Web Zip file importing#1062
Conversation
5c3e22d to
1dbce8f
Compare
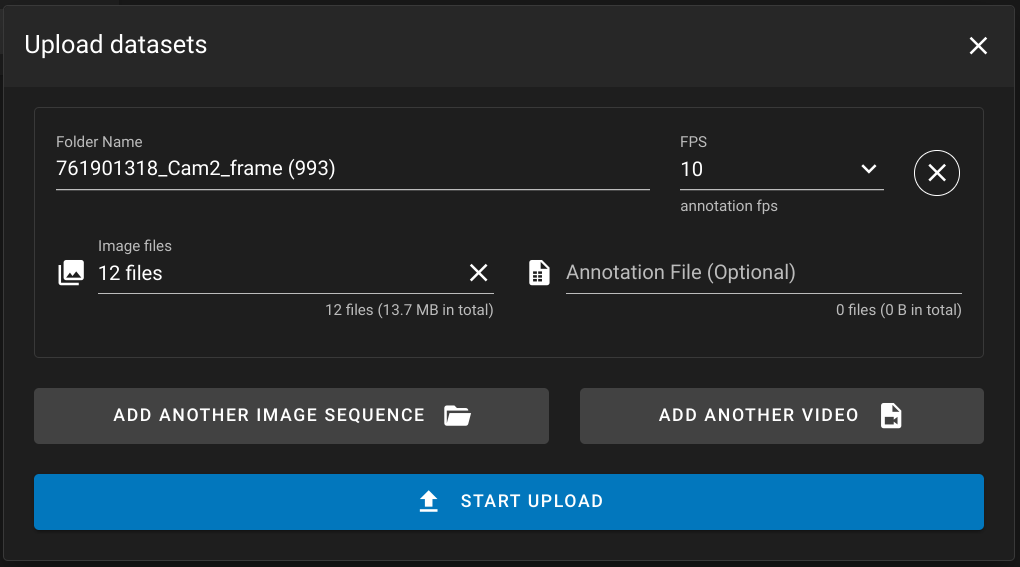
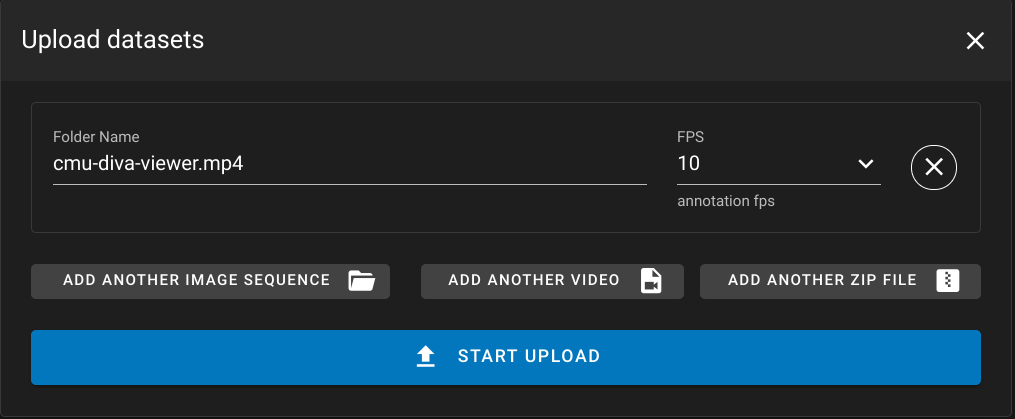
| Single flat annotations inside of a zip file can be uploaded as well as invidiual videos or images. | ||
| Images can be zipped together with their annotations and uploaded. |
There was a problem hiding this comment.
I think this could be more clearly written. What can you have inside a zip file? Perhaps something like this:
A zip import can have one of the following file combinations:
- One or more images, an optional annotation file, and an optional configuration file
- One video with an optional annotation file and an optional configuration file
83ccbb3 to
6f255e0
Compare
|
Addressed comments.
|
 subdavis
left a comment
subdavis
left a comment
There was a problem hiding this comment.
Please reorder operations in the celery task
The rest (defensive logic, eslint issues) are just suggestions you can ignore if you want.
| preUploadErrorMessage.value = null; | ||
| try { | ||
| if (dstype !== 'zip') { | ||
| // eslint-disable-next-line @typescript-eslint/no-use-before-define |
There was a problem hiding this comment.
Sorry can we do this one too? I don't know why these got in here, I'm sure there was a reason.
| const openImport = async (dstype: DatasetType | 'zip') => { | ||
| const ret = await openFromDisk(dstype); | ||
| if (!ret.canceled && ret.fileList) { | ||
| // eslint-disable-next-line @typescript-eslint/no-use-before-define |
| gc.sendRestRequest( | ||
| "PUT", | ||
| f"/item/{str(itemId)}?name={item['name']}&folderId={str(created_folder['_id'])}", | ||
| json=metadata, | ||
| ) |
There was a problem hiding this comment.
I think this PUT and the metadata update should happen just before the directory upload instead of after it.
As is, you could end up in a loop where stuff keeps getting uploaded, but the zip never moves or has its metadata updated, if, for example, an exception is encountered during upload. In a worst case, this could just run over and over until disk fills up.
Then, if there's a problem, the celery task will report that it failed and it won't be able to run again.
|
Importing Zip File Exports: background: Logic:
Erroring:
|
|
Edit: I agree with the approach, below comments kept as record. I'm not totally sure we want to duplicate possibly fragile logic here in the worker task.
I think it'd be better to try and make this function as dumb as possible, leaving the decision making to postprocess where all the hard decisions about what to do with a folder full of unmarked files is already handled. Once you know you're dealing with an export (meta.json is present) you can just push everything to the server and make the server deal with it. Postprocess could even pick the dataset type based on what it finds so the worker doesn't need to open the meta file at all. The thing I'm mostly guarding against here is having one logical path mimic the private behavior of another, because that puts a lot of burden on us to remember that we did that. |
16b9f3c to
99b8b1a
Compare
|
Okay since the last review:
Let me know if I've been too accommodating to the point of fragility and if I should dial back some of the support (multi-folder). |
subdavis
left a comment
There was a problem hiding this comment.
There are a few more minor nits here, and one more open ended concern.
I tested with a zip file that extracts to a sub folder (IMO, most correct zip folders should not tarbomb, so I try to make zip files that contain a single sub-folder like this).
It didn't work, and I'm not sure if it is supposed to from looking at the code, but I sorta think it should?
Fetching input from 61c0a108ac730287a6f624a8 to /tmp/tmp1cc2rnha/sub_cf2e010daaf375e60dc7728ee74a683f#201106161330_8.zip...
Extracting: sub_cf2e010daaf375e60dc7728ee74a683f#201106161330_8/tmp5p6l0nzv.mp4
Extracting: sub_cf2e010daaf375e60dc7728ee74a683f#201106161330_8/result_04-04-2021_01:55:13.json
Extracting: sub_cf2e010daaf375e60dc7728ee74a683f#201106161330_8/output_tracks.csv
Message: No supported media-type files found
Invalid state transition to '3', Current state is '4'.
Also, that invalid transition exists because you shouldn't use JobStatus.ERROR directly in a celery task. You should just raise an exception and let girder worker catch it and do the transition for you.
See examples in other tasks where I raise Exception. You could also do RuntimeError -- I haven't been that consistent.
| # only support first zip file found | ||
| return dsFolder |
There was a problem hiding this comment.
This early return makes me a little uneasy. In the case were other files were found, there's sort of an undefined behavior where you aren't sure if there were other items in the folder that just got ignored, which other functions like download/export may encounter and either erroneously return or error on. It also doesn't give process_items the opportunity to run, which I think it should be allowed to do even though it's a no-op.
I think I'd prefer an error condition here, where you convert the cursor to a list, assert that its length is at most 1, and otherwise throw a 500 error (because at this point, the server is in an invalid state and there is no automated intervention that can fix the folder).
And if there are zipItems, I think you need to check that Folder().childItems() also returns a single item and throw an error otherwise.
|
|
||
| @pytest.mark.integration | ||
| @pytest.mark.parametrize("user", zipUser.values()) | ||
| @pytest.mark.run(order=4) |
There was a problem hiding this comment.
Because these are all order 4, you don't know what order they'll run in. It may be an accident that these tests work. Do you know if order here is guaranteed?
There was a problem hiding this comment.
It seems it would be better to match up user creation, data reset and upload with the other ordering for other tests.
| # validation of files in folder using dive/data | ||
| created_folder = gc.createFolder( | ||
| folderId, | ||
| constants.SourceFolderName, | ||
| reuseExisting=True, | ||
| ) | ||
| gc.sendRestRequest( | ||
| "PUT", | ||
| f"/item/{str(item['_id'])}?folderId={str(created_folder['_id'])}", | ||
| ) |
There was a problem hiding this comment.
Does this comment go with these lines? Seems like this is moving the zip to source, but the comment says otherwise.
There was a problem hiding this comment.
yeah, I must have moved stuff around and forgot about the comment.
Co-authored-by: Brandon Davis <brandon.davis@kitware.com>
8e97943 to
024d0c1
Compare
|
I think #1099 is needed for this to work as expected. |
* Arbitrary depth support for imports * Respond to comments
fixes #1033
Initial version of minimum viable product with basic functionality for uploading a zip containing flat list of media files and then running a post process on them to create a working annotation dataset.
Completed:
ZipFileExtractedMarkermarker on it and will kick off a task to extract the zip file. On subsequent calls it will ignore the zip files which have this marker preventing zip files from being extracted multiple times.dive_dataset/validate_filesendpoint.ZipFileExtractedMarkeradded to it and thedive_rpc/postprocessendpoint is called once again to perform any transcoding.dive_rpc/postprocesswill also move any zip files that have been processed into asourcefolder to keep the root of the dataset directory clean.