
In this project we took a data set and analyst it to know the gender of the speaker voice
The efficiency of the all self-labeled algorithms was evaluated using the Voice gender dataset and the Deterring dataset. Voice gender dataset took from https://www.kaggle.com. This database was created to identify a voice as male or female, based upon acoustic properties of the voice and speech. It consists of 3168 recorded voice samples, collected from male and female speakers. Each record from the dataset has contains 20 features that every feature represent the voice data

And the label represents the gender of that data.
We convert the data from the csv file to class that contains the features and the label. After that we build our first model.

For our first attempt we used logistic regression in order to classify between male and female and it showed good results after 6000 iteration.
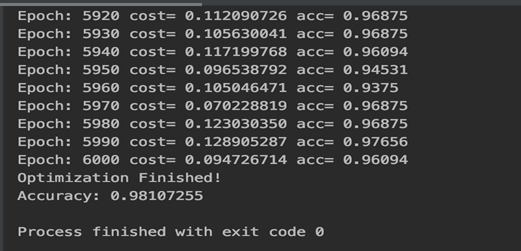
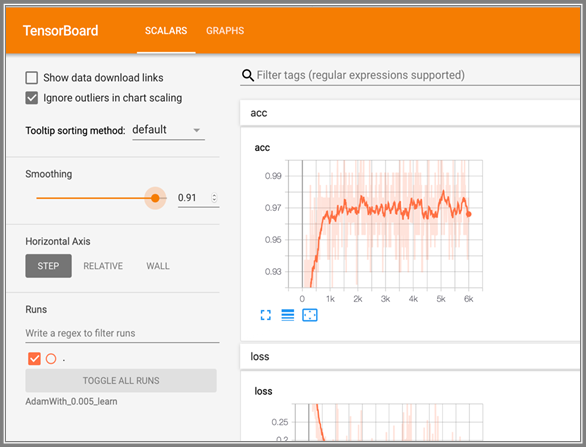
We tried to add multilayer perceptron that we used two Adding Hidden Layer by adding another weight and biases and multipy the two weight and biases, for 2500 iterations.
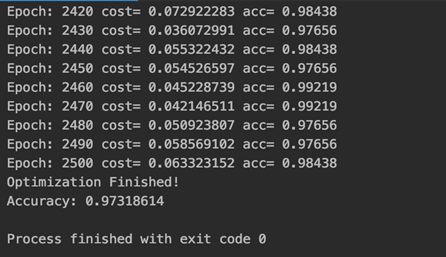
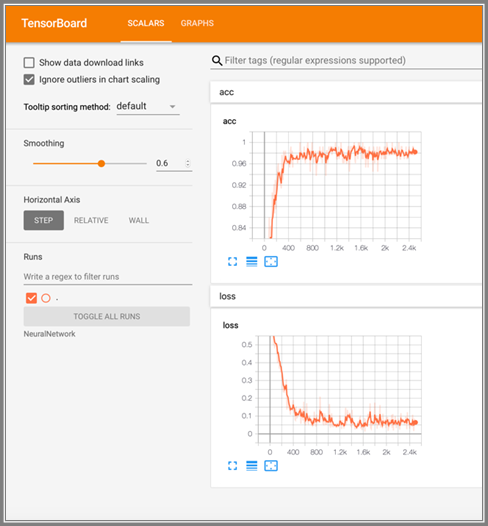
Reasons we chose this model: RNN can benefit sequential data like frequencies. We used RNN LSTM because of it’s important when dealing with time series data. Remembering those factors over time is crucial for to continuation of the learning and weights correctness and prevent vanishing gradient that happen with big batches of data like voice recording.
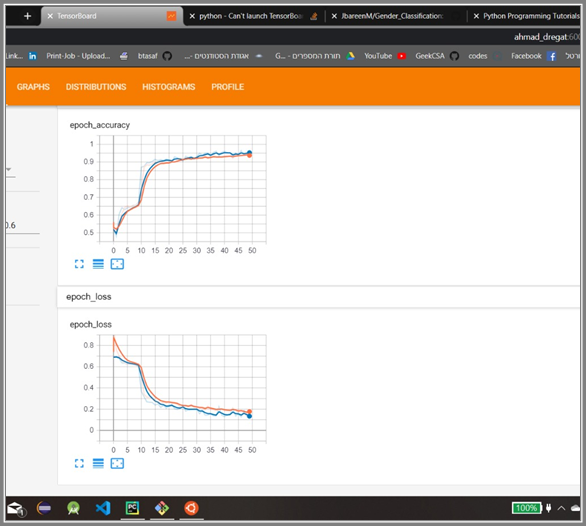
After using the neural network RNN and LSTM with 50 iteration we got 98%+ accuracy
authors Jbareen Mohamad, Dregat Ahmad, Amer Eyad