Pause the task queue across the entire Octopus Server cluster #3703
Description
When you've queued a lot of deployments, and something starts going wrong, it is very hard to "stop the world" so you can pause, think, fix problems, then continue where things left off. This is a lot more of a common situation with multi-tenant deployments. (See the linked source ticket).
In the linked ticket, something went wrong on a web server in a balanced set, but there were hundreds of deployments queued, and Octopus started churning through them as quickly as possible. The customer really needed a way to pause everything, have the chance to figure out what was going wrong, and fix it.
Workaround
In Octopus 3.x you can go to the Configuration > Nodes page and put all of the nodes into Drain Mode, or set the Task Cap for all of the Nodes to 0. This prevents your Octopus Server nodes from starting any more tasks until you disable drain mode. (This works for HA and non-HA installations)
The problem is, this feature is not very discoverable.
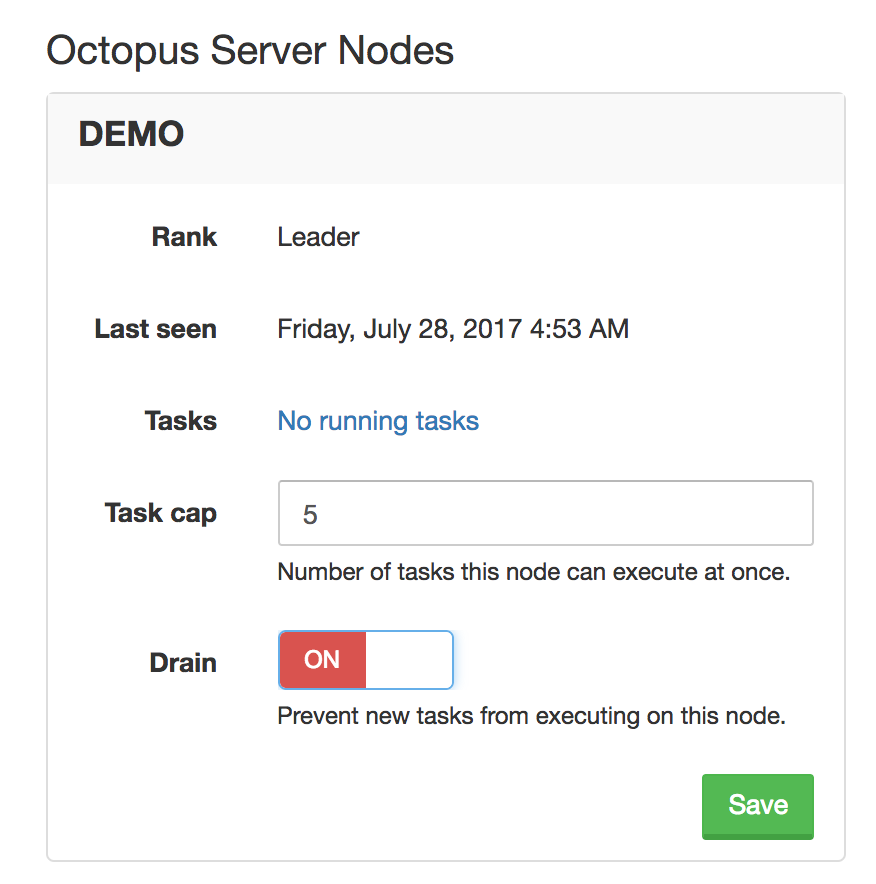
Proposed solution
We propose to add a feature to the Tasks page - if you are a system administrator, you could push a button/flick a switch to temporarily "pause the task queue" so it will not try to start anything new.
We could also add this button/switch to the Configuration > Nodes page so the same feature is available in two logical places.

What about security?
This should require the Administer System permission, similar to changing the Server Node properties.
What about tasks which are already running?
Any tasks which are already executing would continue to run to completion unless you cancel them.
We are considering another feature to let you bulk cancel tasks.
What about running an adhoc script to fix a problem whilst paused?
At some point we may want a way for high-priority tasks to "trump" this setting and execute anyhow: think about the case where you realise something is wrong, and need to run an adhoc script to fix the problem, then resume your deployments again.
This is a nice idea, but I think it's outside the scope of this particular problem.
Source
This idea was sourced from the following private support conversation: https://secure.helpscout.net/conversation/403990202?folderId=557077