use look-up table in IDate conversion #3279
Conversation
R/IDateTime.R
Outdated
| as.IDate.default <- function(x, ..., tz = attr(x, "tzone"), use_merge = 'auto') { | ||
| if (is.null(tz)) tz = "UTC" | ||
| as.IDate(as.Date(x, tz = tz, ...)) | ||
| if (isTRUE(use_merge) || (use_merge == 'auto' && length(x) >= 1000)) { |
There was a problem hiding this comment.
We could check class of "x" to redirect to this branch only types on which dt can do the merge.
There was a problem hiding this comment.
Good point. Will lead to strange unexpected errors otherwise.
Do we keep a list of known merge types? If not we should...
There was a problem hiding this comment.
in setops.R I used to define one so you can look it up from there, or maybe put to helper function and reuse
There was a problem hiding this comment.
yes, was thinking something like can_merge = function(x) class(x) %chin% known_types or just keep known_types = function() c(...)
There was a problem hiding this comment.
can_merge would need to handle multiple columns so maybe simpler just merge_types
There was a problem hiding this comment.
I guess this is what you're referring to:
bad_types = c("raw", "complex", if (block_list) "list")
found = bad_types %chin% c(vapply(x, typeof, FUN.VALUE = ""),
vapply(y, typeof, FUN.VALUE = ""))
R/IDateTime.R
Outdated
| if (isTRUE(use_merge) || (use_merge == 'auto' && length(x) >= 1000)) { | ||
| DT = data.table(x) | ||
| # shut off use_merge to prevent recursion | ||
| unique(DT)[ , 'IDate' := as.IDate(x, tz = tz, ..., use_merge = FALSE) |
There was a problem hiding this comment.
I would use "unique" before creating data.table
There was a problem hiding this comment.
Could you elaborate? Not quite following the reasoning... my thinking was unique.data.table would be more efficient.
There was a problem hiding this comment.
It will be more efficient than data.frame method, but not sure about comparing to vector. R uses data.table's order (not the parallel one, but previous one, still super fast). The fastest way might be to use forder(retGrp=T) to then subset to unique value.
There was a problem hiding this comment.
when using unique.data.table we have internal funique function in setops.R. AFAIU it will avoid extra copy of input if values are already unique.
There was a problem hiding this comment.
True. Yes, I think forder approach should be best since it'll obviate the need to do both unique and merge if I'm not mistaken...
There was a problem hiding this comment.
OK, not immediate to me how to do it with just forderv... here's what I came up with and it's horribly inefficient:
o = forderv(DT, retGrp = TRUE)
s = attr(o, 'starts')
n = length(x)
out = integer(n)
lookup = as.IDate(as.Date(x[o][s], tz = tz, ...))
for (ii in seq_along(s)) {
end_idx = if (ii == length(s)) n else s[ii + 1L] - 1L
out[o][s[ii]:end_idx] = lookup[ii]
}
setattr(out, 'class', c('IDate', 'Date'))
There was a problem hiding this comment.
@MichaelChirico which part is inefficient? loop? src/vecseq.c might be good solution for that
other ideas:
xis reordered according tooand then subset according tos. Shouldn't that be better to first subset and then reorder?
cc(F)
x = c(2L,4L,1L,2L,3L,1L,4L)
o = forderv(data.table(x), "x", retGrp=TRUE)
s = attr(o, 'starts')
x[o][s]
x[o[s]]- instead of
as.IDate(as.Date(it should be better to handle that inas.IDateonly, if possible
There was a problem hiding this comment.
Here's an approach with forderv:
IDate_character = function (x) {
o__ = data.table:::forderv(list(x), 1L, retGrp=TRUE)
if (attr(o__, "maxgrpn") == 1L) { ## lookup will not help us - let's just make a Date
ans = as.integer(as.Date(x))
} else {
f__ = attr(o__, 'starts')
len__ = data.table:::uniqlengths(f__, length(x))
if (!length(o__)) {
ans = rep.int(as.integer(as.Date(x[f__])), len__)
} else {
ans = integer(length(x))
ans[o__] = rep.int(as.integer(as.Date(x[o__[f__]])), len__)
}
}
class(ans) = c("IDate", "Date")
return(ans)
}Initial testing is promising - more performant than a lookup self-join and results seem to align with as.IDate. But I will admit it does not look as clean as the join method.
Edit: I forgot to add that this would give us uniqueN for free with length(f__).
There was a problem hiding this comment.
Great work! for our internal code I think this sort of usage of forderv is common enough that we don't need to worry too much about "cleanliness" as there are a few other examples too.
A benchmark would be nice; in any case feel free to update/mege directly into this branch to be sure you're getting the commit credit 😃
There was a problem hiding this comment.
There are 3 options we are discussing.
- Make a lookup table based on unique dates
- Use an existing lookup table that would invisibly take up memory (but be fast)
- Use
fordervdirectly
Additionally, there are two flavors, unkeyed and keyed. For the most part, option 1 is the fastest although once we get to 1e8 rows, the forderv option surprisingly starts to outpace it. Note, option #2 (which is proposed in the FR) is faster than my proposal with keyed and 1e5 rows.
If we agree that this is limited to as.IDate.character(), I will make the changes.
Unkeyed:
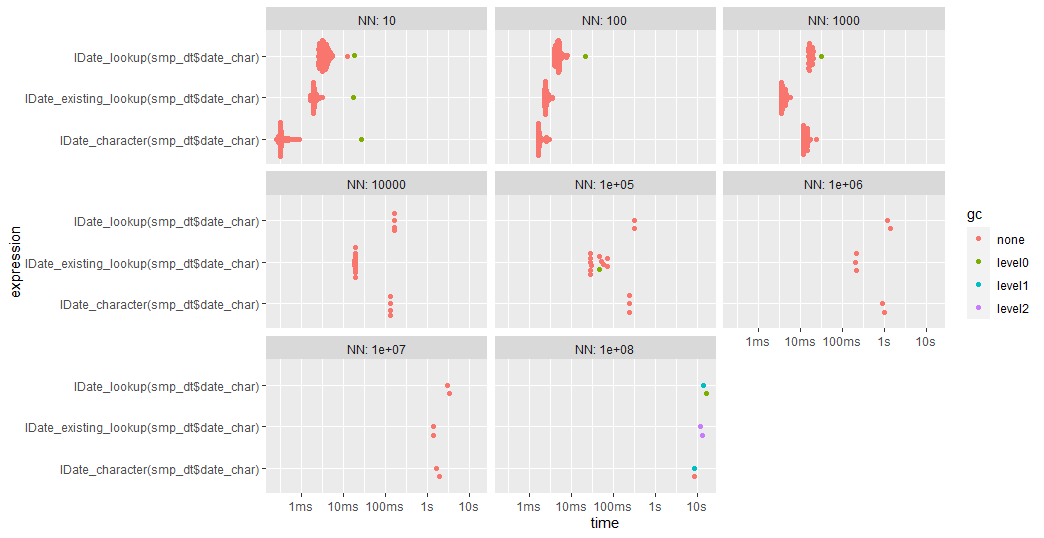
Keyed:
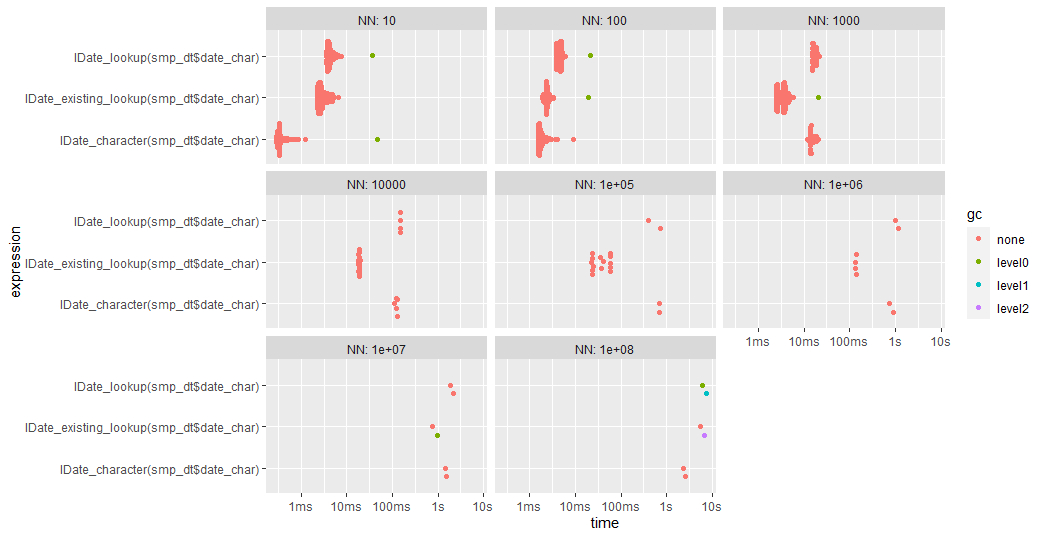
Code used:
library(data.table)
IDate_character = function (x) {
o__ = data.table:::forderv(list(x), 1L, retGrp=TRUE)
if (attr(o__, "maxgrpn", exact = TRUE) == 1L) { ## lookup will not help us - let's just make a Date
ans = as.integer(as.Date(x))
} else {
f__ = attr(o__, 'starts', exact = TRUE)
len__ = data.table:::uniqlengths(f__, length(x))
if (!length(o__)) {
ans = rep.int(as.integer(as.Date(x[f__])), len__)
} else {
ans = integer(length(x))
ans[o__] = rep.int(as.integer(as.Date(x[o__[f__]])), len__)
}
}
class(ans) = c("IDate", "Date")
return(ans)
}
IDate_lookup = function(x) {
tz = "UTC"
DT = list(input = x)
setDT(DT)
lookup = unique(DT)
lookup[ , 'IDate' := as.IDate(as.Date(input, tz = tz))]
lookup[DT, on = 'input']$IDate
}
IDate_existing_lookup = function(x) {
tz = "UTC"
DT = list(date_char = x)
setDT(DT)
date_lookup[DT, on = 'date_char']$date_int
}
dates = seq.Date(as.Date('1900-01-01'),
as.Date('2099-12-31'), by = 'day')
date_lookup = data.table(
date_char = as.character(dates),
date_int = as.IDate(dates),
key = 'date_char'
)
set.seed(3082)
NN = 1e7
smp_dt = copy(date_lookup[sample(.N, NN, TRUE)])
setkey(smp_dt, date_char)
plot(bench::press(
NN = c(10^(1:8)),
{
set.seed(3082)
smp_dt = copy(date_lookup[sample(.N, NN, TRUE)])
setkey(smp_dt, date_char) ## comment out to do unkeyed
bench::mark(
IDate_character(smp_dt$date_char),
IDate_lookup(smp_dt$date_char),
IDate_existing_lookup(smp_dt$date_char),
# as.IDate(smp_dt$date_char)
, min_iterations = 2L
)
}
))
Codecov Report
@@ Coverage Diff @@
## master #3279 +/- ##
==========================================
+ Coverage 94.81% 94.81% +<.01%
==========================================
Files 65 65
Lines 12094 12098 +4
==========================================
+ Hits 11467 11471 +4
Misses 627 627
Continue to review full report at Codecov.
|

Codecov Report
@@ Coverage Diff @@
## master #3279 +/- ##
==========================================
- Coverage 95.09% 94.81% -0.29%
==========================================
Files 65 65
Lines 12122 12100 -22
==========================================
- Hits 11528 11473 -55
- Misses 594 627 +33
Continue to review full report at Codecov.
|
man/IDateTime.Rd
Outdated
| \code{as.IDate.default}, arguments are passed to \code{as.Date}. For | ||
| \code{as.ITime.default}, arguments are passed to \code{as.POSIXlt}.} | ||
| \item{tz}{time zone (see \code{strptime}).} | ||
| \item{use_merge}{ Should the parsing be done by via merge? See Details. } |
There was a problem hiding this comment.
It ts good the mention what data type it expects, I usually do it as the first word of argument description. You can fix that for tz argument also.
I also don't like use_merge name, maybe use.dict?
Instead of character we could use a numeric value to avoid hardcoded 1000 length to kick in the merge. Default to 1000, passing Inf would be equivalent to current FALSE. I can be easier for users to program around that switch knowing uniqueN of input.
There was a problem hiding this comment.
Feels a bit weird to me to use absolute numbers like that... in terms of knowing your data you can always pass TRUE/FALSE (I mainly have in mind FALSE to account for the case when you know you have very few repeated dates). In any case moving to this I'd change the argument name to dict.threshold or similar.
|
I think it make sense to include the same feature for ITime in this PR, logic will be generally the same. |
|
@jangorecki just added |
This comment was marked as outdated.
This comment was marked as outdated.
473ee04 to
7c4622a
Compare
This comment was marked as outdated.
This comment was marked as outdated.
 jangorecki
left a comment
jangorecki
left a comment
There was a problem hiding this comment.
I would keep default disabled, just be safer on CRAN now, and changed to length(x)>1000 in 1.12.3
| as.IDate.default <- function(x, ..., tz = attr(x, "tzone"), use_lookup = 'auto') { | ||
| if (is.null(tz)) tz = "UTC" | ||
| as.IDate(as.Date(x, tz = tz, ...)) | ||
| if (isTRUE(use_lookup) || (use_lookup == 'auto' && length(x) >= 1000L)) { |
There was a problem hiding this comment.
How will it behave when user provide some custom class to this method? This is default method so it can get any kind of input. Or am I missing something?
Where is check that we support merge on x arg that we discussed before?
There was a problem hiding this comment.
PR still incomplete...
|
@MichaelChirico Now that the date parser is in |
Closes #2603
(and maybe #2503?)
Somewhat rough version intended to get the ball rolling on this -- open to design changes.
Design of
use_merge = 'auto'is kind of back-of-the-envelope based on mini-benchmark mentioned here: #2603 (comment)A more ideal version would be to look at
uniqueN(x)/length(x)as part of'auto', something like:but I am assuming (i.e. no benchmarking done on this) once we run
unique, we may as well go through with the merge.