Update layout for projects#1305
Conversation
✅ Deploy Preview for antenna-preview ready!
To edit notification comments on pull requests, go to your Netlify project configuration. |

✅ Deploy Preview for antenna-ssec ready!
To edit notification comments on pull requests, go to your Netlify project configuration. |
|
Warning Review limit reached
More reviews will be available in 56 minutes and 15 seconds. Learn how PR review limits work. Your organization has run out of usage credits. Purchase more in the billing tab. ⌛ How to resolve this issue?After more reviews become available, a review can be triggered using the We recommend that you space out your commits to avoid hitting the rate limit. 🚦 How do rate limits work?CodeRabbit enforces hourly rate limits for each developer per organization. Our paid plans include higher PR review limits than trial, open-source, and free plans. In all cases, reviews become available again over time. During sustained high-volume PR review activity, CodeRabbit may temporarily slow when the next review becomes available. Please see our Fair Usage Limits Policy for further information. ℹ️ Review info⚙️ Run configurationConfiguration used: defaults Review profile: CHILL Plan: Pro Run ID: 📒 Files selected for processing (3)
📝 WalkthroughWalkthroughAdds client-side sort controls and translations, integrates sorting into Projects page, extends ProjectViewSet to support name and recent-activity ordering via conditional queryset annotations, and adds concurrent DB indexes plus model entries to support recent-activity sorting. ChangesSorting Feature and UI Cleanup
Estimated code review effort🎯 4 (Complex) | ⏱️ ~40 minutes Possibly related PRs
Suggested labels
Suggested reviewers
Poem
🚥 Pre-merge checks | ✅ 3 | ❌ 2❌ Failed checks (1 warning, 1 inconclusive)
✅ Passed checks (3 passed)
✏️ Tip: You can configure your own custom pre-merge checks in the settings. ✨ Finishing Touches🧪 Generate unit tests (beta)
Thanks for using CodeRabbit! It's free for OSS, and your support helps us grow. If you like it, consider giving us a shout-out. Comment |
There was a problem hiding this comment.
Actionable comments posted: 1
🤖 Prompt for all review comments with AI agents
Verify each finding against current code. Fix only still-valid issues, skip the
rest with a brief reason, keep changes minimal, and validate.
Inline comments:
In `@ami/main/api/views.py`:
- Line 158: The Project model's name field is used in ordering (ordering_fields
includes "name") but lacks a DB index; update the Project model by adding
db_index=True to the name field declaration (Project.name) or alternatively
declare an Index on "name" inside the Project.Meta.indexes so sorts by name use
the index; migrate the DB after change to apply the new index.
🪄 Autofix (Beta)
Fix all unresolved CodeRabbit comments on this PR:
- Push a commit to this branch (recommended)
- Create a new PR with the fixes
ℹ️ Review info
⚙️ Run configuration
Configuration used: defaults
Review profile: CHILL
Plan: Pro
Run ID: 188d3959-ae86-4161-a080-ca9ff08e9603
⛔ Files ignored due to path filters (1)
ui/yarn.lockis excluded by!**/yarn.lock,!**/*.lock
📒 Files selected for processing (11)
ami/main/api/views.pyui/package.jsonui/src/design-system/components/sort-control.tsxui/src/pages/jobs/jobs.tsxui/src/pages/occurrences/occurrences.tsxui/src/pages/project-details/new-project-dialog.tsxui/src/pages/project/team/team-columns.tsxui/src/pages/project/team/team.tsxui/src/pages/projects/project-gallery.tsxui/src/pages/projects/projects.tsxui/src/utils/language.ts
💤 Files with no reviewable changes (2)
- ui/src/pages/project/team/team-columns.tsx
- ui/src/pages/projects/project-gallery.tsx
Backs the project "recent activity" sort options. SourceImage is large in production (tens of millions of rows), so the indexes are built CONCURRENTLY in a non-atomic migration that clears statement_timeout for the build. Co-Authored-By: Claude <noreply@anthropic.com>
Add ordering by most recent capture timestamp, occurrence update and job update. The aggregate fields are annotated as correlated subqueries only when that ordering is requested, so the default project list stays cheap. Co-Authored-By: Claude <noreply@anthropic.com>
A column can declare a defaultSortOrder that is applied when the field is first selected, so date-like fields (e.g. "Recent ...") open newest-first. Co-Authored-By: Claude <noreply@anthropic.com>
Adds "Recent observations", "Recent identifications" and "Recent jobs" sort options, each defaulting to newest-first. Co-Authored-By: Claude <noreply@anthropic.com>
Use Max("deployments__last_capture_timestamp") for the last_capture_timestamp
ordering instead of a correlated subquery over SourceImage. The per-deployment
timestamp is already denormalized, so this avoids scanning the multi-million
row SourceImage table and matches the live max value for every project.
With the subquery gone, the dedicated SourceImage (project, -timestamp) index
is no longer needed, so drop it from the model and migration 0085. The
occurrence index stays, since recent identifications still uses a subquery.
Co-Authored-By: Claude <noreply@anthropic.com>
There was a problem hiding this comment.
Actionable comments posted: 1
🤖 Prompt for all review comments with AI agents
Verify each finding against current code. Fix only still-valid issues, skip the
rest with a brief reason, keep changes minimal, and validate.
Inline comments:
In `@ami/main/migrations/0085_project_activity_sort_indexes.py`:
- Around line 23-34: The migration sets a session-wide statement_timeout to 0
but never resets it, so later non-atomic migrations inherit a disabled timeout;
add a trailing migrations.RunSQL after the AddIndexConcurrently that executes
"SET statement_timeout = DEFAULT;" (use migrations.RunSQL.noop for its
reverse_sql) so the session timeout is restored after the concurrent index build
for the model "occurrence" and index "occur_proj_updated_desc_idx".
🪄 Autofix (Beta)
Fix all unresolved CodeRabbit comments on this PR:
- Push a commit to this branch (recommended)
- Create a new PR with the fixes
ℹ️ Review info
⚙️ Run configuration
Configuration used: defaults
Review profile: CHILL
Plan: Pro
Run ID: 1741adf6-efd6-405b-9ff9-13383e050aad
📒 Files selected for processing (7)
ami/main/api/views.pyami/main/migrations/0085_project_activity_sort_indexes.pyami/main/models.pyui/src/design-system/components/sort-control.tsxui/src/design-system/components/table/types.tsui/src/pages/projects/projects.tsxui/src/utils/language.ts
|
@annavik thanks for expanding the projects view! I responded to the feedback from co-pilot and I added some more sort options! 
Still exploring names for the sort fields. I want to be able to see which projects had any recent occurrence activity (human or machined, created or updated). "Recent identifications" is all I can think of. |
… count Sort "recent captures" by a live per-project max capture time again, via a correlated subquery backed by a new (project, -timestamp) index on SourceImage (migration 0086). This keeps the sort accurate the moment captures land, rather than depending on the denormalized Deployment timestamp staying fresh. SourceImage.timestamp is nullable and DESC orders NULLs first, so the subquery excludes null timestamps explicitly — otherwise a single undated capture in a project masks its real most-recent capture and drops it to the bottom of the list. Verified the result now matches max(timestamp) for every project. Also strip the activity annotations from the pagination COUNT query (ProjectPagination.get_count): they don't affect the row count, and leaving them in made every paginated list run the subqueries again just to count. Co-Authored-By: Claude <noreply@anthropic.com>
Label the three recent-activity sort options for what they actually order by: "Recent captures" (SourceImage timestamp), "Occurrence updates" (Occurrence.updated_at) and "Jobs activity" (Job.updated_at). The previous "Recent observations / identifications / jobs" wording leaned on domain terms that don't map 1:1 to the underlying fields. Backend ordering keys unchanged. Co-Authored-By: Claude <noreply@anthropic.com>
|
Claude says: Added three "recent activity" sort options to the projects list, in addition to Name / Created at / Updated at:
Each is annotated on the queryset only when selected (the default list stays cheap) and defaults to newest-first. The captures sort uses a live per-project max over a new |
There was a problem hiding this comment.
Caution
Some comments are outside the diff and can’t be posted inline due to platform limitations.
⚠️ Outside diff range comments (1)
ami/main/api/views.py (1)
187-217:⚠️ Potential issue | 🟠 MajorCheck index support for the conditional activity annotations
last_capture_timestampexcludes NULLs and should leveragemain_source_proj_ts_desc_idx(migration 0086).last_occurrence_updated_athas an expected supporting index:occur_proj_updated_desc_idxonOccurrence(project, -updated_at)(migration 0085).- No
Job(project, -updated_at)supporting index was found forlast_job_updated_at; add the missing index to keep that ordering from degrading performance.🤖 Prompt for AI Agents
Verify each finding against current code. Fix only still-valid issues, skip the rest with a brief reason, keep changes minimal, and validate. In `@ami/main/api/views.py` around lines 187 - 217, The conditional annotations (last_capture_timestamp, last_occurrence_updated_at, last_job_updated_at) rely on indexes for performance; ensure the SourceImage and Occurrence indexes referenced (main_source_proj_ts_desc_idx from migration 0086 and occur_proj_updated_desc_idx from migration 0085) exist and then add a new DB index for Job(project, -updated_at) to support the last_job_updated_at Subquery in ami/main/api/views.py: update or add a migration that creates a descending index on Job(project, updated_at) (or the DB-specific equivalent), name it clearly (e.g., job_proj_updated_desc_idx), and run migrations so the Job.objects.filter(...).order_by("-updated_at") subquery can use an index and avoid a full scan.
🤖 Prompt for all review comments with AI agents
Verify each finding against current code. Fix only still-valid issues, skip the
rest with a brief reason, keep changes minimal, and validate.
Outside diff comments:
In `@ami/main/api/views.py`:
- Around line 187-217: The conditional annotations (last_capture_timestamp,
last_occurrence_updated_at, last_job_updated_at) rely on indexes for
performance; ensure the SourceImage and Occurrence indexes referenced
(main_source_proj_ts_desc_idx from migration 0086 and
occur_proj_updated_desc_idx from migration 0085) exist and then add a new DB
index for Job(project, -updated_at) to support the last_job_updated_at Subquery
in ami/main/api/views.py: update or add a migration that creates a descending
index on Job(project, updated_at) (or the DB-specific equivalent), name it
clearly (e.g., job_proj_updated_desc_idx), and run migrations so the
Job.objects.filter(...).order_by("-updated_at") subquery can use an index and
avoid a full scan.
ℹ️ Review info
⚙️ Run configuration
Configuration used: defaults
Review profile: CHILL
Plan: Pro
Run ID: 94f73d02-c7e0-4d1e-bb63-cc7ae5885153
📒 Files selected for processing (5)
ami/main/api/views.pyami/main/migrations/0086_sourceimage_recent_capture_index.pyami/main/models.pyui/src/pages/projects/projects.tsxui/src/utils/language.ts
Fixes the CI 'Check Format' failure. Co-Authored-By: Claude <noreply@anthropic.com>
The non-atomic activity-sort index migrations SET statement_timeout = 0 so the CONCURRENTLY build is not killed by a configured timeout. That SET is session-scoped, so without a trailing RESET the disabled timeout leaked into later migrations sharing the same connection, silently dropping the safeguard. Add RESET statement_timeout as the final operation in both 0085 and 0086. Addresses CodeRabbit review on PR #1305. Co-Authored-By: Claude <noreply@anthropic.com>
… main merge main merged #1305 which took 0085/0086 (project activity + recent-capture indexes). Repoint the GIN-index migration onto 0086 and update the references to it (views.py comment, rollup perf doc). Co-Authored-By: Claude <noreply@anthropic.com>
* feat(taxa): per-taxon verification + agreement counts and verified filter Adds to GET /api/v2/taxa/ (issue #1316): - verified_count and agreed_with_prediction_count annotations (always on), rolled up over descendant occurrences via a hierarchical parents_json match. - agreed_exact_count, gated behind with_agreement=true (and always on the detail view). - verified=true|false filter (EXISTS / strict complement), project-scoped and respecting apply_default_filters. - verified_count added to ordering_fields. The hierarchical descendant match uses a Postgres jsonb @> containment built from an OuterRef (literal __contains can't embed an OuterRef). Migration 0085 adds the supporting GIN index on Taxon.parents_json (jsonb_path_ops). Frontend: sortable "Verified" column + "Verification status" filter on the taxa list, and a Verification panel on the taxon detail page. Co-Authored-By: Claude <noreply@anthropic.com> * perf(taxa): compute verification rollup in one pass, not per-taxon subquery The per-taxon correlated parents_json subquery for verified_count / agreed_with_prediction_count / agreed_exact_count did not scale: on a large project (~1k taxa, ~17k occurrences) the taxa list timed out at the 30s statement limit even with the column hidden and on the default sort, because each page row (and the verified=false COUNT) ran a JSONB containment scan the GIN index can't serve when the @> right-hand side is an OuterRef. All three counts only concern verified occurrences (those with a non-withdrawn Identification), which are sparse. Compute the hierarchical rollup in a single pass over that small set in Python and apply it as constant-time CASE annotations; resolve the verified filter from the same precomputed set via id__in. Page values, sort, and the pagination COUNT are now constant-time. Also fixes ancestor rollup returning 0: parents_json round-trips through the pydantic schema field, so elements may be TaxonParent objects rather than dicts. Measured on the large project: default page 30s timeout -> ~0.6s; verified=false 30s timeout -> ~0.2s; ordering=verified_count 30s timeout -> ~0.04s. Co-Authored-By: Claude <noreply@anthropic.com> * docs(taxa): clarify GIN index purpose + add rollup query-performance reference The parents_json GIN index (migration 0085) no longer backs the verification rollup (now a Python single-pass). Update the migration docstring and add an inline comment at its real consumer — the literal-RHS containment in the occurrence-list taxon filter — so the index's purpose is clear. Add docs/claude/reference/hierarchical-rollup-query-performance.md capturing the anti-pattern (per-taxon correlated parents_json subquery) vs the pattern (precompute over the sparse set + CASE), the COUNT/cachalot/pydantic-field gotchas, and the denormalized TaxonObserved direction. Co-Authored-By: Claude <noreply@anthropic.com> * fix(taxa): dedupe occurrences in verification rollup under collection filter When ?collection=<id> joins Occurrence to detections, a single occurrence yields one row per matching detection, inflating verified_count / agreed_with_prediction_count / agreed_exact_count. Select pk and .distinct() the values() rollup so each occurrence is counted once. Adds a regression test. Co-Authored-By: Claude <noreply@anthropic.com> * chore(migrations): renumber parents_json GIN index 0085 -> 0087 after main merge main merged #1305 which took 0085/0086 (project activity + recent-capture indexes). Repoint the GIN-index migration onto 0086 and update the references to it (views.py comment, rollup perf doc). Co-Authored-By: Claude <noreply@anthropic.com> * fix(taxa): make collection-filtered taxa list COUNT scale The observed-set membership used a correlated EXISTS; under ?collection=<id> the occurrence_filters join to detections turned it into a per-taxon scan, timing out the pagination COUNT (no LIMIT to short-circuit). Replace with a single distinct-determination id__in subquery. Default path unchanged; the collection path drops from a 30s timeout to sub-second. Co-Authored-By: Claude <noreply@anthropic.com> * fix(taxa): materialize observed-taxon id set instead of IN-subquery The IN-subquery form (b92b2b0) still embedded the detections m2m join in both the COUNT and page queries; under ?collection=<id> the planner re-evaluated it pathologically (collection path ~87s). Materialize the distinct-determination id set in one query (~0.2s) so COUNT/page reduce to a plain indexed id IN (...). Mirrors the verified-filter pattern. Co-Authored-By: Claude <noreply@anthropic.com> * refactor(taxa): centralize per-taxon counts into one filtered-occurrence pass The taxa list computed occurrences_count / best_determination_score / last_detected as three per-taxon correlated subqueries. Index-served for the default filters, but under ?collection=<id> the detections join turned each into a per-row scan (~20s for a 25-row page on a large project), on top of the already-fixed COUNT membership. Replace them with annotate_taxon_counts: one GROUP BY over the shared filtered occurrence set builds {taxon_id: value} maps, applied as constant-time CASE annotations via _case_from_map. The same base feeds the verification rollup (_annotate_verification_counts, formerly add_verification_data), and its determination ids serve the observed-set membership filter, so no separate membership query is needed. Count(distinct) also dedupes the collection join fan-out for occurrences_count. No denormalized model introduced. Co-Authored-By: Claude <noreply@anthropic.com> * fix(taxa): use conditional aggregation for dense per-taxon counts The previous commit applied occurrences_count / best_determination_score / last_detected as CASE-from-map annotations. That works for the sparse verified counts but not for these dense aggregates: one CASE branch per observed taxon blew past the SQL parser token limit (SQLParseError: Maximum number of tokens exceeded) on large projects, breaking every taxa request. Switch the dense aggregates to conditional aggregation over the Taxon->occurrences reverse relation (Count/Max with filter=, the pattern already used for Event counts), which is one GROUP BY with constant-size SQL. occurrences_count__gt=0 becomes the observed-set membership (HAVING). The sparse verified/agreement counts stay as CASE annotations. get_occurrence_filters gains an accessor arg to express the same filters through the reverse relation. Measured on a ~1k-taxa / ~17k-occurrence project: collection-filtered list page ~0.25s and COUNT ~0.31s (was a 30s+ timeout); default/verified/ordering ~0.1-0.4s. Co-Authored-By: Claude <noreply@anthropic.com> * fix(taxa): drop redundant taxa filter from occurrences_count aggregate Including the default taxa include/exclude filter in the conditional-aggregate filter added a parents_json containment join the planner couldn't reconcile with the detections (?collection=) join, turning the collection page into a multi-minute scan. It is redundant: occurrences_count groups by determination = the taxon row, so the per-occurrence taxa filter just mirrors filter_by_project_default_taxa (already applied to the queryset). Keep only the per-occurrence score threshold in the aggregate; the verification base still gets the full filters (sparse, cheap). Collection-filtered list now ~0.3s (page + COUNT); default/verified/ordering ~0.1-0.4s. Co-Authored-By: Claude <noreply@anthropic.com> * fix(taxa): remove redundant TaxonCollectionFilter backend The filter_backends chain included TaxonCollectionFilter, which unconditionally appends queryset.filter(occurrences__detections__source_image__collections=<id>) to the Taxon queryset on top of whatever annotate_taxon_counts already does. The collection filter is now fully enforced inside the conditional aggregates (via get_occurrence_filters(accessor="occurrences")) and the observed-set HAVING, so the backend only added a redundant JOIN on the main qs. Combined with the aggregate GROUP BY, that JOIN turned the collection-filtered taxa page into a multi-minute scan; removing it brings ?collection= back to sub-second. Co-Authored-By: Claude <noreply@anthropic.com> * docs(taxa): document sparse vs dense — when CASE breaks, when to use conditional aggregation Captures the two findings from the collection-path timeout fix: (1) the CASE-from-map precompute pattern only scales for sparse maps because dense maps blow past sqlparse's 10000-token limit, and (2) the two gotchas that turn conditional aggregation from sub-second into a multi-minute scan (taxa filter redundant inside the aggregate, redundant collection JOIN backend on top of the aggregate GROUP BY). Co-Authored-By: Claude <noreply@anthropic.com> * docs(taxa): next-session handoff — hybrid direct-aggregates + move to TaxonQuerySet Captures the two follow-ups: (1) restore correlated Subquery aggregates for the default path (regressed 0.82s -> 2.14s under conditional aggregation) while keeping conditional aggregation for ?collection=; (2) move with_observation_counts / observed_in_project / with_verification_counts onto TaxonQuerySet to lighten the viewset. Includes the live timings, the three gotchas to preserve, and the commit chronology so the next session can pick up cold. Co-Authored-By: Claude <noreply@anthropic.com> * refactor(taxa): move count logic to TaxonQuerySet, hybrid subquery/aggregation dispatch Lifts per-taxon count annotation logic out of TaxonViewSet into four new TaxonQuerySet methods, matching the "Custom QuerySet Methods (Always Use These)" pattern in CLAUDE.md. - with_observation_counts_subqueries — three correlated Subquery annotations (occurrences_count / best_determination_score / last_detected), index-served by the composite (determination_id, project_id, event_id, determination_score) index on Occurrence. Default / event / deployment / verified / ordering paths. - with_observation_counts_aggregated — conditional aggregation over the Taxon→occurrences reverse relation with Count(distinct) dedup. Required under ?collection=<id> where the detections join turns correlated subqueries into per-row scans. - observed_in_project_subqueries — materialised id__in membership for the subquery path (the aggregate path uses HAVING via occurrences_count__gt=0). - with_verification_counts — sparse CASE-from-map rollup of verified_count / agreed_with_prediction_count / (gated) agreed_exact_count over ancestor parents_json, with optional verified=true|false filter. TaxonViewSet.get_taxa_observed shrinks to a dispatcher that picks the count shape based on "collection" in request.query_params and chains the queryset methods. _case_from_map moves to a module-level helper alongside the new queryset methods. Removes the now-redundant TaxonCollectionFilter backend (its INNER JOIN on queryset.filter(occurrences__detections__source_image__collections=<id>) was unreconcilable with the aggregate GROUP BY). Co-Authored-By: Claude <noreply@anthropic.com> * refactor(taxa): drop model-agreement counts, keep verification only PR scope narrowed to match issue #1316 (per-taxon verification UX). The model-agreement signals (`agreed_with_prediction_count`, `agreed_exact_count`, `with_agreement` query gate) had no FE consumer at merge time and serve a different audience (ML model evaluation) than the human-trust `verified_count`. They are deferred to follow-up issue #1319 where they can be paired with a real FE consumer and renamed to a `model_agreed_*` prefix to disambiguate from human verifications. Removed from the backend: - Classification + Identification subqueries inside `TaxonQuerySet.with_verification_counts` for `_best_machine_taxon_id` and `_agreed_prediction_id` - `include_agreement` parameter on `with_verification_counts` - `TaxonViewSet._include_agreement` and the `with_agreement` query param - `agreement_requested` helper and the field-pop logic in `TaxonListSerializer.__init__` - `agreed_with_prediction_count` / `agreed_exact_count` fields on `TaxonListSerializer` and `TaxonSerializer` - Property stubs `Taxon.agreed_with_prediction_count` / `Taxon.agreed_exact_count` - Tests for the agreed counts (kept the rollup, dedup, list, and ordering tests for the verified count) Removed from the frontend: - `Species.numAgreedWithPrediction` / `Species.numAgreedExact` getters - "Agreed with prediction" and "Matched model exactly" rows in the species detail view (Verification block keeps just the Verified row) 40 of the 43 taxa tests pass under CI compose; the dropped three covered the agreed counts. Co-Authored-By: Claude <noreply@anthropic.com> * docs(taxa): consolidate PR #1317 findings into single reference, drop stale planning + prompt files [skip ci] - Expanded `docs/claude/reference/hierarchical-rollup-query-performance.md` to be the single canonical reference for per-taxon rollup queries on the taxa endpoint. Adds the `TaxonQuerySet` API surface and dispatch decision table, the detection fan-out dedup pattern, and the model-agreement split-out rationale (deferred to issue #1319). - Deleted `docs/claude/planning/2026-05-20-taxa-verification-guidance-ticket.md` (superseded by the PR description and the reference doc; the deferred model-agreement scope now lives on issue #1319). - Deleted `docs/claude/prompts/NEXT_SESSION_PROMPT.md` (work shipped). Co-Authored-By: Claude <noreply@anthropic.com> --------- Co-authored-by: Claude <noreply@anthropic.com>
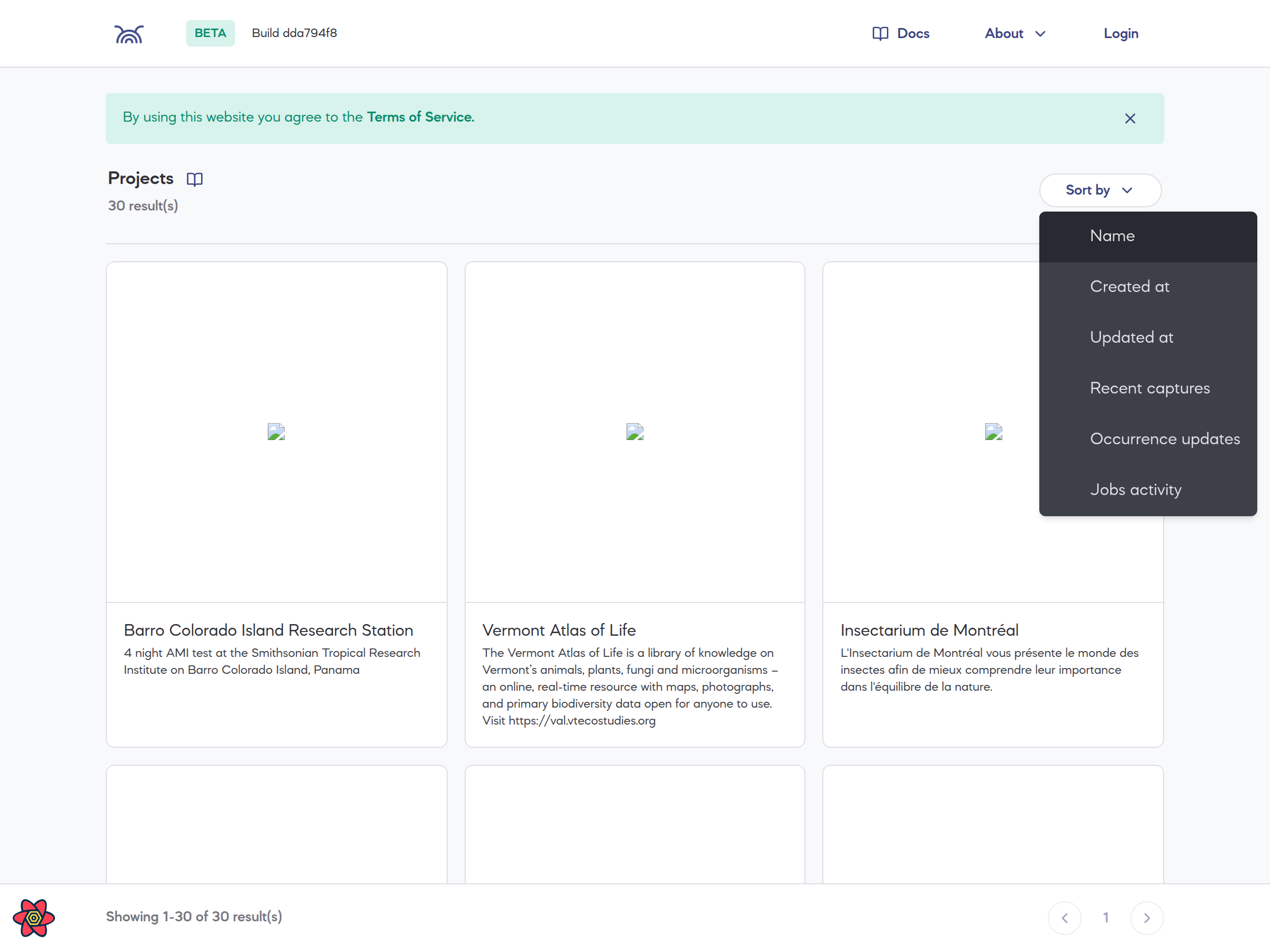
The more projects we add, the more difficult the project page is to navigate. For most users, the main view will be a more compact list of projects they are a member of, but for super admins with access to all projects it can be a bit tricky. Also, in some cases, users might want to explore public projects they are not a member of. Also that list can get pretty long!
In this PR, we make some simple UI updates, to improve the situation a bit.
Summary of changes
Thoughts for future
A search feature would be nice, but it requires a few more backend updates and maybe not our highest prio. Also a more compact table view for projects could be interesting to explore...
Deploy notes
Sort projects by name required a tiny BE update.
Screenshots
Before

After

Summary by CodeRabbit
New Features
UI Improvements
Bug Fixes
Chores / Performance