地方跨境电商通关商品数据可视化(python脚本)
python脚本主要来处理项目中的静态Json文件和数据库里的不规则字符串,这里记录一下对不规则地址字符串的处理。
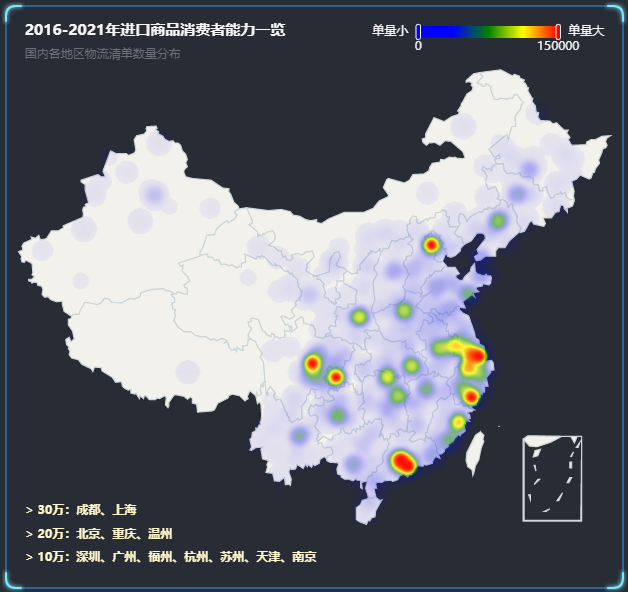
在做毕业设计时,遇到一个按市级区域统计物流清单数量的需求,但数据库里的相关数据都是在生产环境下直接入库的。由于物流清单地址字段值是由消费者填写的,地址值的格式不规则、不统一,没办法直接用来做统计。
为解决上述问题,常规的想法是使用正则表达式匹配,但数据库里实际的地址字符串没有规律,有些字段省略了“省”、“市”、“县”这些关键字,有些甚至没有写明省址或市址,那么这种方法误差率太高,不适合用于在上述问题中做提取市级行政区的操作。
在查阅资料后,找到一种基于 Python 脚本的匹配方法。
① 在数据库中导入国内省市区县数据;
② 将地址字符串分词;
③ 将所有关键词,依次同(省)市、县两级数据进行比较;
④ 先匹配全国的市级行政区,若没有匹配出市级行政区,则匹配县级行政区;
⑤ 匹配出区县后,再根据县名,查出对应的地级市
从国家民政部官网中能够查到国内最新的省市区县数据,将这些数据拷贝到excel 中,并插入数据库;然后导入 jieba 分词库来对地址字符串做分词;最后编写Python 脚本将所有的关键词依次同(省)市、县两级数据进行比较和匹配,提取地级行政区。
从国家民政部官网中将国家行政区划数据导入excel,按省、市、区录入
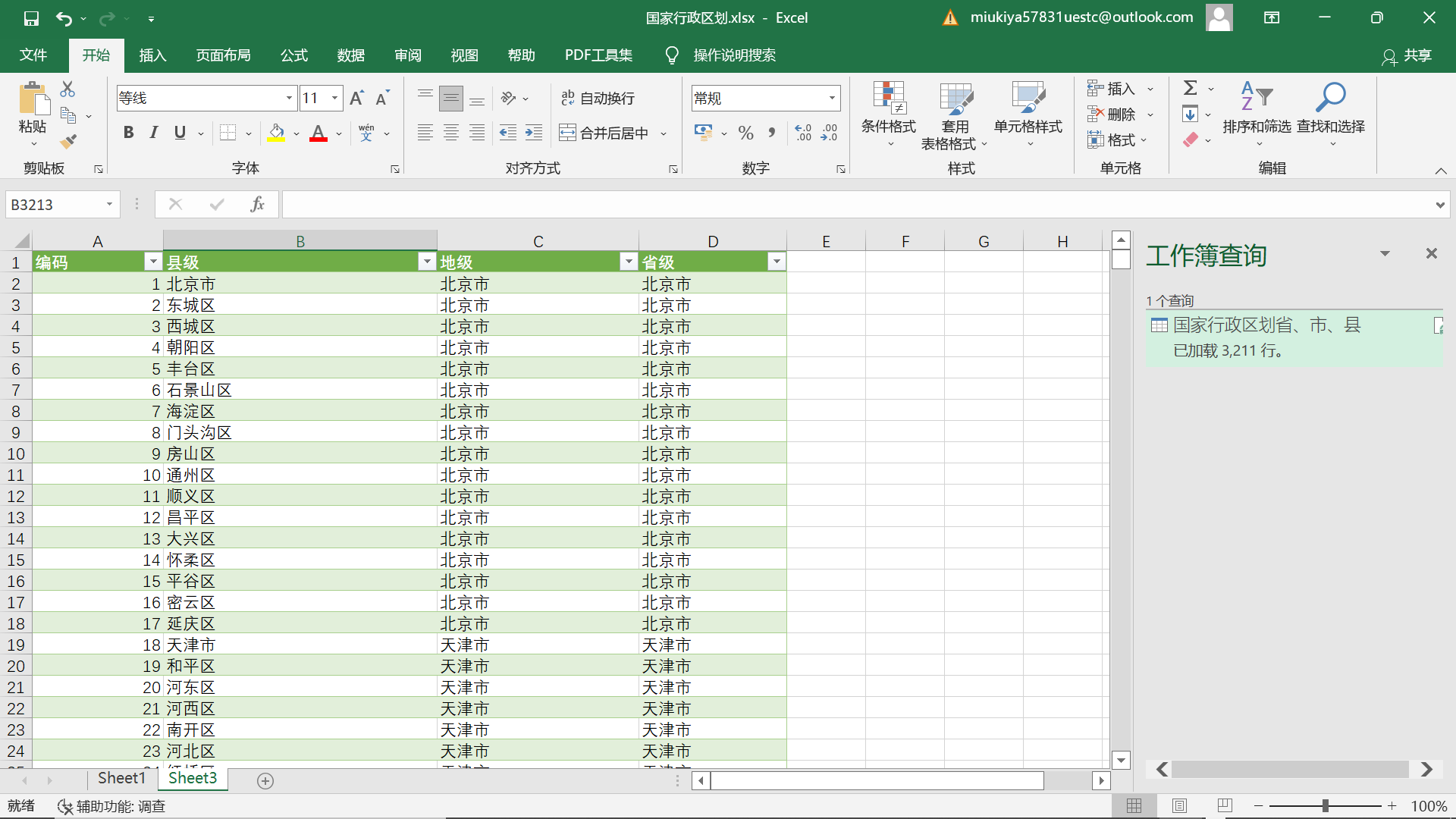
将excel表导入数据库
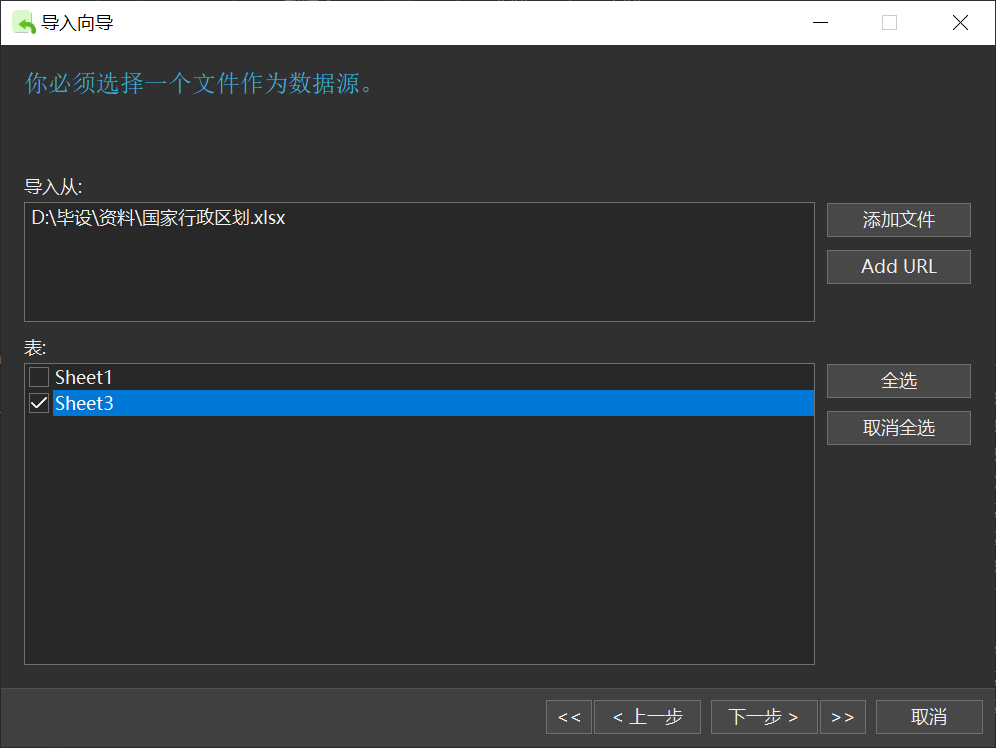

基于china_ad_division表整理出市级字典、县级字典

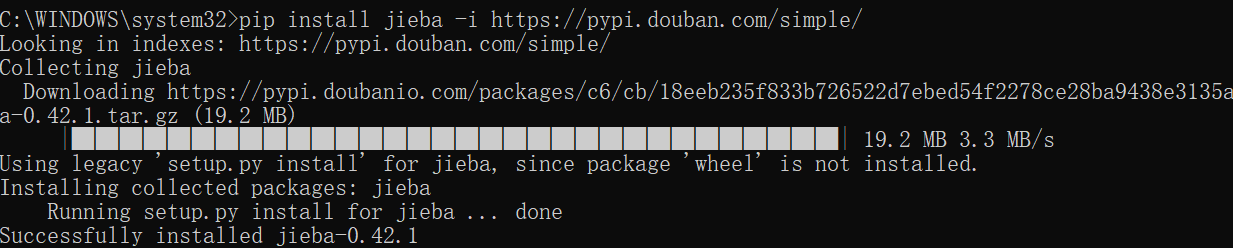
安装MySQLdb,我的Python版本是3.10,所以mysqlclient是2.1.0版本

引入MySQLdb,在该类里实现连接数据库、查询数据、提交数据处理等功能
import MySQLdb
import importlib
import sys
importlib.reload(sys)
class Mysqldb(object):
def __init__(self):
try:
# 连接数据库
self.conn = MySQLdb.connect(
host="localhost", # 主机地址
user="root", # 账号
passwd="123456",
port=3306,
db="goodsview", # 数据库名
charset="utf8",
use_unicode=True
)
# 游标对象
self.cursor = self.conn.cursor()
except Mysqldb.Error as e:
print("创建数据库连接失败|Mysql Error %d: %s" % (e.args[0], e.args[1]))
self.conn.close()
# 销毁对象
def __del__(self):
self.cursor.close()
self.conn.close()
# 查询数据库
def query(self, sql):
self.cursor.execute(sql) # 执行sql语句
data = self.cursor.fetchall()
if data:
return data
else:
return 0
# 单条数据处理提交
def execute(self, sql):
try:
self.cursor.execute(sql)
self.conn.commit() # 向数据库提交
return True
except Mysqldb.Error as e:
self.conn.rollback() # 发生错误时回滚
return False
# 多条数据处理提交
def executemany(self, sql, d_list):
try:
self.cursor.executemany(sql, d_list)
self.conn.commit()
except Mysqldb.Error as e:
self.conn.rollback()
# 生成实例
myOperationdb = Mysqldb()
该类实现用地址分词字符串匹配行政区划字典,并返回地级市名的功能。为了减少误差,这里使用jieba库的精确模式对地址信息进行分词。
注:首先匹配市级单位,没有市级单位再匹配县级单位,通过县级单位查出对应的市级单位。
import sql
import jieba
jieba.setLogLevel(jieba.logging.INFO)
def address_match(address):
# 没有参数传入返回空
if not address:
return {}
# 消除空字符串
address = address.replace(' ', '')
# 使用精确模式切分地址字符串
seg_list = jieba.lcut(address, cut_all=False)
city_item = {} # 地级市
district_item = {} # 县级
# 查市
sql_city = "SELECT city_name FROM goodsview.china_city_dic"
city_ad = sql.myOperationdb.query(sql_city)
# 按地址分词顺序进行匹配。一般市写在区前面,保证先匹配到市,减少区名与市名相同造成的误差
for key in seg_list:
# 全国地级市名独一无二,保证匹配的字符串长度大于1就能锁定地级市
if len(key) >= 2:
for item_c in city_ad:
if key in item_c[0]:
city_item = item_c[0]
break
# 匹配成功,不再匹配剩下的分词
if city_item:
break
# 查区县
if not city_item:
sql_district = "SELECT district_name, city_name FROM goodsview.china_district_dic"
district_ad = sql.myOperationdb.query(sql_district)
for key in seg_list:
if len(key) >= 2:
for item_d in district_ad:
if key in item_d[0]:
# 存储县级名称,以判断地址是否有效至县级行政区
district_item = item_d[0]
city_item = item_d[1]
break
if city_item:
break
# 如果地级、县级都没有
if not district_item and not city_item:
city_item = "该地址无效!"
address_item = city_item
return address_item
写一个执行文件,传入实参执行上面两个工具类,并更新数据库字段值
import sql
import address
sql_str = "SELECT id, address FROM goodsview.person_address"
ad = sql.myOperationdb.query(sql_str)
for row in ad:
# 调用分词模块
id_code = str(row[0])
result = address.address_match(row[1])
# 更新数据库
sql_update = "UPDATE goodsview.person_address SET address = '" + result + "' WHERE id = " + id_code
sql.myOperationdb.execute(sql_update)
原地址字段值:
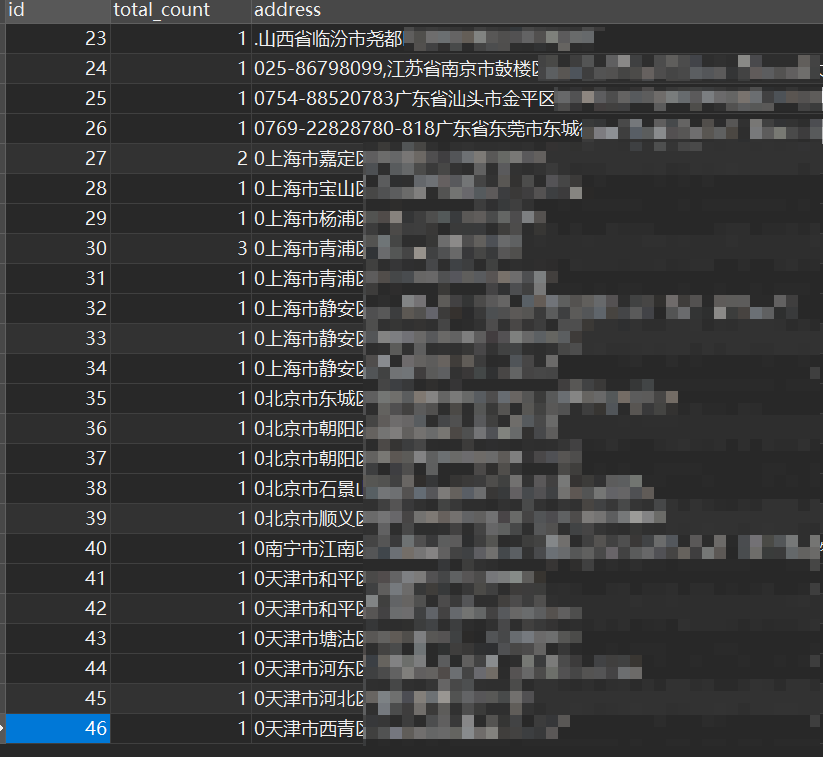
处理后的:
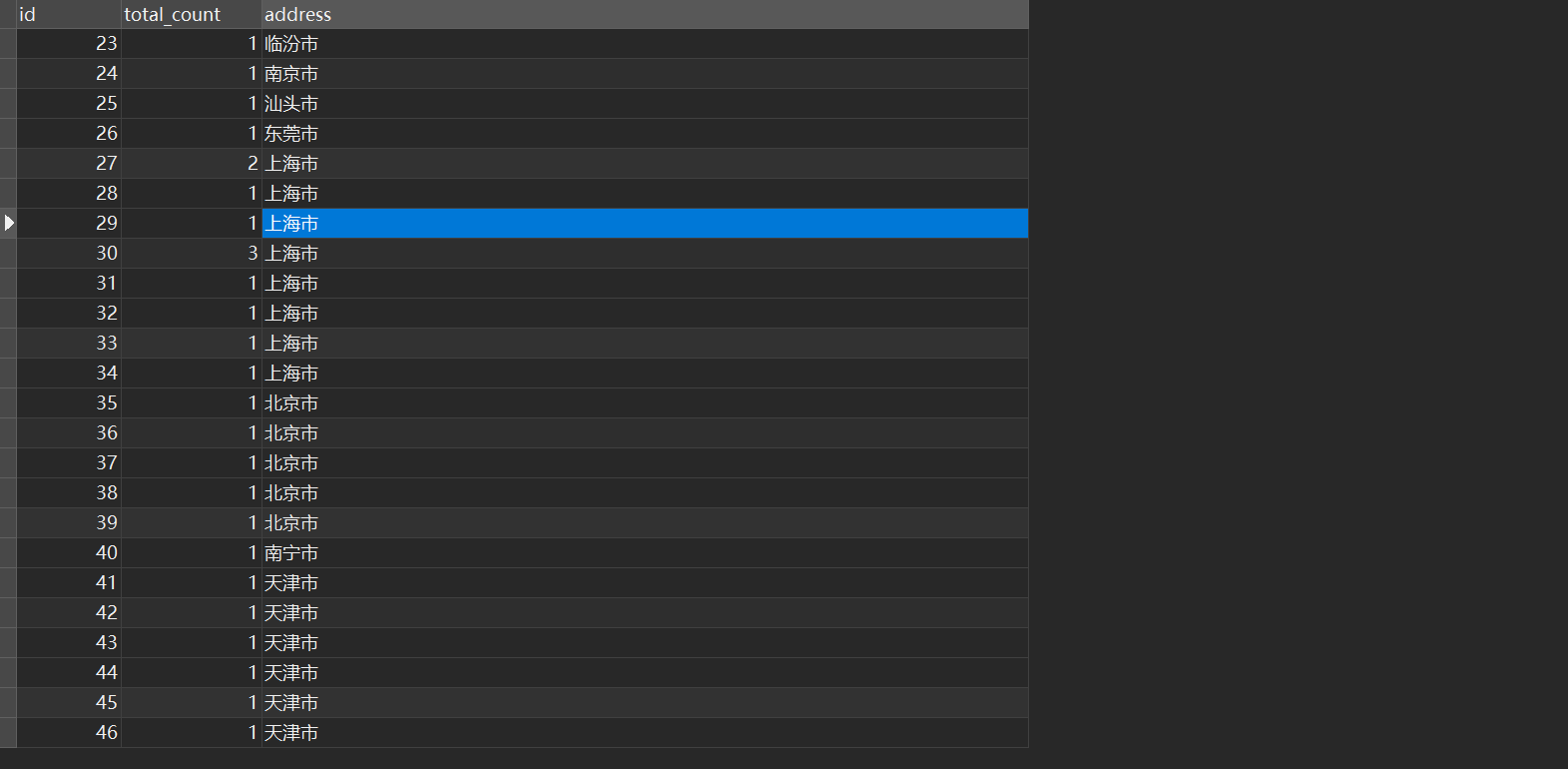
该办法只能提取地址顺序相对较整齐的字段,如按省-市-区-街道/小区、市-区-街道/小区或区/县-街道/小区这种的,不能提取个别只填了街道或小区的字段,且街道或小区名称可能和字典里的区、市名重复,提取结果存在误差,如下例:

第一条里的“水城印象小区”实际位置在成都市金堂县,然而经过市级筛查没有匹配到“成都”关键字,进入县级筛查后字符串“水城”与六盘水市辖区下的“水城区”匹配上了,如下图,反馈结果就不正确:
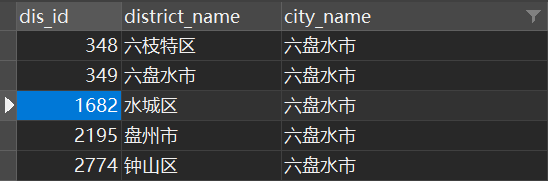
而第二条和第三条由于先捕获到了市级关键字就没有再匹配到“水城”,第四条同样实际位置在成都市,但由于“龙泉”匹配上了丽水市辖区下的“龙泉市”,系统就报出了错误的结果。
由于各地级市包含的小区、街道过多,且名称不具有唯一性,目前系统难以实现精确到各个社区的筛查,所以,通过这个方法确定清单收货地址,再计算出各市区消费清单的总量就存在一定误差,但数据库里主要的不规则地址还是遵循市-区/县-街道的顺序存入的,能够提取出有效的地级市字符串,上述情况再加上查不出来的单街道、小区地址大约不超过总量的2%(基于无效地址数量粗略估计),因此它在总体呈现各地物流单量多少的分布上还是有意义的。