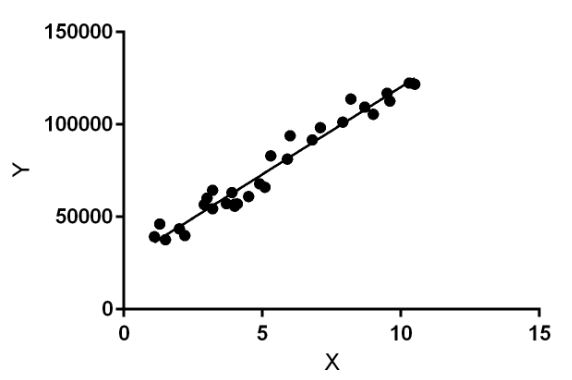
Linear regression performs the task to predict a dependent variable value (y) based on a given independent variable (x). So, this regression technique finds out a linear relationship between x (input) and y(output). Hence, the name is Linear Regression. In the figure above, X (input) is the work experience and Y (output) is the salary of a person. The regression line is the best fit line for our model.
As expected Linear Regression will not always give the best results however will work when trying to see if there is a relationship between the two variables. In my implementation on Linear Regression we saw a 75% - 90% accuracy will the model using a UCI dataset of students grades depending on previous performance.
A K-Nearest-Neighbor algorithm, also known as KNN, is an approach to data classification that estimates how likely a data point is to be a member of one group or the other depending on what group the data points nearest to it are in.
The KNN algorithm is an example of a "lazy learner" algorithm because it does not generate a model of the data set beforehand. The only calculations it makes are when it is asked to poll the data point's neighbors. This makes k-nn very easy to implement for data mining.
A support vector machine (SVM) is a supervised machine learning model that uses classification algorithms for two-group classification problems. After giving an SVM model sets of labeled training data for each category, they’re able to categorize new text.
K Means Clustering is an unsupervised Machine Learning Alogrithm. It is used when using datasets that are unlabeld. The goal of K Means Clustering is to find groups (or clusters) in datasets. The K in K means stands for the number of clusters. K means works iteratively to assign each data point to one of the clusters.