Additional zero_grad and backward being performed when using IPU #12903
Description
🐛 Bug
When training on the IPU, the zero gradients and backward pass are compiled into the IPU program. This means that instead of:
for batch, target in training_data:
# Zero gradients
optimizer.zero_grad()
# Run model.
_, loss = model(batch, target)
# Back propagate the gradients.
loss.backward()
# Update the weights.
optimizer.step()You would use:
for batch, target in training_data:
# Performs forward pass, loss function evaluation,
# backward pass and weight update in one go on the device.
_, loss = poptorch_model(batch, target)However, when closure() is executed in optimizer_step(), both self._zero_grad_fn() and self._backward_fn(step_output.closure_loss) are still being executed. This is leading to duplicate work and decreased throughput performance.
To Reproduce
repro.py
import torch
import poptorch
import pytorch_lightning as pl
import torch.nn.functional as F
from torchvision import datasets, models
from torchvision.transforms import ToTensor
from pytorch_lightning.strategies.ipu import IPUStrategy
class Model(pl.LightningModule):
def __init__(self):
super().__init__()
self.model = models.resnet18(pretrained=False)
def forward(self, x):
return self.model(x)
def training_step(self, batch, batch_idx):
x, y = batch
y_hat = self.model(x)
loss = F.cross_entropy(y_hat, y)
return loss
def configure_optimizers(self):
return torch.optim.Adam(self.parameters(), lr=1e-3)
def main():
batch_size = 32
# data
mnist = datasets.FakeData(
size=100 * batch_size,
image_size=(3, 28, 28),
num_classes=10,
transform=ToTensor(),
)
opts = poptorch.Options()
train_loader = poptorch.DataLoader(
options=opts,
dataset=mnist,
batch_size=batch_size,
drop_last=True,
mode=poptorch.DataLoaderMode.Async,
)
# model
model = Model()
# training
trainer = pl.Trainer(
accelerator="ipu",
precision=16,
max_epochs=1,
strategy=IPUStrategy(training_opts=opts),
)
trainer.fit(model, train_loader)
if __name__ == "__main__":
main()Expected behavior
self._zero_grad_fn() and self._backward_fn(step_output.closure_loss) should not be executed in closure().
Environment
- Packages:
- poptorch
- pytorch-lightning==1.6.1
- torch @ https://download.pytorch.org/whl/cpu/torch-1.10.0%2Bcpu-cp37-cp37m-linux_x86_64.whl
- torchvision==0.11.1
- System:
- OS: Linux
- architecture:
- 64bit
- ELF
- processor: x86_64
- python: 3.7.5
- version: 18.04.1-Ubuntu SMP Wed Sep 29 10:59:42 UTC 2021
Additional context
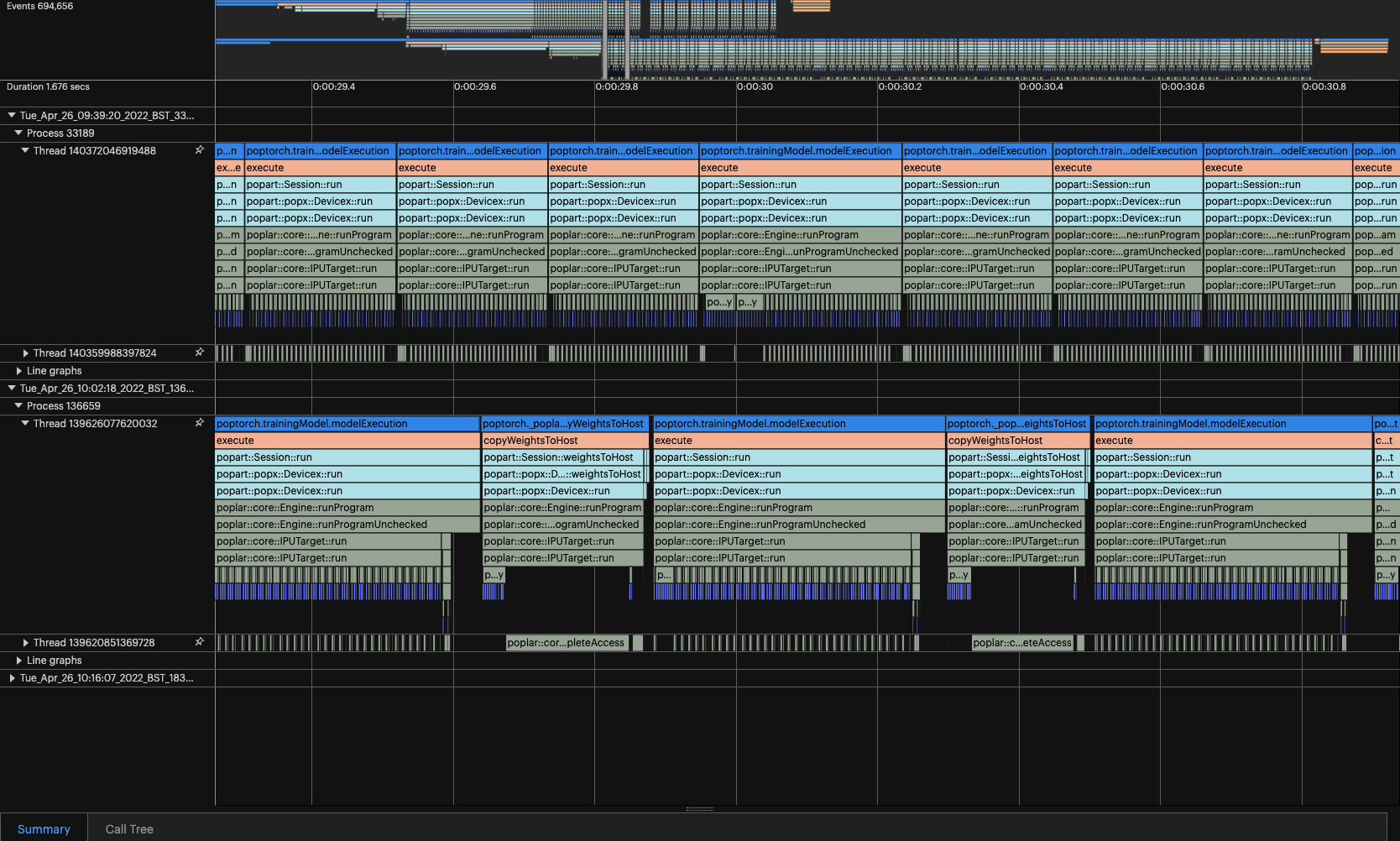
In the following profile (top: PyTorch , bottom: PyTorch Lightning) the copyWeightsToHost are from the additional zero gradients, and I believe (but have not confirmed) that the extra execution time is due to the additional backward pass.
cc @SeanNaren