基于Google 开源项目风格指南——中文版:https://github.com/zh-google-styleguide/zh-google-styleguide
update:2019-03-31
当代码是某个算法的实现时,命名规范应优先符合算法公式中的定义,以便理解。
代码释出版本号,三位数字:1.2.2,其中大版本号看产品经理,中位软件更新升级添加功能,末位bug修复。
与C++规范大致相同,只不过函数的命名遵循全部小写字母,下划线分词,如:
int handle_event(int arg0, int arg1)
{
return arg0 + arg1;
}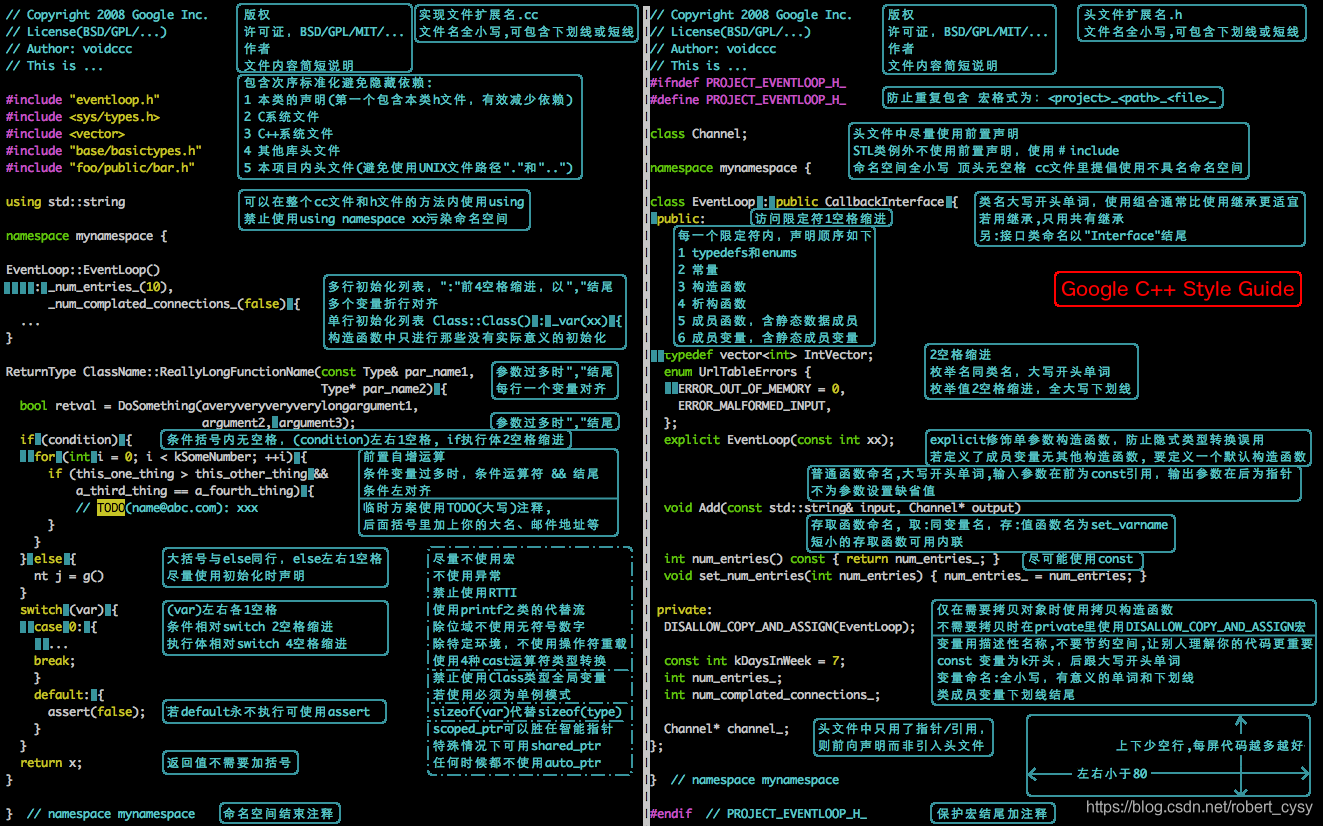
- 头文件应该能够自给自足(self-contained,也就是可以作为第一个头文件被引入),以 .h 结尾。至于用来插入文本的文件,说到底它们并不是头文件,所以应以 .inc 结尾。不允许分离出 -inl.h 头文件的做法.
- 用
ifndef def,endif避免头文件重复包含 - 若头文件中使用了其他定义,应将定义所在头文件包含进来;如果只用声明,则使用前向声明的方法,尽量不要出现交叉引用头文件。包含的话就包干净的纯外部的头,否则可能会导致包含顺序不确定,最终出现莫名其妙的编译错误。
- 在
stdafx.h中放置项目中使用较多的系统和第三方的依赖头,经常改动的头文件不要放在里面 - 包含头文件时应加上文件相对路径,如
#include "base/logging.h",而不是#include "logging.h" - 对于
xxx.cpp,头文件包含顺序应为:
xxx.h
OS SDK.h
C标准库.h
C++标准库.h
其他第三方库.h
本项目内.h
前置声明优缺点,来自google开源项目指南。
- 前置声明隐藏了依赖关系,头文件改动时,用户的代码会跳过必要的重新编译过程。
- 前置声明可能会被库的后续更改所破坏。前置声明函数或模板有时会妨碍头文件开发者变动其 API.例如扩大形参类型,加个自带默认参数的模板形参等等。
- 前置声明来自命名空间std:: 的 symbol 时,其行为未定义。
- 很难判断什么时候该用前置声明,什么时候该用 #include 。极端情况下,用前置声明代替 includes 甚至都会暗暗地改变代码的含义。
使用前置声明时需要注意的地方:
- 尽量避免前置声明那些定义在其他项目中的实体。
- 函数:总是使用#include。
- 类模板:优先使用#include。
只有当函数只有10行甚至更少时才将其定义为内联函数。
- 变量名一律小写,下划线分词。
- 函数参数的顺序为:输入参数在先,后跟输出参数。
- 当函数参数比较多时,应考虑用结构代替。
- 如果不能避免函数参数比较多,应在排版上考虑每个参数占用一行,参数名竖向对齐。
全部小写,使用下划线_进行分词,如dir_name。
(参照google开源项目规范)
总述:
文件名要全部小写,可以包含下划线(_)或连字符(-),依照项目的约定,如果没有约定,那么_更好,Joker使用全部小写,如filename.cpp。
说明,可接受的文件命名示例:
my_useful_class.cc
my-useful-class.cc
myusefulclass.cc- C++文件要以
.cc结尾,头文件以.h结尾,专门插入文本的文件则以.inc结尾,参见头文件自足 - 不要使用已经存在于
/usr/include下的文件名(Yang.Y 注: 即编译器搜索系统头文件的路径),如db.h - 通常应尽量让文件名更加明确,
http_server_logs.h就比logs.h要好。定义类时文件名一般成对出现,如foo_bar.h和foo_bar.cc,对应于类FooBar - 内联函数必须放在
.h文件中,如果内联函数比较短,就直接放在.h中。
首字母大写,使用驼峰命名法,不含下划线:
// 类、结构体和枚举
class UrlTable {
;
}
struct UrlTableProperties {
;
}
enum UrlTableErrors {
;
}遵循驼峰命名法,首字母小写,后面大写分词,如:
class Test {
public:
publicFunc(int* num_ptr); // 公有成员函数
private:
_privateFunc(int* num_ptr); // 私有成员函数
};避免名字中出现数字编号:如value1, value2等,除非逻辑上的确需要编号。
-
2.3.0 普通变量与结构体变量
不管是静态的还是非静态的, 结构体数据成员都可以和普通变量一样, 不用像类那样接下划线,全部小写字母,下划线分词,如:
std::string table_name;
struct UrlTableProperties {
string name;
int num_entries;
static Pool<UrlTableProperties>* pool;
};-
2.3.1 类数据成员
不管是静态的还是非静态的, 类数据成员都可以和普通变量一样, 但要接下划线,变量名后加一个下划线
_,如:
class TableInfo {
private:
string table_name_;
string tablename_;
static Pool<TableInfo>* pool_;
};-
2.3.2 指针变量
用p打头,如:
unsigned char* p_gpu_memory;宏和枚举值由全大写字母组成,单词间通过下划线来分割,如:
#define ERROR_UNKNOWN 1
enum EnumType {
OP_STOP = 0,
OP_START
};每个人都可能有自己的代码风格和格式, 但如果一个项目中的所有人都遵循同一风格的话, 这个项目就能更顺利地进行. 每个人未必能同意下述的每一处格式规则, 而且其中的不少规则需要一定时间的适应, 但整个项目服从统一的编程风格是很重要的, 只有这样才能让所有人轻松地阅读和理解代码.
为了帮助你正确的格式化代码, 我们写了一个 emacs 配置文件.
总述
每一行代码字符数不超过 80.
我们也认识到这条规则是有争议的, 但很多已有代码都遵照这一规则, 因此我们感觉一致性更重要.
优点
提倡该原则的人认为强迫他们调整编辑器窗口大小是很野蛮的行为. 很多人同时并排开几个代码窗口, 根本没有多余的空间拉伸窗口. 大家都把窗口最大尺寸加以限定, 并且 80 列宽是传统标准. 那么为什么要改变呢?
缺点
反对该原则的人则认为更宽的代码行更易阅读. 80 列的限制是上个世纪 60 年代的大型机的古板缺陷; 现代设备具有更宽的显示屏, 可以很轻松地显示更多代码.
结论
80 个字符是最大值.
如果无法在不伤害易读性的条件下进行断行, 那么注释行可以超过 80 个字符, 这样可以方便复制粘贴. 例如, 带有命令示例或 URL 的行可以超过 80 个字符.
包含长路径的 #include 语句可以超出80列.
头文件保护 可以无视该原则.
总述
尽量不使用非 ASCII 字符, 使用时必须使用 UTF-8 编码.
说明
即使是英文, 也不应将用户界面的文本硬编码到源代码中, 因此非 ASCII 字符应当很少被用到. 特殊情况下可以适当包含此类字符. 例如, 代码分析外部数据文件时, 可以适当硬编码数据文件中作为分隔符的非 ASCII 字符串; 更常见的是 (不需要本地化的) 单元测试代码可能包含非 ASCII 字符串. 此类情况下, 应使用 UTF-8 编码, 因为很多工具都可以理解和处理 UTF-8 编码.
十六进制编码也可以, 能增强可读性的情况下尤其鼓励 —— 比如 "\xEF\xBB\xBF", 或者更简洁地写作 u8"\uFEFF", 在 Unicode 中是 零宽度 无间断 的间隔符号, 如果不用十六进制直接放在 UTF-8 格式的源文件中, 是看不到的.
(Yang.Y 注: "\xEF\xBB\xBF" 通常用作 UTF-8 with BOM 编码标记)
使用 u8 前缀把带 uXXXX 转义序列的字符串字面值编码成 UTF-8. 不要用在本身就带 UTF-8 字符的字符串字面值上, 因为如果编译器不把源代码识别成 UTF-8, 输出就会出错.
别用 C++11 的 char16_t 和 char32_t, 它们和 UTF-8 文本没有关系, wchar_t 同理, 除非你写的代码要调用 Windows API, 后者广泛使用了 wchar_t.
总述
只使用空格, 每次缩进 2 个空格.
说明
我们使用空格缩进. 不要在代码中使用制表符. 你应该设置编辑器将制表符转为空格.
总述
返回类型和函数名在同一行, 参数也尽量放在同一行, 如果放不下就对形参分行, 分行方式与 函数调用 一致.
说明
函数看上去像这样:
ReturnType ClassName::FunctionName(Type par_name1, Type par_name2) {
DoSomething();
...
}如果同一行文本太多, 放不下所有参数:
ReturnType ClassName::ReallyLongFunctionName(Type par_name1, Type par_name2,
Type par_name3) {
DoSomething();
...
}甚至连第一个参数都放不下:
ReturnType LongClassName::ReallyReallyReallyLongFunctionName(
Type par_name1, // 4 space indent
Type par_name2,
Type par_name3) {
DoSomething(); // 2 space indent
...
}注意以下几点:
- 使用好的参数名.
- 只有在参数未被使用或者其用途非常明显时, 才能省略参数名.
- 如果返回类型和函数名在一行放不下, 分行.
- 如果返回类型与函数声明或定义分行了, 不要缩进.
- 左圆括号总是和函数名在同一行.
- 函数名和左圆括号间永远没有空格.
- 圆括号与参数间没有空格.
- 左大括号总在最后一个参数同一行的末尾处, 不另起新行.
- 右大括号总是单独位于函数最后一行, 或者与左大括号同一行.
- 右圆括号和左大括号间总是有一个空格.
- 所有形参应尽可能对齐.
- 缺省缩进为 2 个空格.
- 换行后的参数保持 4 个空格的缩进.
未被使用的参数, 或者根据上下文很容易看出其用途的参数, 可以省略参数名:
class Foo {
public:
Foo(Foo&&);
Foo(const Foo&);
Foo& operator=(Foo&&);
Foo& operator=(const Foo&);
};未被使用的参数如果其用途不明显的话, 在函数定义处将参数名注释起来:
class Shape {
public:
virtual void Rotate(double radians) = 0;
};
class Circle : public Shape {
public:
void Rotate(double radians) override;
};
void Circle::Rotate(double /*radians*/) {}
// 差 - 如果将来有人要实现, 很难猜出变量的作用.
void Circle::Rotate(double) {}属性, 和展开为属性的宏, 写在函数声明或定义的最前面, 即返回类型之前:
MUST_USE_RESULT bool IsOK();总述
Lambda 表达式对形参和函数体的格式化和其他函数一致; 捕获列表同理, 表项用逗号隔开.
说明
若用引用捕获, 在变量名和 & 之间不留空格.
int x = 0;
auto add_to_x = [&x](int n) { x += n; };短 lambda 就写得和内联函数一样.
std::set<int> blacklist = {7, 8, 9};
std::vector<int> digits = {3, 9, 1, 8, 4, 7, 1};
digits.erase(std::remove_if(digits.begin(), digits.end(), [&blacklist](int i) {
return blacklist.find(i) != blacklist.end();
}),
digits.end());总述
要么一行写完函数调用, 要么在圆括号里对参数分行, 要么参数另起一行且缩进四格. 如果没有其它顾虑的话, 尽可能精简行数, 比如把多个参数适当地放在同一行里.
说明
函数调用遵循如下形式:
bool retval = DoSomething(argument1, argument2, argument3);如果同一行放不下, 可断为多行, 后面每一行都和第一个实参对齐, 左圆括号后和右圆括号前不要留空格:
bool retval = DoSomething(averyveryveryverylongargument1,
argument2, argument3);参数也可以放在次行, 缩进四格:
if (...) {
...
...
if (...) {
DoSomething(
argument1, argument2, // 4 空格缩进
argument3, argument4);
}把多个参数放在同一行以减少函数调用所需的行数, 除非影响到可读性. 有人认为把每个参数都独立成行, 不仅更好读, 而且方便编辑参数. 不过, 比起所谓的参数编辑, 我们更看重可读性, 且后者比较好办:
如果一些参数本身就是略复杂的表达式, 且降低了可读性, 那么可以直接创建临时变量描述该表达式, 并传递给函数:
int my_heuristic = scores[x] * y + bases[x];
bool retval = DoSomething(my_heuristic, x, y, z);或者放着不管, 补充上注释:
bool retval = DoSomething(scores[x] * y + bases[x], // Score heuristic.
x, y, z);如果某参数独立成行, 对可读性更有帮助的话, 那也可以如此做. 参数的格式处理应当以可读性而非其他作为最重要的原则.
此外, 如果一系列参数本身就有一定的结构, 可以酌情地按其结构来决定参数格式:
// 通过 3x3 矩阵转换 widget.
my_widget.Transform(x1, x2, x3,
y1, y2, y3,
z1, z2, z3);总述
您平时怎么格式化函数调用, 就怎么格式化 列表初始化.
说明
如果列表初始化伴随着名字, 比如类型或变量名, 格式化时将将名字视作函数调用名, {} 视作函数调用的括号. 如果没有名字, 就视作名字长度为零.
// 一行列表初始化示范.
return {foo, bar};
functioncall({foo, bar});
pair<int, int> p{foo, bar};
// 当不得不断行时.
SomeFunction(
{"assume a zero-length name before {"}, // 假设在 { 前有长度为零的名字.
some_other_function_parameter);
SomeType variable{
some, other, values,
{"assume a zero-length name before {"}, // 假设在 { 前有长度为零的名字.
SomeOtherType{
"Very long string requiring the surrounding breaks.", // 非常长的字符串, 前后都需要断行.
some, other values},
SomeOtherType{"Slightly shorter string", // 稍短的字符串.
some, other, values}};
SomeType variable{
"This is too long to fit all in one line"}; // 字符串过长, 因此无法放在同一行.
MyType m = { // 注意了, 您可以在 { 前断行.
superlongvariablename1,
superlongvariablename2,
{short, interior, list},
{interiorwrappinglist,
interiorwrappinglist2}};总述
倾向于不在圆括号内使用空格. 关键字 if 和 else 另起一行.
说明
对基本条件语句有两种可以接受的格式. 一种在圆括号和条件之间有空格, 另一种没有.
最常见的是没有空格的格式. 哪一种都可以, 最重要的是 保持一致. 如果你是在修改一个文件, 参考当前已有格式. 如果是写新的代码, 参考目录下或项目中其它文件. 还在犹豫的话, 就不要加空格了.
if (condition) { // 圆括号里没有空格.
... // 2 空格缩进.
} else if (...) { // else 与 if 的右括号同一行.
...
} else {
...
}如果你更喜欢在圆括号内部加空格:
if ( condition ) { // 圆括号与空格紧邻 - 不常见
... // 2 空格缩进.
} else { // else 与 if 的右括号同一行.
...
}注意所有情况下 if 和左圆括号间都有个空格. 右圆括号和左大括号之间也要有个空格:
if(condition) // 差 - IF 后面没空格.
if (condition){ // 差 - { 前面没空格.
if(condition){ // 变本加厉地差.
if (condition) { // 好 - IF 和 { 都与空格紧邻.如果能增强可读性, 简短的条件语句允许写在同一行. 只有当语句简单并且没有使用 else 子句时使用:
if (x == kFoo) return new Foo();
if (x == kBar) return new Bar();如果语句有 else 分支则不允许:
// 不允许 - 当有 ELSE 分支时 IF 块却写在同一行
if (x) DoThis();
else DoThat();通常, 单行语句不需要使用大括号, 如果你喜欢用也没问题; 复杂的条件或循环语句用大括号可读性会更好. 也有一些项目要求 if 必须总是使用大括号:
if (condition)
DoSomething(); // 2 空格缩进.
if (condition) {
DoSomething(); // 2 空格缩进.
}但如果语句中某个 if-else 分支使用了大括号的话, 其它分支也必须使用:
// 不可以这样子 - IF 有大括号 ELSE 却没有.
if (condition) {
foo;
} else
bar;
// 不可以这样子 - ELSE 有大括号 IF 却没有.
if (condition)
foo;
else {
bar;
}
// 只要其中一个分支用了大括号, 两个分支都要用上大括号.
if (condition) {
foo;
} else {
bar;
}总述
switch 语句可以使用大括号分段, 以表明 cases 之间不是连在一起的. 在单语句循环里, 括号可用可不用. 空循环体应使用 {} 或 continue.
说明
switch 语句中的 case 块可以使用大括号也可以不用, 取决于你的个人喜好. 如果用的话, 要按照下文所述的方法.
如果有不满足 case 条件的枚举值, switch 应该总是包含一个 default 匹配 (如果有输入值没有 case 去处理, 编译器将给出 warning). 如果 default 应该永远执行不到, 简单的加条 assert:
switch (var) {
case 0: { // 2 空格缩进
... // 4 空格缩进
break;
}
case 1: {
...
break;
}
default: {
assert(false);
}
}在单语句循环里, 括号可用可不用:
for (int i = 0; i < kSomeNumber; ++i)
printf("I love you\n");
for (int i = 0; i < kSomeNumber; ++i) {
printf("I take it back\n");
}空循环体应使用 {} 或 continue, 而不是一个简单的分号.
while (condition) {
// 反复循环直到条件失效.
}
for (int i = 0; i < kSomeNumber; ++i) {} // 可 - 空循环体.
while (condition) continue; // 可 - contunue 表明没有逻辑.
while (condition); // 差 - 看起来仅仅只是 while/loop 的部分之一.总述
句点或箭头前后不要有空格. 指针/地址操作符 (*, &) 之后不能有空格.
说明
下面是指针和引用表达式的正确使用范例:
x = *p;
p = &x;
x = r.y;
x = r->y;注意:
- 在访问成员时, 句点或箭头前后没有空格.
- 指针操作符
*或&后没有空格.
在声明指针变量或参数时, 星号与类型或变量名紧挨都可以:
// 好, 空格前置.
char *c;
const string &str;
// 好, 空格后置.
char* c;
const string& str;
int x, *y; // 不允许 - 在多重声明中不能使用 & 或 *
char * c; // 差 - * 两边都有空格
const string & str; // 差 - & 两边都有空格.在单个文件内要保持风格一致, 所以, 如果是修改现有文件, 要遵照该文件的风格.
总述
如果一个布尔表达式超过 标准行宽, 断行方式要统一一下.
说明
下例中, 逻辑与 (&&) 操作符总位于行尾:
if (this_one_thing > this_other_thing &&
a_third_thing == a_fourth_thing &&
yet_another && last_one) {
...
}注意, 上例的逻辑与 (&&) 操作符均位于行尾. 这个格式在 Google 里很常见, 虽然把所有操作符放在开头也可以. 可以考虑额外插入圆括号, 合理使用的话对增强可读性是很有帮助的. 此外, 直接用符号形式的操作符, 比如 && 和 ~, 不要用词语形式的 and 和 compl.
总述
不要在 return 表达式里加上非必须的圆括号.
说明
只有在写 x = expr 要加上括号的时候才在 return expr; 里使用括号.
return result; // 返回值很简单, 没有圆括号.
// 可以用圆括号把复杂表达式圈起来, 改善可读性.
return (some_long_condition &&
another_condition);
return (value); // 毕竟您从来不会写 var = (value);
return(result); // return 可不是函数!总述
用 =, () 和 {} 均可.
说明
您可以用 =, () 和 {}, 以下的例子都是正确的:
int x = 3;
int x(3);
int x{3};
string name("Some Name");
string name = "Some Name";
string name{"Some Name"};请务必小心列表初始化 {...} 用 std::initializer_list 构造函数初始化出的类型. 非空列表初始化就会优先调用 std::initializer_list, 不过空列表初始化除外, 后者原则上会调用默认构造函数. 为了强制禁用 std::initializer_list 构造函数, 请改用括号.
vector<int> v(100, 1); // 内容为 100 个 1 的向量.
vector<int> v{100, 1}; // 内容为 100 和 1 的向量.此外, 列表初始化不允许整型类型的四舍五入, 这可以用来避免一些类型上的编程失误.
int pi(3.14); // 好 - pi == 3.
int pi{3.14}; // 编译错误: 缩窄转换.总述
预处理指令不要缩进, 从行首开始.
说明
即使预处理指令位于缩进代码块中, 指令也应从行首开始.
// 好 - 指令从行首开始
if (lopsided_score) {
#if DISASTER_PENDING // 正确 - 从行首开始
DropEverything();
# if NOTIFY // 非必要 - # 后跟空格
NotifyClient();
# endif
#endif
BackToNormal();
}
// 差 - 指令缩进
if (lopsided_score) {
#if DISASTER_PENDING // 差 - "#if" 应该放在行开头
DropEverything();
#endif // 差 - "#endif" 不要缩进
BackToNormal();
}总述
访问控制块的声明依次序是 public:, protected:, private:, 每个都缩进 1 个空格.
说明
类声明 (下面的代码中缺少注释, 参考 类注释) 的基本格式如下:
class MyClass : public OtherClass {
public: // 注意有一个空格的缩进
MyClass(); // 标准的两空格缩进
explicit MyClass(int var);
~MyClass() {}
void SomeFunction();
void SomeFunctionThatDoesNothing() {
}
void set_some_var(int var) { some_var_ = var; }
int some_var() const { return some_var_; }
private:
bool SomeInternalFunction();
int some_var_;
int some_other_var_;
};注意事项:
- 所有基类名应在 80 列限制下尽量与子类名放在同一行.
- 关键词
public:,protected:,private:要缩进 1 个空格. - 除第一个关键词 (一般是
public) 外, 其他关键词前要空一行. 如果类比较小的话也可以不空. - 这些关键词后不要保留空行.
public放在最前面, 然后是protected, 最后是private.- 关于声明顺序的规则请参考 声明顺序 一节.
总述
构造函数初始化列表放在同一行或按四格缩进并排多行.
说明
下面两种初始值列表方式都可以接受:
// 如果所有变量能放在同一行:
MyClass::MyClass(int var) : some_var_(var) {
DoSomething();
}
// 如果不能放在同一行,
// 必须置于冒号后, 并缩进 4 个空格
MyClass::MyClass(int var)
: some_var_(var), some_other_var_(var + 1) {
DoSomething();
}
// 如果初始化列表需要置于多行, 将每一个成员放在单独的一行
// 并逐行对齐
MyClass::MyClass(int var)
: some_var_(var), // 4 space indent
some_other_var_(var + 1) { // lined up
DoSomething();
}
// 右大括号 } 可以和左大括号 { 放在同一行
// 如果这样做合适的话
MyClass::MyClass(int var)
: some_var_(var) {}总述
命名空间内容不缩进.
说明
命名空间 不要增加额外的缩进层次, 例如:
namespace {
void foo() { // 正确. 命名空间内没有额外的缩进.
...
}
} // namespace不要在命名空间内缩进:
namespace {
// 错, 缩进多余了.
void foo() {
...
}
} // namespace声明嵌套命名空间时, 每个命名空间都独立成行.
namespace foo {
namespace bar {总述
水平留白的使用根据在代码中的位置决定. 永远不要在行尾添加没意义的留白.
说明
void f(bool b) { // 左大括号前总是有空格.
...
int i = 0; // 分号前不加空格.
// 列表初始化中大括号内的空格是可选的.
// 如果加了空格, 那么两边都要加上.
int x[] = { 0 };
int x[] = {0};
// 继承与初始化列表中的冒号前后恒有空格.
class Foo : public Bar {
public:
// 对于单行函数的实现, 在大括号内加上空格
// 然后是函数实现
Foo(int b) : Bar(), baz_(b) {} // 大括号里面是空的话, 不加空格.
void Reset() { baz_ = 0; } // 用空格把大括号与实现分开.
...添加冗余的留白会给其他人编辑时造成额外负担. 因此, 行尾不要留空格. 如果确定一行代码已经修改完毕, 将多余的空格去掉; 或者在专门清理空格时去掉(尤其是在没有其他人在处理这件事的时候). (Yang.Y 注: 现在大部分代码编辑器稍加设置后, 都支持自动删除行首/行尾空格, 如果不支持, 考虑换一款编辑器或 IDE)
if (b) { // if 条件语句和循环语句关键字后均有空格.
} else { // else 前后有空格.
}
while (test) {} // 圆括号内部不紧邻空格.
switch (i) {
for (int i = 0; i < 5; ++i) {
switch ( i ) { // 循环和条件语句的圆括号里可以与空格紧邻.
if ( test ) { // 圆括号, 但这很少见. 总之要一致.
for ( int i = 0; i < 5; ++i ) {
for ( ; i < 5 ; ++i) { // 循环里内 ; 后恒有空格, ; 前可以加个空格.
switch (i) {
case 1: // switch case 的冒号前无空格.
...
case 2: break; // 如果冒号有代码, 加个空格.// 赋值运算符前后总是有空格.
x = 0;
// 其它二元操作符也前后恒有空格, 不过对于表达式的子式可以不加空格.
// 圆括号内部没有紧邻空格.
v = w * x + y / z;
v = w*x + y/z;
v = w * (x + z);
// 在参数和一元操作符之间不加空格.
x = -5;
++x;
if (x && !y)
...// 尖括号(< and >) 不与空格紧邻, < 前没有空格, > 和 ( 之间也没有.
vector<string> x;
y = static_cast<char*>(x);
// 在类型与指针操作符之间留空格也可以, 但要保持一致.
vector<char *> x;总述
垂直留白越少越好.
说明
这不仅仅是规则而是原则问题了: 不在万不得已, 不要使用空行. 尤其是: 两个函数定义之间的空行不要超过 2 行, 函数体首尾不要留空行, 函数体中也不要随意添加空行.
基本原则是: 同一屏可以显示的代码越多, 越容易理解程序的控制流. 当然, 过于密集的代码块和过于疏松的代码块同样难看, 这取决于你的判断. 但通常是垂直留白越少越好.
下面的规则可以让加入的空行更有效:
- 函数体内开头或结尾的空行可读性微乎其微.
- 在多重 if-else 块里加空行或许有点可读性.
PEP是Python Enhancement Proposal的缩写,通常翻译为“Python增强提案”。 每个PEP都是一份为Python社区提供的指导Python往更好的方向发展的技术文档,其中的第8号增强提案(PEP 8)是针对Python语言编订的代码风格指南。 PEP8 命名规约:https://www.python.org/dev/peps/pep-0008/#prescriptive-naming-conventions。 本规约基于PEP8标准,部分编码规范细节参考Google开源项目风格指南。
用4个空格来缩进代码。
- 使用空格来表示缩进而不要用制表符(Tab)。这一点对习惯了其他编程语言的人来说简直觉得不可理喻,因为绝大多数的程序员都会用Tab来表示缩进,但是要知道Python并没有像C/C++或Java那样的用花括号来构造一个代码块的语法,在Python中分支和循环结构都使用缩进来表示哪些代码属于同一个级别,鉴于此Python代码对缩进以及缩进宽度的依赖比其他很多语言都强得多。在不同的编辑器中,Tab的宽度可能是2、4或8个字符,甚至是其他更离谱的值,用Tab来表示缩进对Python代码来说可能是一场灾难。
- 和语法相关的每一层缩进都用4个空格来表示。
- 每行的字符数不要超过79个字符,如果表达式因太长而占据了多行,除了首行之外的其余各行都应该在正常的缩进宽度上再加上4个空格。
- 二元运算符的左右两侧应该保留一个空格,而且只要一个空格就好。
- 括号内不要有空格,如:
def spam(ham[1], {eggs: 2}, []) # OK
def spam( ham[ 1 ], { eggs: 2 }, [ ] ) # Bad- 索引或切片的左括号前不应加空格,如:
dict['key'] = list[index] # OK
dict ['key'] = list [index] # Bad- 当’=’用于指示关键字参数或默认参数值时,不要在其两侧使用空格,如:
Yes: def complex(real, imag=0.0): return magic(r=real, i=imag)
No: def complex(real, imag = 0.0): return magic(r = real, i = imag)不要在行尾加分号, 也不要用分号将两条命令放在同一行。
宁缺毋滥的使用括号,不要使用反斜杠链接行,Python会将圆括号,中括号和花括号中的行隐式的连接起来,可以利用这个特点。 如果需要,可以在表达式外围增加一对额外的圆括号,如:
foo_bar(self, width, height, color='black',
design=None, x='foo',
emphasis=None, highlight=0)
if (width == 0 and height == 0 and
color == 'red' and emphasis == 'strong'):
pass如果一个文本字符串在一行放不下,可以使用圆括号来实现隐式行连接:
x = ('This will build a very long long '
'long long long long long long string')(来自google开源项目规范)
- 顶级定义之间空两行,比如类与类,类与函数,函数与函数之间。
- 方法定义,类定义与第一个方法之间,都应该空一行。函数中的逻辑段落间加空行,把相关的代码紧凑写在一起,作为一个逻辑段落,段落间以空行分隔。
- 在import不同种类的模块间加空行
class Test(object):
"""Test class,提供通用的方法"""
def __init__(self):
"""Test的构造器:"""
pass
def function1(self):
pass
def function2(self):
pass
def function3():
pass每行不超过80个字符,换行反斜杠
with open('test.txt','w') as file_1, \
open("test2.txt", 'w') as file_2:
file_2.write(file_1.read())
# 字符串
query_str = ('my name'
'is'
' %s') % "Tom"
print query_str
# 二元运算符
income = (gross_wages
+ taxable_interest
+ (dividends - qualified_dividends)
- ira_deduction
- student_loan_interest)仅当 ], ), } 和末位元素不在同一行时,推荐使用序列元素尾部逗号. 当末位元素尾部有逗号时,元素后的逗号可以指示 YAPF 将序列格式化为每行一项.
Yes: golomb3 = [0, 1, 3]
Yes: golomb4 = [
0,
1,
4,
6,
]
No: golomb4 = [
0,
1,
4,
6
]仅对包和模块使用导入,而不单独导入函数或者类。typing模块例外。(来自google开源项目指南)
尽量使用全局导入,那么什么时候使用函数本地导入呢?有以下三种情况:
- 您不能更早地使用导入。这发生在例如在运行时通过配置或系统检查选择数据库或其他系统/功能的后端。
- 否则你有循环导入。这是一种罕见的情况,也是一种代码味道,因此如果有必要,请考虑重构。
- 通过推迟模块导入来减少启动时间。但这很少有用。
应该避免通配符导入(from tt_module import *),每个导入应该独占一行,按照从最通用到最不通用的顺序分组:
- 标准库导入
- 第三方库导入
- 应用程序指定导入
>>> import my_module
>>> my_module.external_func()
23
>>> my_module._internal_func()
42所谓”内部(Internal)”表示仅模块内可用, 或者, 在类内是保护或私有的. 将相关的类和顶级函数放在同一个模块里. 不像Java, 没必要限制一个类一个模块.
Python之父Guido推荐的规范
| Type | Public | Internal |
|---|---|---|
| Modules | lower_with_under | _lower_with_under |
| Packages | lower_with_under | |
| Classes | CapWords | _CapWords |
| Exceptions | CapWords | |
| Functions | lower_with_under() | _lower_with_under() |
| Global/Class Constants | GLOBAL_CONSTANT_NAME/CAPS_WITH_UNDER | _CAPS_WITH_UNDER |
| Global/Class Variables | global_var_name/lower_with_under | _lower_with_under |
| Instance Variables | lower_with_under | _lower_with_under (protected) or __lower_with_under (private) |
| Method Names | lower_with_under() | _lower_with_under() (protected) or __lower_with_under() (private) |
| Function/Method Parameters | lower_with_under | |
| Local Variables | lower_with_under |
小写字母,单词之间用_分割,如package_name
(PEP8) 对类名使用大写字母开头的单词(如CapWords, 即Pascal风格), 但是模块名应该用小写加下划线的方式(如lower_with_under.py). 尽管已经有很多现存的模块使用类似于CapWords.py这样的命名, 但现在已经不鼓励这样做, 因为如果模块名碰巧和类名一致, 这会让人困扰. When an extension module written in C or C++ has an accompanying Python module that provides a higher level (e.g. more object oriented) interface, the C/C++ module has a leading underscore (e.g. _socket).
因为很多模块文件存与模块名称一致的类,模块采用小写,类采用首字母大写,这样就能区分开模块和类
小写字母,单词之间用_分割,如:ad_stats.py
首字母大写,驼峰命名法(CamelCase),不使用下划线连接单词,使用大小写分词,对于基类,可以加一个Base或者Abstract前缀,,私有类可用一个下划线开头如:
class _PrivateClass(object):
pass
class TestClass(object):
pass
class BaseCookie(object):
pass
class AbstractGroup(object):
pass类的实例方法,应该把第一个参数命名为self以表示对象自身。
类的类方法,应该把第一个参数命名为cls以表示该类自身。
类内部函数命名,用单下划线(_)开头(该函数可被继承访问) 类内私有函数命名,用双下划线(__)开头(该函数不可被继承访问)
class Person(object):
def public_func(object):
pass
def _protected_func(object):
pass
def __private_func(object)
pass大小写混用仅允许在已有代码中为了与现有风格保持一致(PEP8); 双下划线开头,双下划线结尾,为系统内置变量。
class TestClass(object):
# 类的公有变量,小写字母,下划线分词,如:
self.public_variable = True
# 类的保护变量,单下划线开头,全部小写字母,下划线分词,如:
# 单个下划线是一个Python命名约定,表示这个名称是供内部使用的。 它通常不由Python解释器强制执行,仅仅作为一种对程序员的提示。
# 该变量可被继承访问,保护变量;
self._protected_variable = False
# 双下划线前缀会导致Python解释器重写属性名称,以避免子类中的命名冲突。
# 该变量不可被继承访问,私有变量;
# Python mangles these names with the class name: if class Foo has an attribute named __a, it cannot be accessed by Foo.__a. (An insistent user could still gain access by calling Foo._Foo__a.) Generally, double leading underscores should be used only to avoid name conflicts with attributes in classes designed to be subclassed.
# Note: there is some controversy about the use of __names (see below).
self.__private_variable = True
def func():
# 普通变量
this_is_a_variable = True
if __name__ == '__main__':
# 全局变量,global开头,小写字母,下划线分词,如:
global_var = 0模块级常量全部大写,下划线分词,如MAX_OVERFLOW和TOTAL
MAX_CLIENT = 100
MAX_CONNECTION = 1000
CONNECTION_TIMEOUT = 600按照习惯,有时候单个独立下划线是用作一个名字,来表示某个变量是临时的或无关紧要的。 例如,在下面的循环中,我们不需要访问正在运行的索引,我们可以使用“_”来表示它只是一个临时值:
for _ in range(32):
print('Hello, World.')
# 你可以在一个解释器会话中访问先前计算的结果,或者,你是在动态构建多个对象并与它们交互,无需事先给这些对象分配名字:
>>> 20 + 3
23
>>> _
23
>>> print(_)
23
>>> list()
[]
>>> _.append(1)
>>> _.append(2)
>>> _.append(3)
>>> _
[1, 2, 3]Python有一种独一无二的的注释方式:使用文档字符串。文档字符串是包、模块、类或函数里的第一个语句。这些字符串可以通过对象的__doc__成员被自动提取,并且被pydoc所用(你可以在你的模块上运行pydoc试一把,看看它长什么样)。
我们对文档字符串的惯例是使用三重双引号”””(PEP-257),一个文档字符串应该这样组织:首先是一行以句号、问号或惊叹号结尾的概述(或者该文档字符串单纯只有一行),接着是一个空行,接着是文档字符串剩下的部分,它应该与文档字符串的第一行的第一个引号对齐,下面有更多文档字符串的格式化规范。
每个文件应该包含一个许可样板,根据项目使用的许可(例如:Apache 2.0,BSD,LGPL,GPL),选择合适的样板,其开头应是对模块内容和用法的描述。
"""A one line summary of the module or program, terminated by a period.
Leave one blank line. The rest of this docstring should contain an
overall description of the module or program. Optionally, it may also
contain a brief description of exported classes and functions and/or usage
examples.
Typical usage example:
foo = ClassFoo()
bar = foo.FunctionBar()
"""在Python之禅(可以使用import this查看)中有这么一句名言:“There should be one-- and preferably only one --obvious way to do it.”,翻译成中文是“做一件事应该有而且最好只有一种确切的做法”,这句话传达的思想在PEP 8中也是无处不在的。
- 采用内联形式的否定词,而不要把否定词放在整个表达式的前面。例如if a is not b就比if not a is b更容易让人理解。
- 不要用检查长度的方式来判断字符串、列表等是否为None或者没有元素,应该用if not x这样的写法来检查它。
- 就算if分支、for循环、except异常捕获等中只有一行代码,也不要将代码和if、for、except等写在一起,分开写才会让代码更清晰。
- import语句总是放在文件开头的地方。
- 引入模块的时候,from math import sqrt比import math更好。
- 如果有多个import语句,应该将其分为三部分,从上到下分别是Python标准模块、第三方模块和自定义模块,每个部分内部应该按照模块名称的字母表顺序来排列。
- 除非是用于实现行连接, 否则不要在返回语句或条件语句中使用括号. 不过在元组两边使用括号是可以的。