Diversas aplicações necessitam armazenar valores em uma estrutura de lista, e procura-los em um menor tempo possível , como também em um menor custo para tornar o algorítmo mais eficiente , assim melhorando o funcionamento dos servidores e do fluxo do back-end de algum programa em funcionamento.
Por exemplo, um banco de dados que armazena diversos CPF's:
cpflist = list()
while True:
cpflist.append(input())
print(cpflist)
#For Example:
cpflist = [000.000.000.01,111.111.111.2,888.888.888.88,111.111.111.11 ...]
Em um cenário realista , qualquer empresa moderna necessitaria de um algoritmo eficaz e rápido , que procurasse o cpf de um usuário que foi cadastrado anteriormente para retirar informações importantes desse usuário para o uso futuro.
Porém , imagine uma lista em que possui mais de 10 milhões de CPF's cadastrados. Será que o custo seria baixo ? caso o CPF a ser encontrado fosse o último da lista?
O custo linear seria O(n) , o que leria os 10 milhões de CPF's até encontrar o desejado , ou seja , iria demorar BASTANTE para executar esse processo.
Existem diversos tipos de algoritmos de busca de dados: Linear Search , Binary Search , Jump Search , Interpolation Search , Exponential Search , Sublist Search , Fibonacci Search , The Ubiquitous Binary Search
Aqui , serão apresentados os algoritmos de busca binária e busca sequencial , comparando-os em relação ao funcionamento e ao custo , e o que vale mais a pena ultilizar nos piores casos e mais realistas possíveis.
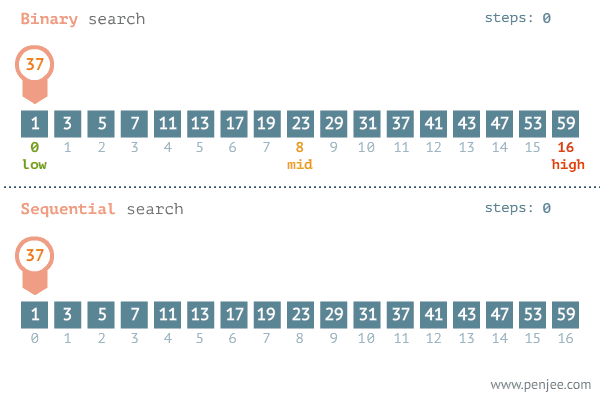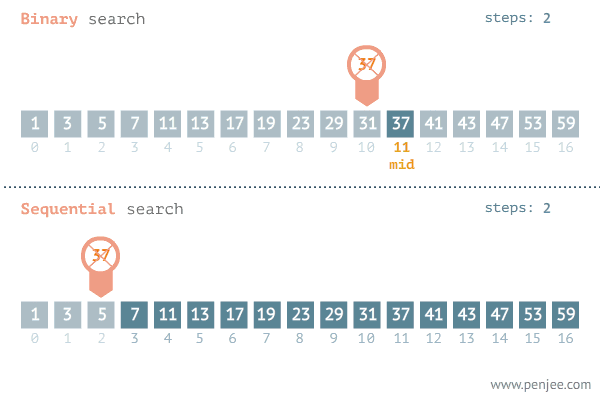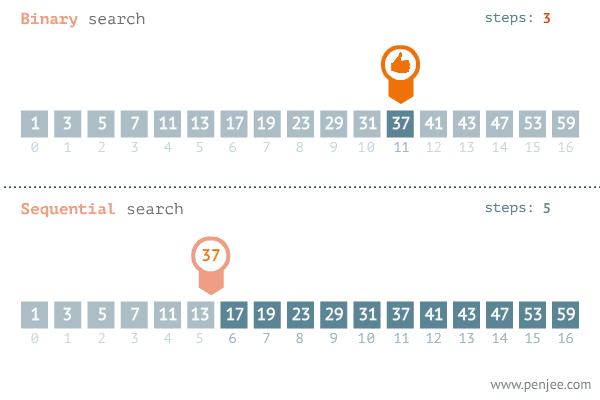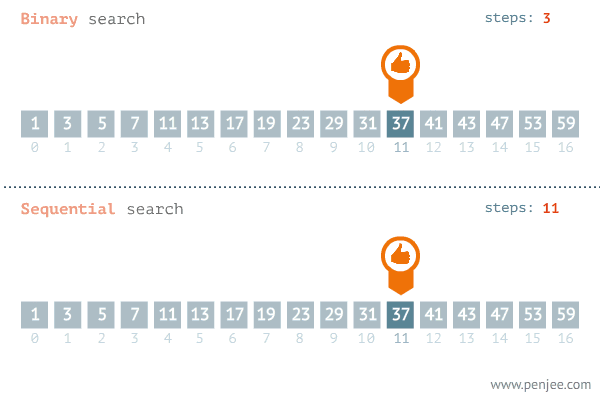
A pesquisa sequencial é um dos métodos mais simples para encontrar um elemento específico em um conjunto de dados. Ele começa a verificar desde o início do conjunto de dados e cada item de dados é verificado até que uma correspondência seja feita ou até o final do conjunto de dados. O algoritmo parará de pesquisar se encontrar uma correspondência. Se não houver correspondência, o algoritmo não retornará nenhuma mensagem de pesquisa encontrada.
É amplamente utilizado para pesquisar um elemento da lista não ordenada, ou seja, a lista na qual os itens não estão ordenados. Sendo uma grande vantagem em relação a busca binária
A complexidade de tempo do pior caso da busca linear é O(n).
A pesquisa binária segue a técnica de dividir e conquistar em que a listagem é dividida em duas metades e o item é comparado com o detalhe do meio da listagem. Se a correspondência for encontrada, a localização do elemento ou seja, o elemento do meio será retornado.
A busca binária é uma técnica de busca rápida que tem uma complexidade de tempo de Ο(log n). Para o bom funcionamento do algoritmo, os elementos devem ser ordenados em ordem crescente ou decrescente.
O problema é:
se o algoritmo de Busca Binária tem o custo O(log n) , porém só funciona com a lista ordenada de modo crescente ou decrescente , e se a busca linear possui um custo de O(n) e não precisa ordenar , qual vale mais a pena utilizar para casos diários de necessidade de pesquisas em banco de dados?
Para isso , implementei um código utilizando o Quick Sort , para medir a complexidade do algoritmo e fiz comparações nas duas funções de busca: a sequencial e a binária
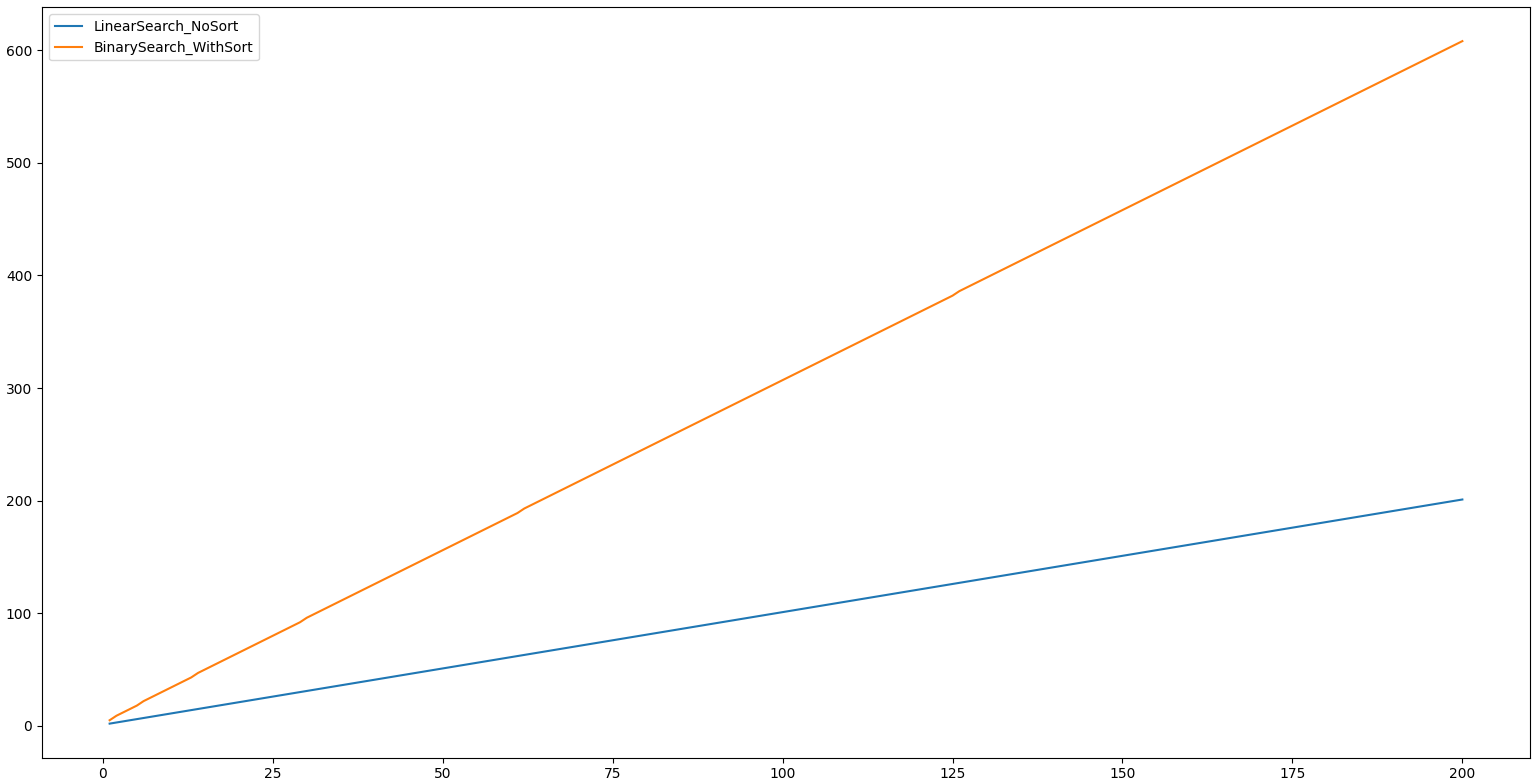
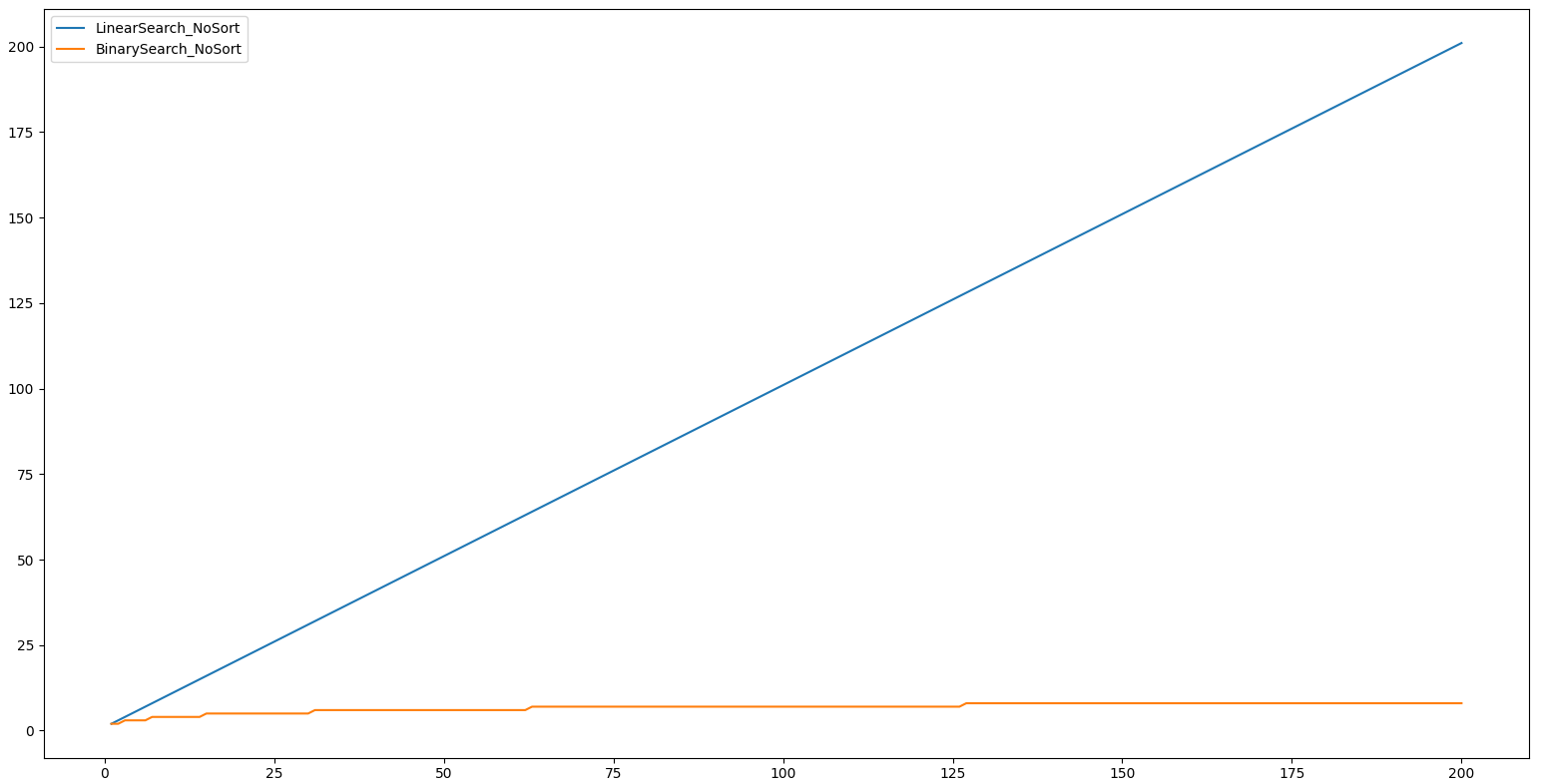
Ao comparar ambos os algoritmos, podemos dizer que para pequenos conjuntos de dados podemos usar o algoritmo de busca linear e para grandes conjuntos de dados o algoritmo de busca binária é a melhor opção , apenas quando é mencionado que a lista já está ordenada. A pesquisa binária é um algoritmo de pesquisa muito mais otimizado, mas os dados devem ser ordenados corretamente. Fora isso , em casos em que a lista está desordenada , vale mais a pena utilizar a busca sequencial.
O algoritmo de busca binária padrão não pode ser usado em uma lista encadeada porque a lista encadeada é naturalmente dinâmica e não se sabe exatamente onde a parte do meio é atribuída. Portanto, existe a necessidade de projetar uma variação do algoritmo de busca binária que possa funcionar em uma lista encadeada e porque a busca binária é mais rápida em operação do que a busca direta.
$ cd
$ cd Desktop
$ mkdir GithubRepository
$ cd GithubRepository
$ git clone https://github.com/Lipeira/datasearch-comparison.git
Fonte:
https://medium.com/interviewnoodle/linear-search-vs-binary-search-845fd09dbde3
Ferramenta: