[SSD/Tensorflow] Super slow training on COCO when switching from resnet50 to mobilenet_v2 backbone #547
Description
Hi all,
I was able to replicate the results on COCO with 4 V100 GPUs using ssd320_full_4gpus.config, with mAP=0.28. Training is also quite fast as stated. Please find a training screenshot below.

However, when I switched to ssdlite_mobilenet_v2_coco.config, training is super slow as below, even slower than using 1 GPU.
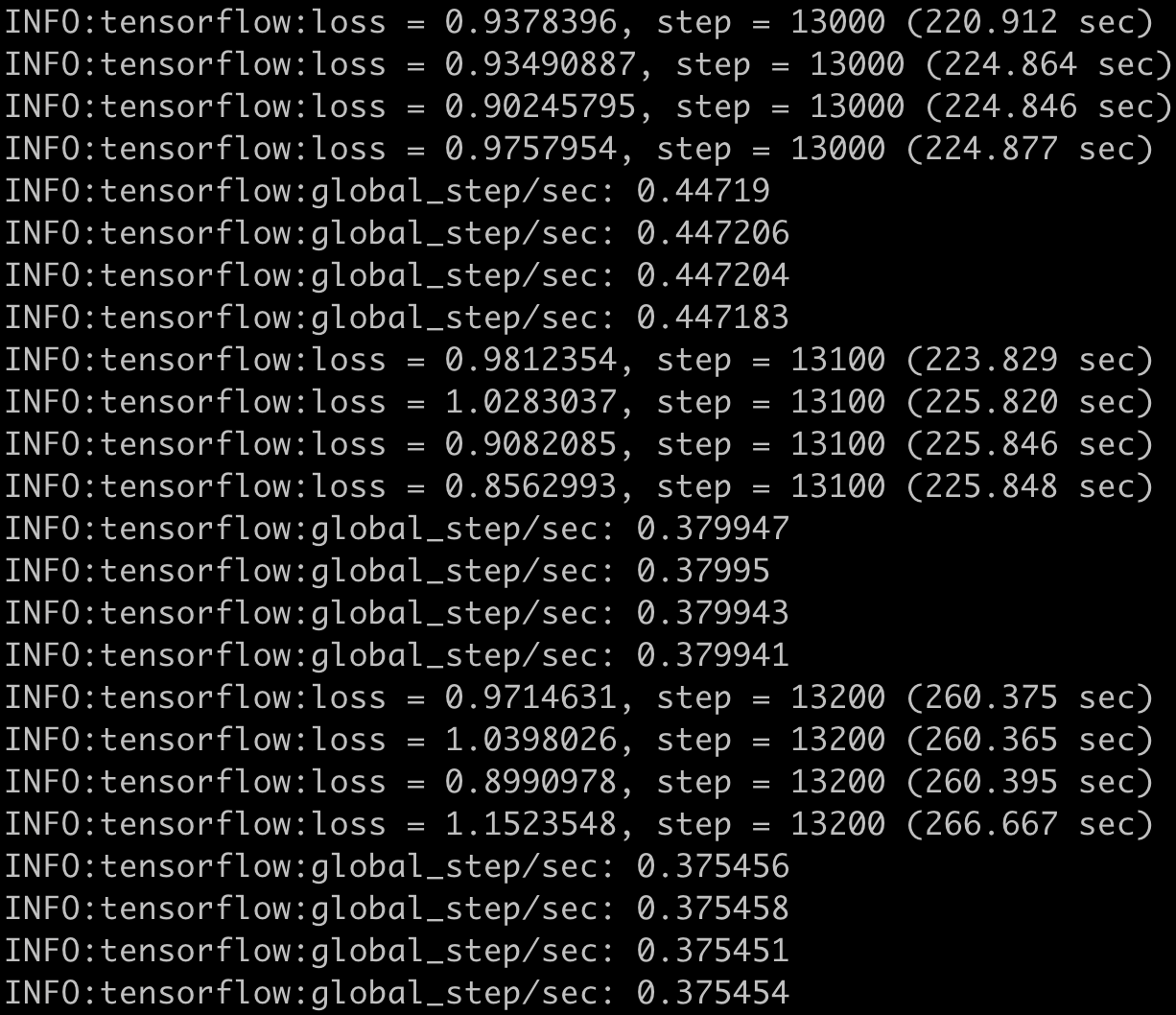
As illustrated in the screenshots, there were 8 threads spawn when training with the default config, while there were only 4 threads spawn when training with the new config.
What's more strange is that with the new config, the whole computer/instance is frozen, while for the default config, I can still perform coding or other tasks seamlessly.
I am wondering why this is happening? I checked the codes and it doesn't seem like there's anything special binding to retinanet related codes.
Environment
I'm using the provided Dockerfile:
- nvcr.io/nvidia/tensorflow:19.05-py3
- GPUs in the system: 4x Tesla V100-SXM2-16GB
- CUDA driver version: 440.82
Thank you very much!
Regards,
thoang3