feat(model): add Ling 2.0 / BailingMoeV2 (mini, flash, 1T) (#2242)#2255
Conversation
|
/ok to test a0e7913 |
|
Thank you @Hayden727 ! |
|
Hi @HuiyingLi — here is the training curve for Setup
Curve
Numbers
Convergence is clean: loss drops from ~12 to <0.5 by step 40, plateaus around 0.1, and val loss tracks train loss with no overfitting through 500 steps. Full raw stdout log (213 KB, has every step's metrics) is at: YAML changes I made before this runWhile preparing this run I caught two issues in the example YAML — both pushed to the PR branch in commit
Note on
|
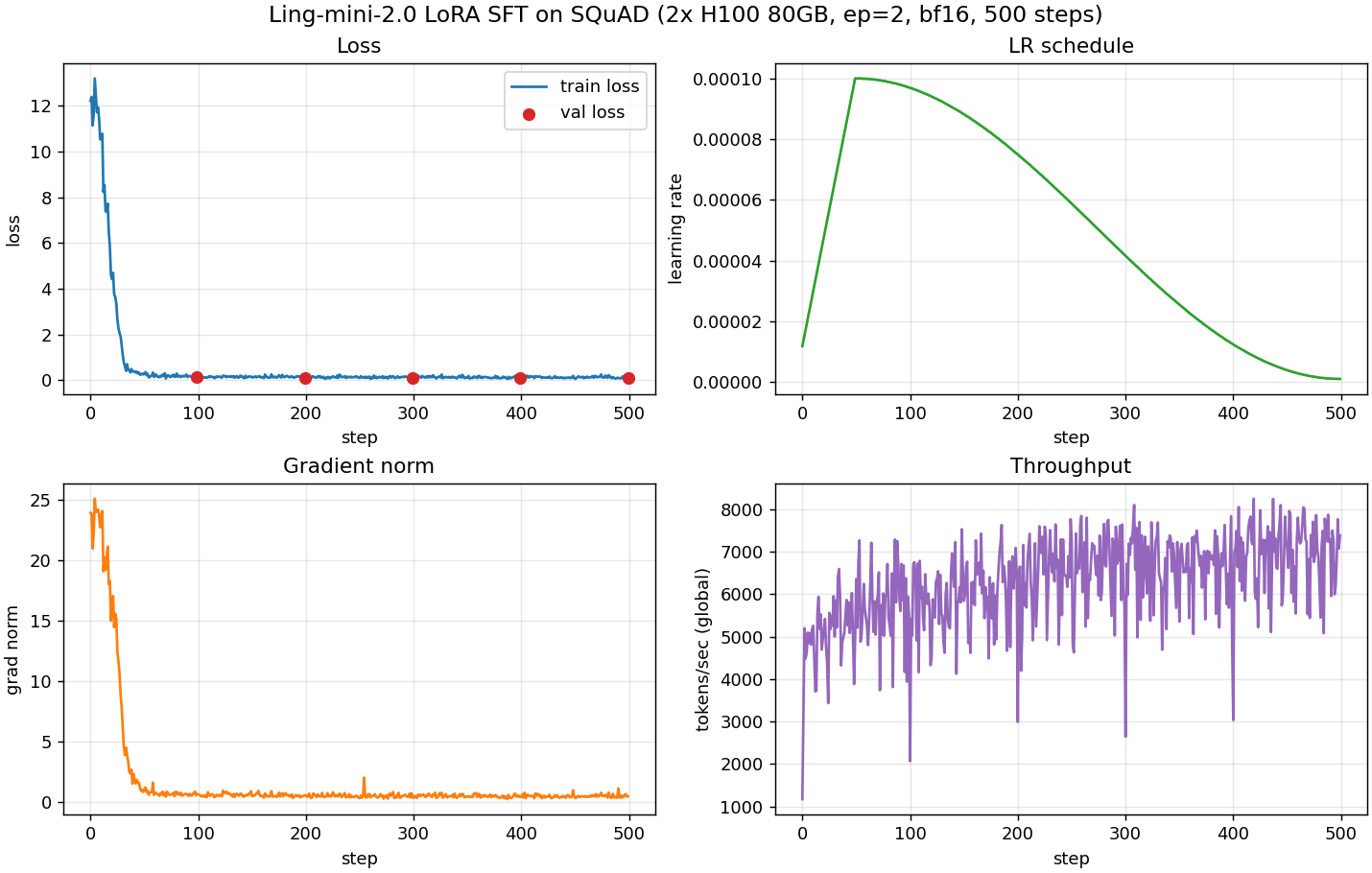
While running the recipe end-to-end on H100 to produce the training curve requested in the PR review, three issues surfaced in the example YAML: - validation_dataset.num_samples_limit -> limit_dataset_samples (matches make_squad_dataset's actual signature; the prior name was a typo). - distributed.ep_size: 1 -> 4 (with a CLI override note). The framework's HF state-dict adapter for grouped MoE experts requires an `ep` mesh dimension; without ep_size > 1 the to_hf path asserts. - backend.attn: te -> sdpa as the default so the recipe runs in containers without TransformerEngine installed; TE remains an option via override. Also add a lr_scheduler block with the standard cosine + warmup schedule, tidy header comments to reflect tested 4-GPU layout, and gitignore local training_logs/ so plots don't leak into commits. Validation curve for this recipe is in the PR comment: NVIDIA-NeMo#2255 (comment) Signed-off-by: Hayden727 <hayden.cc@zohomail.com>
9617bbd to
67ca563
Compare
|
/ok to test 67ca563 |
 jgerh
left a comment
jgerh
left a comment
There was a problem hiding this comment.
Completed tech pubs review of .md files. No copyedits needed. LGTM.
We observe DeepEP timeout on Ling-1T SFT and LoRA runs@Hayden727 Root cause for the Ling-1T DeepEP failure: Ling-1T has
For bf16 hidden size 8192, The practical workaround is to use One additional tuning was needed for the full SFT topology. With
Setting:
reduces the HybridEP backward combine shared-memory request to about 200832 bytes, which fits under the H100 limit. So the recommended Ling-1T config is:
|
|
@Hayden727 1T ep8pp8 8nodes |


Per Huiying's runs (PR NVIDIA-NeMo#2255), DeepEP times out on Ling-1T because hidden_size=8192 crosses the intranode TMA per-warp shared-memory budget (half_hidden_bytes + 8 > 8192). Switch the two 1T recipes to dispatcher=hybridep and stamp the required HybridEP env vars on the ci.env_vars block: - ling_1t_lora_pp.yaml (64 GPUs, ep=8 pp=8): NUM_OF_HYBRID_EP_RANKS_PER_NVLINK_DOMAIN=8 - ling_1t_sft.yaml (256 GPUs, ep=64 pp=4): NUM_OF_HYBRID_EP_RANKS_PER_NVLINK_DOMAIN=8 NUM_OF_STAGES_G2S_COMBINE_API=4 # ep-group spans nodes; shrinks # backward-combine dyn-shared-mem # request under H100's 232 KiB limit Refs NVIDIA-NeMo#2255 Signed-off-by: Hayden727 <hayden.cc@zohomail.com>
|
/ok to test 97cf2b9 |
 HuiyingLi
left a comment
HuiyingLi
left a comment
There was a problem hiding this comment.
LGTM, thank you so much!
What does this PR do?
Adds support for the
inclusionAI/Ling-2.0MoE family (BailingMoeV2ForCausalLM):Ling-mini-2.0 (16B-A1.4B), Ling-flash-2.0 (100B-A6B), and Ling-1T (1T-A50B).
All three variants share the same architecture and are handled by a single implementation.
Closes #2242.
Changelog
nemo_automodel/components/models/ling_v2/withBailingMoeV2Config,BailingMoeV2ForCausalLM, attention layer (GQA + per-head QK-RMSNorm + half RoPE), and state-dict adapter (HF↔native).BailingMoeV2ForCausalLMarch andbailing_moecustom config innemo_automodel/_transformers/registry.py.Gate(DeepSeek-V3-style) — no new MoE routing code.gpt_oss/rope_utils.py'spartial_rotary_factorsupport — no new RoPE code.partial_rotary_factorfromrotary_dimwhen present (Ling-1T usesrotary_dim=64; mini/flash usepartial_rotary_factor=0.5).examples/llm_finetune/ling/ling_mini_2_0_squad.yaml.docs/model-coverage/llm/inclusionai/ling-2.md.tests/unit_tests/models/ling_v2/parity_ling_v2.py) implementing the 3 levels from the parity-testing skill, plus a single-GPU real-checkpoint smoke (_real_forward_smoke.py).Validation
Run inside
nvcr.io/nvidia/nemo-automodel:26.04on a single H100 80GB:first_k_dense_replace=4and therotary_dim→partial_rotary_factorderivation).inclusionAI/Ling-mini-2.0checkpoint: 14813 HF tensors → 299 grouped native → 14813 HF, zero diff.max_diff=0,cos=1.0.load_state_dictreportsmissing=0 unexpected=0, GPU memory 32.5 GB (matches bf16), logits finite, top-1 argmax shows 22 distinct tokens over 32 positions (non-degenerate).tests/unit_tests/_transformers/suite (366 tests): no regression.tools/lint_example_yamls.py(the CI validator that runs invalidate-recipe-configs.yml).modeling_bailing_moe_v2.pyimportsis_torch_fx_availablewhich was removed intransformers>=5. To be revisited once upstream Ling patches that or via atransformers<5shim.Before your PR is "Ready for review"
Pre checks:
Additional Information
/ok to test <full-sha>socopy-pr-botcan run CI.