| title | ML Debug Env | |||||
|---|---|---|---|---|---|---|
| emoji | 🐛 | |||||
| colorFrom | indigo | |||||
| colorTo | purple | |||||
| sdk | docker | |||||
| pinned | true | |||||
| app_port | 8000 | |||||
| tags |
|
Meta × PyTorch × Scaler OpenEnv Hackathon — April 2026
Every ML engineer knows this moment. Your training job fails. You open the terminal and see:
Training job crashed. No epochs completed. Exit code 1.
No code. No traceback. Just that one line.
Current AI debugging benchmarks hand the agent the full broken script and say "fix this." That is not how debugging works. Real engineers have to investigate — run the code, read the output, check the gradients, form a hypothesis, and only then commit to a fix.
We built an RL environment that puts an AI agent in exactly that situation.
ML Debug Env is a partially observable reinforcement learning environment where AI agents debug broken PyTorch training scripts — using diagnostic tools, not oracles.
The agent starts every episode completely blind. It receives one line. It has five tools and five steps to figure out what went wrong and fix it. Every tool call costs a step. Fix it in two steps and earn a 1.2× efficiency bonus.
This forces the agent to think before it acts — the same way a real engineer does.
Themes addressed:
- Theme 3.1 — World Modeling / Professional Tasks: The agent models real ML debugging workflows, using tools the same way a human engineer would
- Theme 4 — Self-Improvement: Training runs exposed environment bugs, which we fixed, which improved training — a recursive self-improvement loop
The untrained agent receives its first alert:
"Training job crashed immediately. No epochs completed. Exit code 1."
It has no code. No traceback. Just a failure message and 5 steps.
It calls view_source immediately — brute force. Gets the full script. Pattern-matches to a fix. Scores 0.20. It got the bug type wrong.
Reward: 0.024 average. Run 1, step 1.
During training, something unexpected happened. The agent kept failing shape_mismatch fixes that looked correct. We investigated — our grader had a bug. It was giving partial credit to fundamentally wrong fixes. The agent found the exploit before we did. It was gaming the reward function, not learning to debug.
The agent was right. Our environment was wrong.
We fixed the grader. The environment improved itself because of what the agent revealed.
By step 150 of Run 2, something changed. The agent stopped calling view_source first. Instead:
run_code— see what crashesinspect_gradients— check if gradients are exploding- Fix — without ever viewing the source
The inspection strategy emerged from reward signal alone. We never told it to do this.
This is what RL is supposed to do — teach a model to behave in ways we didn't explicitly program.
{
"alert": "Training job failed. Final loss: nan.",
"available_tools": ["run_code", "get_traceback", "inspect_gradients", "print_shapes", "view_source"],
"step_budget": 5
}No source code. No traceback. No hints. The agent must decide what to investigate, in what order, within a 5-step budget.
Most debugging benchmarks hand the agent the full broken script. That removes the hardest part of real debugging — figuring out where to look. By withholding the source code, the agent is forced to develop an investigation strategy. It has to decide: given this one-line alert, what tool do I call first? That decision — and the sequence of decisions — is what gets learned through training. By Run 2, the agent had learned that run_code output alone is usually enough to diagnose a crash, and that calling view_source wastes a step.
Inspect — call a diagnostic tool (costs 1 step):
{"action_type": "inspect", "tool_name": "inspect_gradients"}Fix — submit a complete fixed script (costs 1 step):
{
"action_type": "fix",
"bug_type": "gradient_not_zeroed",
"diagnosis": "optimizer.zero_grad() missing — gradients accumulate across batches causing NaN by epoch 2",
"fixed_code": "import torch\n..."
}| Tool | What it returns |
|---|---|
run_code |
Runs the buggy script in subprocess, returns stdout + stderr |
get_traceback |
Full Python traceback if the script crashed |
inspect_gradients |
Injects gradient norm logging, returns per-layer norms after one batch |
print_shapes |
Injects forward hooks, returns tensor shapes at each layer |
view_source |
The full buggy source code |
inspect_gradients and print_shapes are the clever ones — they inject diagnostic code into the buggy script before running it, so the agent gets deep introspection without ever seeing the source. The agent decides which tools to call and in what order. That strategy is what it learns.
┌─────────────────────────────────────────────────────────────────────┐
│ SELF-IMPROVING LOOP │
│ │
│ ┌──────────────┐ ┌─────────────┐ ┌──────────────────────┐ │
│ │ Bug Generator │───►│ Agent │───►│ Subprocess Grader │ │
│ │ 8 tasks │ │ (Qwen2.5 │ │ runs fixed code │ │
│ │ 3 variants │ │ 1.5B+LoRA) │ │ AST checks │ │
│ │ seeded RNG │ │ │ │ LLM judge │ │
│ └──────────────┘ └──────┬──────┘ └──────────┬───────────┘ │
│ │ │ │
│ alert only reward │
│ no code 0.01→0.99 │
│ │ │ │
│ └──────────┬───────────┘ │
│ ▼ │
│ ┌────────────────────────────────────┐ │
│ │ Adversarial Scheduler │ │
│ │ tracks weak tasks → serves 70% │ │
│ │ with novel seeds → harder over │ │
│ │ time as agent improves │ │
│ └──────────────┬─────────────────────┘ │
│ ▼ │
│ ┌────────────────────────────────────┐ │
│ │ GRPO Training Loop │ │
│ │ Qwen2.5-1.5B + LoRA (4bit r16) │ │
│ │ custom loop · Unsloth · T4 GPU │ │
│ └────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────────────────┘
Episode flow: reset() → alert only, no code → inspect (tool call, costs 1 step) → fix (code runs in subprocess, costs 1 step) → reward → GRPO update
Eight broken PyTorch scripts ranging from a beginner-level crash to an expert-level double silent bug:
| Task | Difficulty | What's broken | How it fails |
|---|---|---|---|
shape_mismatch |
🟢 Easy | nn.Linear input dim wrong |
Explicit crash |
training_collapse |
🟡 Medium | Bad learning rate → NaN loss | Silent divergence |
wrong_device |
🟡 Medium | Model on GPU, data on CPU | Explicit crash |
gradient_not_zeroed |
🟠 Medium-Hard | Missing zero_grad() |
Loss explodes silently |
data_leakage |
🔴 Hard | Normalized before train/test split | Inflated metrics, no crash |
missing_eval_mode |
🔴 Hard | No model.eval() during evaluation |
Non-deterministic metrics |
compound_shape_device |
🟠 Medium-Hard | Two bugs: shape + device | Both must be fixed |
compound_leakage_eval |
🟣 Expert | Two bugs: data leakage + missing eval mode | Both silent, no crash |
The compound tasks are the hardest. Fix one bug and miss the other: 0.60. Fix both: 0.99.
shape_mismatch — PyTorch models are chains of layers where data flows through. Each layer expects a specific input size. nn.Linear(64, 128) accepts 64 numbers and outputs 128. If the next layer is nn.Linear(64, 10) — it expects 64 but gets 128. Crash on first forward pass.
training_collapse — the model trains but never learns. Either learning rate is too high so every update overshoots and loss explodes to NaN, or the wrong loss function is used so the signal is meaningless. No crash — just a flat or diverging loss curve.
wrong_device — model is on GPU, data is on CPU. PyTorch cannot do math on tensors that live on different devices. Explicit crash: "Expected all tensors to be on the same device."
gradient_not_zeroed — in PyTorch, gradients accumulate by default. Every loss.backward() adds new gradients on top of old ones. Without optimizer.zero_grad() at the start of each batch, by batch 10 you have 10 batches of gradients stacked. Updates become enormous. Loss explodes to NaN silently — no crash.
data_leakage — you normalize your data (subtract mean, divide by std) before splitting into train and test sets. The normalization used test data statistics. Your model appears to get 96% accuracy but it cheated — the test data was already visible during preprocessing. In real deployment it would fail. No crash, just suspiciously good metrics.
missing_eval_mode — PyTorch Dropout randomly zeros neurons during training to prevent overfitting. During evaluation you want deterministic results. Without model.eval(), Dropout stays active. Run evaluation twice and you get different accuracy each time.
compound tasks — two of the above bugs in one script. Both must be fixed. Fix one and miss the other: 0.60. Fix both: 0.99.
Scoring is a staircase, not binary. The agent gets credit for every step closer to the root cause:
0.01 → Wrong bug type identified
0.20 → Right type, but fixed code crashes
0.40 → Code runs, training doesn't complete
0.60 → Training completes, root cause not fixed
0.80 → Root cause fixed, success signal missing
0.99 → Perfect fix ✅
Efficiency bonus:
Fix in ≤2 steps → ×1.2
Fix in ≤3 steps → ×1.1
Fix in 4–5 steps → ×1.0
(capped at 0.99)
The grader actually runs the fixed code in a subprocess. The agent's fixed script is written to a temp file and executed with your actual Python + PyTorch installation. No pattern matching. No string similarity. The code has to work.
On top of execution reward, an LLM judge (Groq / llama-3.3-70b) scores the agent's diagnosis — root cause correctness and mechanistic explanation — adding up to 0.15 reasoning reward.
Reward went down. The grader had a bug giving partial credit to wrong fixes. The agent exploited it. We fixed the grader.
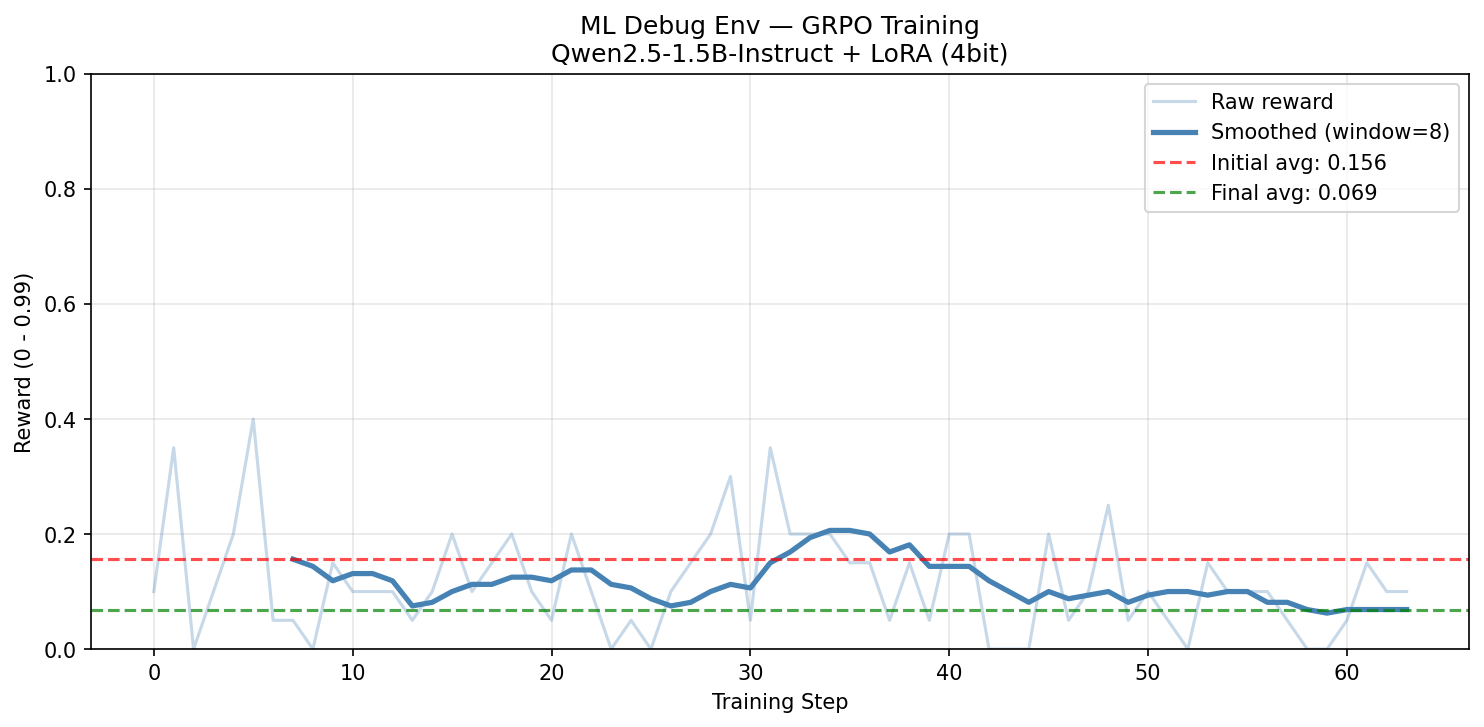 Run 1: reward trending down as agent exploits broken grader
Run 1: reward trending down as agent exploits broken grader
With the grader fixed, the agent had no shortcut. 0.024 → 0.190. 690% improvement in 200 steps on a free T4 GPU.
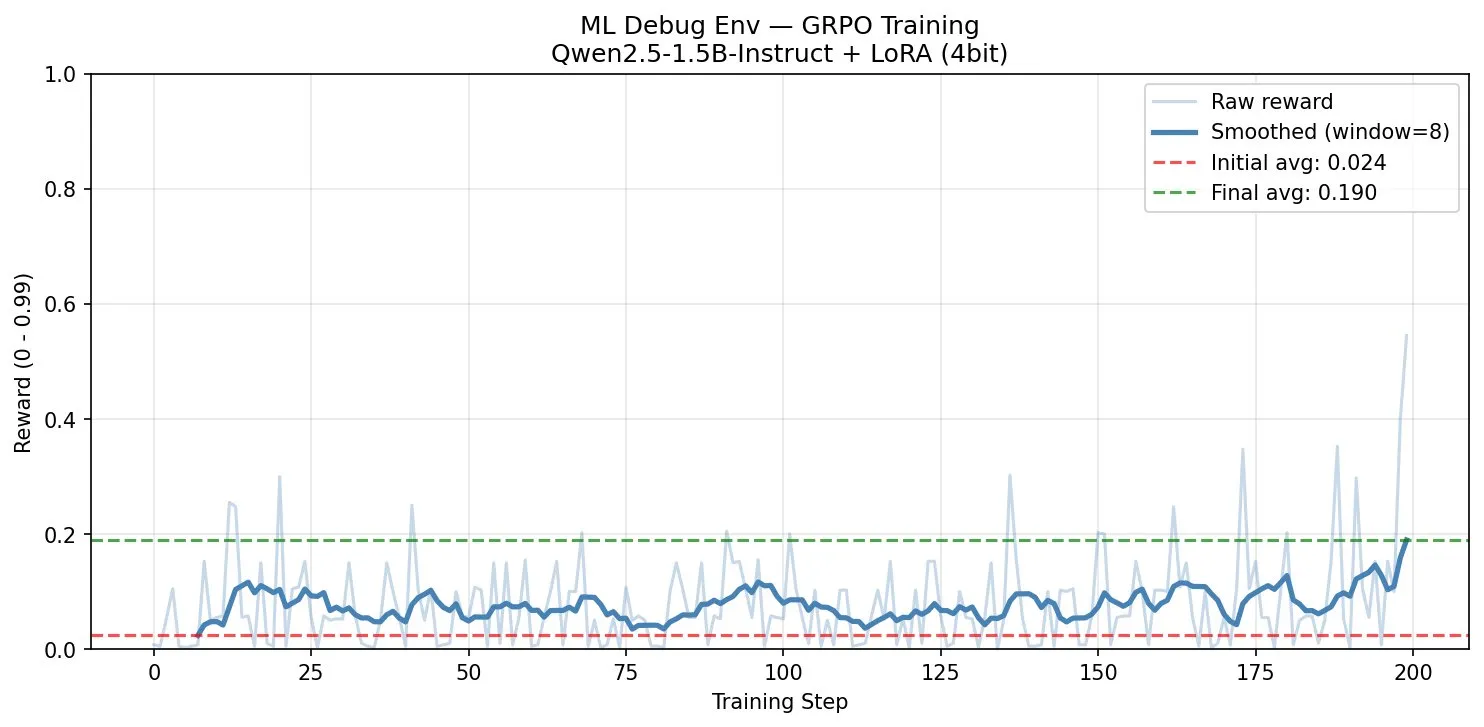 Run 2: 0.024 → 0.190, +690% improvement after grader fix
Run 2: 0.024 → 0.190, +690% improvement after grader fix
Fixed the training loop — added short-output filtering so the model couldn't game reward by outputting garbage JSON, and implemented proper GRPO over all completions instead of just the best one. Baseline at step zero lifted from 2.4% to 15.2%. The floor raised — proof the grader fixes held.
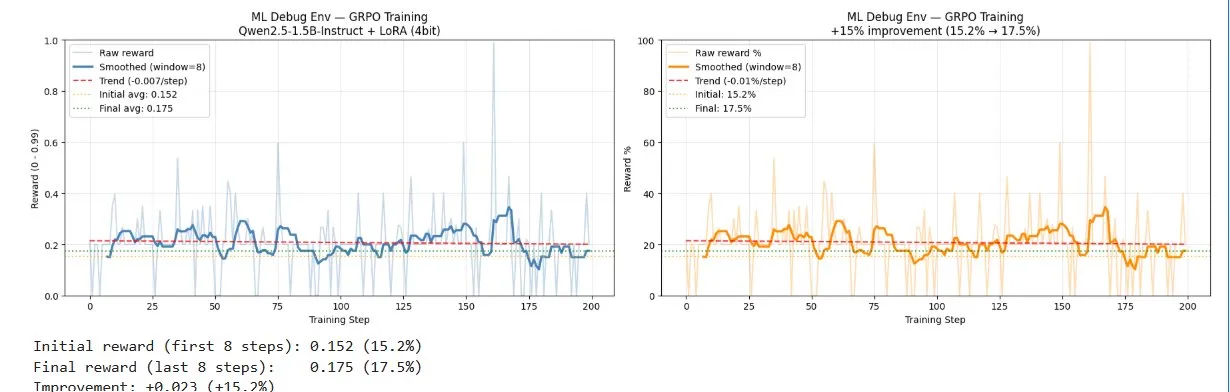 Run 3: baseline lifted from 2.4% to 15.2% — training loop fixed
Run 3: baseline lifted from 2.4% to 15.2% — training loop fixed
Every run taught us something. The environment improved itself because of what training revealed.
These behaviors emerged from reward signal alone — we never explicitly programmed them:
- Investigate before fixing — agent learned to call
run_codeorinspect_gradientsbefore attempting a fix - Tool selection by bug type — gradient issues →
inspect_gradientsfirst. Crashes →get_tracebackfirst - Avoid
view_source— the agent learned that the traceback alone is usually enough and reading full source wastes a step - Efficiency matters — agent learned to fix in fewer steps to maximize the efficiency bonus
Tracks per-task scores across episodes. Bug types where the agent scores below 0.6 after 3 attempts are marked "weak." Future reset() calls serve weak tasks 70% of the time with novel random seeds. The environment gets harder as the agent improves.
After every fix attempt, a Groq LLM (llama-3.3-70b) evaluates the agent's diagnosis — did it identify the root cause correctly? Did it explain the mechanism? Adds up to 0.15 reasoning reward on top of execution reward.
The fixed code is written to a temp file and executed in a subprocess with a 40-second timeout. AST checks verify structural correctness. Output is parsed for success signals — epoch logs, loss values, accuracy numbers. Absolutely no regex matching or string similarity — the code runs or it doesn't.
| Field | When Set | Description |
|---|---|---|
task_id |
Always | Which task is active |
alert |
On reset | Minimal failure message — no code, no traceback |
available_tools |
Always | Tools the agent can call |
step_budget |
Always | Steps remaining |
num_bugs |
Always | 1 for single-bug tasks, 2 for compound tasks |
tool_name |
After inspect | Which tool was called |
tool_result |
After inspect | What the tool returned |
grader_score |
After fix | Score 0.01–0.99 |
grader_feedback |
After fix | Why this score was assigned |
efficiency_multiplier |
After fix | Bonus applied (1.0–1.2×) |
done |
Always | Episode over if score ≥ 0.95 or steps exhausted |
import requests
session = requests.Session()
BASE = "https://rak2315-ml-debug-env.hf.space"
# Start episode — get alert only, no code
obs = session.post(f"{BASE}/reset", json={"task_id": "shape_mismatch"}).json()["observation"]
print(obs["alert"]) # "Training job crashed immediately. No epochs completed. Exit code 1."
# Investigate
result = session.post(f"{BASE}/step", json={"action": {
"action_type": "inspect", "tool_name": "run_code"
}}).json()
print(result["observation"]["tool_result"]) # crash output
# Fix
result = session.post(f"{BASE}/step", json={"action": {
"action_type": "fix",
"bug_type": "shape_mismatch",
"diagnosis": "nn.Linear input dim wrong — fc2 expects 128 but fc1 outputs 64",
"fixed_code": "... complete fixed script ..."
}}).json()
print(result["observation"]["grader_score"]) # 0.99Or try it interactively at rak2315-ml-debug-env.hf.space/ui
Or run the full demo locally:
python demo.pyModel: Qwen2.5-1.5B-Instruct + LoRA (4bit, rank 16) via Unsloth Method: Custom GRPO loop (TRL had dependency conflicts on Colab/Kaggle) Notebook: ml_debug_env_grpo_fixed.ipynb
| Average Reward | |
|---|---|
| Untrained baseline (partial obs, blind start) | 0.024 |
| After GRPO training (200 steps, T4) | 0.190 |
| Improvement | +690% |
The training loop connects directly to the live environment. The agent generates fix attempts, the grader runs them in subprocess, rewards flow back into GRPO. No static dataset. GRPO generates 4 completions per prompt, scores all of them, and reinforces whichever scored higher than average — teaching the model what good debugging looks like through comparison, not supervision.
| Method | Path | Description |
|---|---|---|
POST |
/reset |
Start episode — returns alert + tools only |
POST |
/step |
inspect or fix action |
GET |
/tasks |
All 8 tasks with descriptions |
POST |
/grader |
Score a fix directly without a full episode |
GET |
/baseline |
Run built-in LLM agent on all 8 tasks |
GET |
/health |
{"status": "healthy"} |
GET |
/ui |
Interactive landing page |
GET |
/docs |
Swagger UI |
root/
├── inference.py ← Validator entry point
├── models.py ← DebugAction, DebugObservation, DebugState
├── ml_debug_env_grpo_fixed.ipynb ← GRPO training notebook
├── openenv.yaml ← 8 tasks listed
├── Dockerfile ← HF Space deployment
├── demo.py ← Live demo script (2 episodes, easy → expert)
└── server/
├── app.py ← FastAPI server + all endpoints
├── bug_generator.py ← 8 tasks, 3 variants each, seeded
├── grader.py ← Subprocess execution + AST checks + LLM judge
├── ml_debug_env_environment.py ← OpenEnv env, partial obs, tool handling
├── adversarial_scheduler.py ← Weak task tracking, skewed resets
├── baseline_inference.py ← Groq baseline agent
└── landing_page.html ← Served at /ui
| Resource | Link |
|---|---|
| 🤗 HF Space | rak2315-ml-debug-env.hf.space |
| 💻 GitHub | github.com/RAK2315/ml-debug-env |
| 📓 Colab Notebook | ml_debug_env_grpo_fixed.ipynb |
| 📝 Blog | BLOG.md |
| 🎥 YouTube | youtu.be/TjEavKODTQQ |
Meta × PyTorch × Scaler OpenEnv Hackathon — April 2026