{kind=link}
We often just need a specific module or function from a python package, yet we have to install the entire thing along with all its dependencies. This can easily lead to environments that weigh hundreds of megabytes, too large for a typical AWS Lambda layer, or prone to package conflicts. Developers sometimes end up digging through GitHub to manually extract only the parts they need, which can quickly turn into a messy and time-consuming process. LayerLite is here to automate package analysis and pruning.
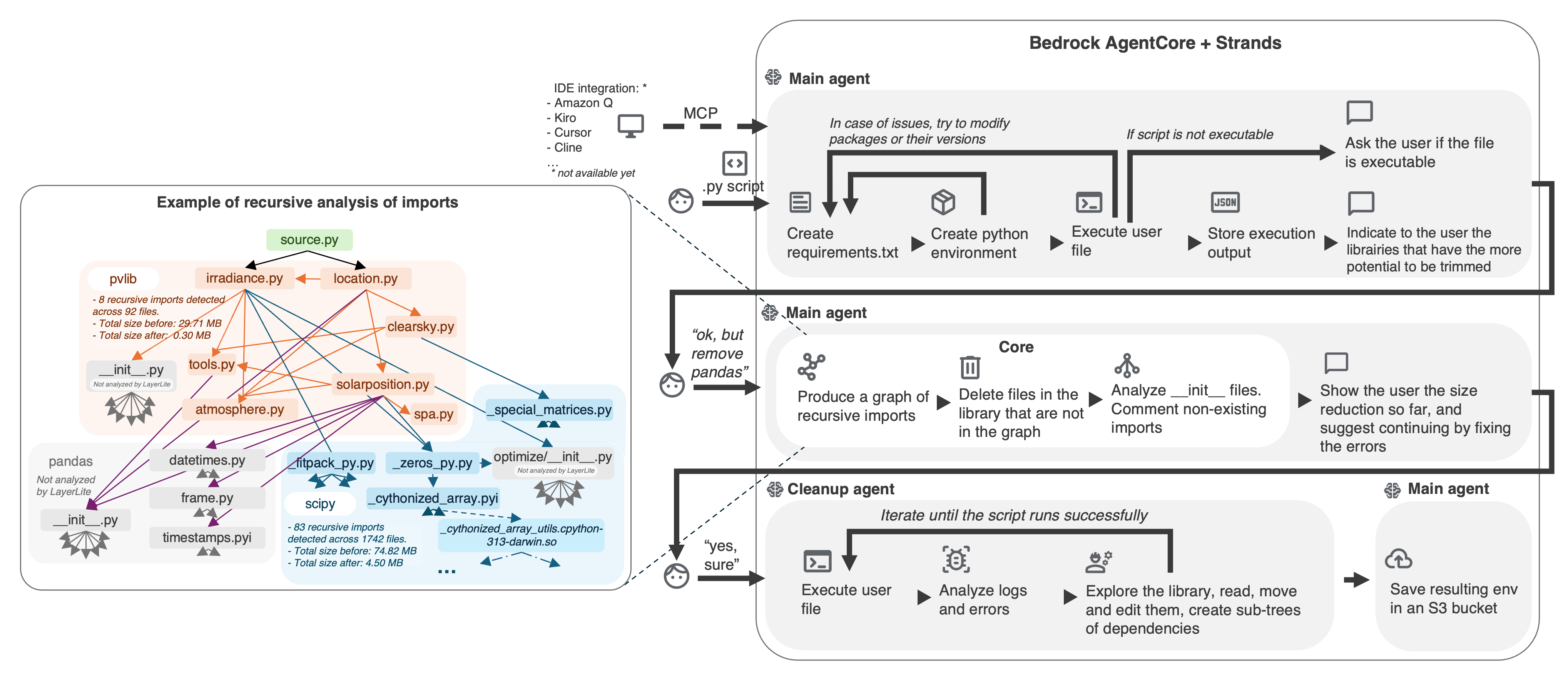
LayerLite takes a user's Python entry point and produces a minimal, production-ready environment capable of executing that file. The main agent provisions an isolated sandbox, installs just the inferred requirements, and executes the script to capture output. A static analyzer then maps the static recursive import graph, tagging every file that is actually used, including compiled extensions and data files. Unused files are stripped, __init__ modules are patched so they continue to resolve, and the result is a slim package. The environment resulting from that aggressive pruning is likely not fully functional. A specialized agent takes over, executes the user file in the pruned environment, analyzes errors, explores the package structure, restores or modifies files, produces dependency subtrees, and iterates until the user file is executable.
You can deploy the LayerLite app both locally and in an ECR repository using using CLI:
- Install requirements
pip install requirements.txt- Deploy server locally using
python layerlite.py- You can use jq to pass your python file to the agent.
jq -Rs '{prompt: .}' user_file.py \
| curl -X POST http://localhost:8080/invocations \
-H 'Content-Type: application/json' \
--data-binary @-- Deploy the server using
agentcore configure -e layerlite.py- You can use jq to pass your python file to the agent.
agentcore invoke "$(jq -Rs '{prompt: .}' user_file.py)"By default, the app uploads the generated .zip file to the layerlite-output S3 bucket.
You can change the destination by setting the LAYERLITE_BUCKET environment variable.
When running locally, the output can also be found in the layerlite_env/sandbox-env directory.
We orchestrate the workflow with Bedrock AgentCore and Strands. The main agent handles requirement discovery, environment creation, and user interactions. The core optimization loop leverages Jedi and custom AST passes. A cleanup agent repeatedly runs the user's script, analyzes errors, and edits library files until the reduced environment behaves exactly like the original. Everything runs inside disposable Python environments whose site-packages are writable.
- Balancing static analysis (fast, comprehensive) with dynamic tracing for libraries that hide behavior behind
__all__, lazy loaders, or compiled modules. - Keeping
__init__files coherent after pruning; a single commented import can cascade into runtime failures. - Managing massive dependency graphs (think
scipyandpandas) without exhausting memory, hence the tree representation and targeted cleanup. - Coordinating multiple agents when the underlying environment is not yet executable, especially before Code Interpreter can be configured.
- We initially planned to work at the module/function level, to keep exactly what is needed by the user. However, the static analysis to implement was way too complex, and we had to rely on heavy runtime analysis and LLM assistance at various steps of the process, which makes it very slow for an agent to handle when there are hundreds of files.
- We wanted to use Code Interpreter to make modifying library source files easier. However, the fact that we can’t easily configure a Python environment before using Code Interpreter makes this difficult.
- As of late 2025, no robust graph builder for Python libraries seemed to exist. The most capable open-source static analysis library we found is Jedi, yet it has some downsides: no clean handling of wildcards or compiled files, some complex resolutions fail, and stub analysis can be unpredictable. We managed to produce a clean tree structure that can probably be reused in other projects, even non-AI ones.
- Optimizing a solar irradiance calculator for Paris showcased a really positive impact: the original 195 MB environment, driven largely by
scipy,pvlib, andpandas, shrank to 109 MB. The agent produced a visual map of 83 recursive imports, highlighted dead branches, and delivered a reproducible bundle that cold-started twice as fast.
- Python dependency analysis is more complex than it may appear, and the most powerful analysis tools (Pylance, PyCharm PSI) are not open source. Static analysis still misses many runtime events.
- The complexity of adjusting pruned libraries is a good exercise for non-SOTA LLMs: models such as Nova can manage to produce a functional environment, but need more time and more tool calls than very powerful models such as Claude Sonnet.
Future improvements:
- Function/Module-level slicing to keep only the symbols a script truly touches, not just the files.
- Automatic conflict resolution when a new library breaks an existing environment, reusing the same graph insights to suggest fixes: We can pull the two (or more) versions of the conflicting library, and the agent can analyze the difference and implement a "compatibility interface" for functions/modules, extract the needed function from one version, etc.
- Broader language support and clever deeper heuristics for non-Python assets (data such as .json or .csv, compiled data such as .so or .pyd), reducing the need for manual agent interventions.
- Tool efficiency improvements by analyzing outputs of previous executions.