O presente projeto foi originado no contexto das atividades da disciplina de pós-graduação IA376L - Deep Learning aplicado a Síntese de Sinais, oferecida no primeiro semestre de 2022, na Unicamp, sob supervisão da Profa. Dra. Paula Dornhofer Paro Costa, do Departamento de Engenharia de Computação e Automação (DCA) da Faculdade de Engenharia Elétrica e de Computação (FEEC).
| Nome | RA | Especialização |
|---|---|---|
| Ronnypetson Souza da Silva | 211848 | Ciência da Computação |
No Xadrez, humanos e máquinas são capazes de jogar de modo que as máquinas são superiores. Entretanto, a forma como as máquinas jogam pode causar estranheza, pois encontram sequências de lances que não surgem naturalmente em partidas entre humanos (mesmo profissionais). Neste trabalho, geramos partidas sintéticas de Xadrez com a finalidade de mimetizar partidas com aparência "natural" entre seres humanos. Para tanto, treinamos um modelo de linguagem baseado em Transformer em uma base de partidas entre profissionais. Os resultados sugerem que o modelo é capaz de aprender bem as aberturas, apesar do jogo degradar depois.
O tema do projeto é a geração de partidas de Xadrez, usando a notação PGN (Portable Game Notation), que sejam semelhantes à partidas entre profissionais do jogo. Para tanto, deseja-se usar modelos de linguagem autorregressivos baseados em Transformer, tais como BERT (Masked Language Model) e GPT (Causal Language Model). A aplicação mais importante de um modelo generativo de Xadrez que imita jogadores humanos é tornar as engines mais parecidas com os humanos nos lances. Outra aplicação de partidas de Xadrez sintéticas semelhante às que humanos jogam podem ser usadas na literatura e no cinema (ex: O Gambito da Rainha, Os Simpsons, Death Note, Harry Potter), com geração condicionada e flexibilidade. Por ser compatível com modelos de linguagem e por possuir muitas partidas públicas que a usam, a notação PGN é uma escolha adequada para a tarefa em questão.
Os modelos de linguagem autorregressivos baseados em Transformer têm mudado o estado-da-arte em várias tarefas de linguagem natural, tais como tradução, reponder à perguntas, raciocínio de bom senso e interpretação de texto. Também têm sido usados na geração de código em linguagens de programação, imagens vetorizadas tipo SVG e arquivos no formato MIDI. A princípio, uma base de textos em qualquer linguagem, natual ou não, com um vocabulário de tamanho razoável (menor ou comparável com o vocabulário de uma linguagem natural como o Inglês), pode ser modelada com esse tipo de técnica. Isso inclui os textos nos arquivos PGN de Xadrez, que possuem um vocabulário - cerca de 14700 tokens - bem menor do que o do Inglês.
A saída do modelo será uma sequência de anotações de lances de Xadrez numa versão simplificada do formato PGN. Nesse formato, cada lance especifica uma peça no tabuleiro e a nova casa que deve ocupar. As peças, exceto peões, são representados por letras da seguinte forma:
- Peão: ♙♟
- Cavalo: N (kNight) ♘♞
- Bispo: B (Bishop) ♗♝
- Torre: R (Rook) ♖♜
- Dama: Q (Queen) ♕♛
- Rei: K (King) ♔♚
As linhas e colunas do tabuleiro são representadas pelos números de 1 à 8 e pelas letras de a à h, como mostra a figura abaixo. Dessa maneira, quando queremos dizer "mover o cavalo para a casa f3", escrevemos Nf3 na notação PGN. Quando a peça a ser movida é ambígua, pode-se especificar a coluna e/ou a linha da casa que a peça ocupa caso seja necessário, como por exemplo Ngf3, N5f3 ou Ne5f3. Esses lances também representam o movimento de um cavalo para a casa f3. Imagem obtida da Wikipedia.

Um arquivo PGN completo tem o seguinte formato
[Event "F/S Return Match"]
[Site "Belgrade, Serbia JUG"]
[Date "1992.11.04"]
[Round "29"]
[White "Fischer, Robert J."]
[Black "Spassky, Boris V."]
[Result "1/2-1/2"]
1. e4 e5 2. Nf3 Nc6 3. Bb5 a6 {This opening is called the Ruy Lopez.}
4. Ba4 Nf6 5. O-O Be7 6. Re1 b5 7. Bb3 d6 8. c3 O-O 9. h3 Nb8 10. d4 Nbd7
11. c4 c6 12. cxb5 axb5 13. Nc3 Bb7 14. Bg5 b4 15. Nb1 h6 16. Bh4 c5 17. dxe5
Nxe4 18. Bxe7 Qxe7 19. exd6 Qf6 20. Nbd2 Nxd6 21. Nc4 Nxc4 22. Bxc4 Nb6
23. Ne5 Rae8 24. Bxf7+ Rxf7 25. Nxf7 Rxe1+ 26. Qxe1 Kxf7 27. Qe3 Qg5 28. Qxg5
hxg5 29. b3 Ke6 30. a3 Kd6 31. axb4 cxb4 32. Ra5 Nd5 33. f3 Bc8 34. Kf2 Bf5
35. Ra7 g6 36. Ra6+ Kc5 37. Ke1 Nf4 38. g3 Nxh3 39. Kd2 Kb5 40. Rd6 Kc5 41. Ra6
Nf2 42. g4 Bd3 43. Re6 1/2-1/2
Entretanto, será usada apenas a parte que especifica os movimentos (movetext), sem a enumeração das rodadas e sem comentários, resultando numa notação similar à seguinte:
e4 e5 Nf3 Nc6 Bb5 a6 Ba4 Nf6 O-O Be7 Re1 b5 Bb3 d6 c3 O-O h3 Nb8 d4 Nbd7
c4 c6 cxb5 axb5 Nc3 Bb7 Bg5 b4 Nb1 h6 Bh4 c5 dxe5 Nxe4 Bxe7 Qxe7 exd6 Qf6 Nbd2 Nxd6
Nc4 Nxc4 Bxc4 Nb6 Ne5 Rae8 Bxf7+ Rxf7 Nxf7 Rxe1+ Qxe1 Kxf7 Qe3 Qg5 Qxg5 hxg5
b3 Ke6 a3 Kd6 axb4 cxb4 Ra5 Nd5 f3 Bc8 Kf2 Bf5 Ra7 g6 Ra6+ Kc5 Ke1 Nf4 g3 Nxh3
Kd2 Kb5 Rd6 Kc5 Ra6 Nf2 g4 Bd3 Re6 1/2-1/2
A partida pode ser recuperada usando um leitor de PGN (gif obtido em Chess.com):

O objetivo principal do projeto é a criação de um modelo generativo que seja capaz de produzir sequências de lances de Xadrez no formato PGN, de modo que gere partidas de Xadrez semelhantes à partidas jogadas por seres humanos no nível profissional (partidas jogadas em torneios). O modelo deve ser capaz de gerar partidas do início como também de completar partidas já começadas.
A base de dados a ser usada é um conjunto de várias partidas em torneios, disponível no site The Week in Chess. Ao todo são mais de 1400 arqivos zip, cada um contendo partidas de torneios profissionais ao redor do mundo em cada semana. Todas as partidas estão no formato PGN.
O download dos dados pode ser automatizado com o seguinte trecho de código em Python:
import os
url_base = 'https://theweekinchess.com/zips'
for idx in range(920, 1431):
fname = f'twic{idx}g.zip'
print('Downloading', fname)
url = f'{url_base}/{fname}'
os.system(f'wget {url}')
os.system(f'mv {fname} downloaded/{fname}')
Como os arquivos baixados estão no formato ZIP, podemos automatizar a extração com o seguinte trecho de código:
import zipfile
from glob import glob
fns = glob('downloaded/*.zip')
for fn in fns:
with zipfile.ZipFile(fn, 'r') as zip_ref:
zip_ref.extractall('extracted')
Os comentários e cabeçalhos podem ser removidos usando expressões regulares, visto que o formato dos cabeçalhos e dos comentários é simples, pois são delimitados por colchetes (cabeçalhos) e chaves (comentários). Já os números que anotam os lances também podem ser removidos facilmente, pois são os tokens que intercalam as anotações dos lances em si.
Visto que cada arquivo de texto extraído possui uma partida por linha (desconsiderando cabeçalhos), a separação das partidas pode ser feita através dos caracteres "\n". Uma vez limpas e separadas, as partidas podem ser salvas em outros arquivos que constituirão as bases de treino, validação e teste.
Dado que usamos as bibliotecas Tokenizer e Transformers da Huggingface, precisamos primeiramente treinar o tokenizer, que será responsável por transformar os textos de entrada em sequências de índices que representam as palavras do nosso vocabulário. Uma vez que o tokenizer esteja treinado, uma arquitetura tipo BERT (MLM) ou GPT (CLM) pode ser treinada na nossa base de partidas.

Em alguns casos, é possível que a base de treino não caiba inteiramente na memória. Isso exige que implementemos nossa própria classe que herda da classe Dataset da biblioteca PyTorch. Uma forma de implementar essa classe de modo a usar bases de dados arbitrariamente grandes é dividindo a base em vários arquivos (sharding), cada um com várias partidas. Daí em cada instante apenas uma parte das partidas precisa estar na memória.
Durante o carregamento das partidas, adicionamos o seguinte cabeçalho, que indica ao modelo a posição inicial das peças:
a2 a7 b2 b7 c2 c7 d2 d7 e2 e7 f2 f7 g2 g7 h2 h7 Ra1 Ra8 Nb1 Nb8 Bc1 Bc8 Qd1 Qd8 Ke1 Ke8 Bf1 Bf8 Ng1 Ng8 Rh1 Rh8
Por se tratar de um modelo com dezenas de milhões de parâmetros treináveis, são necessárias várias horas ou até mesmo dias de treino em hardware acelerador (GPU). A função de custo é a entropia cruzada no caso do GPT-2.

O modelo é treinado usando uma instância com GPU do Google Colab.
Checkpoints gerados durante o treino, o próprio modelo final e o tokenizer são mantidos numa pasta no Google Drive (vide imagem abaixo). Dessa forma, um treino pode ser retomado e executar através de vários dias.
Usamos a engine Stockfish como ponto de partida para avaliar a qualidade das posições. Contrário ao que se pensava na segunda entrega do trabalho, é a Stockfish é open-source e pode ser instalada e usada gratuitamente. A Stockfish é uma das melhores engines de Xadrez em uso na atualidade.
A avaliação de uma partida consiste em uma sequência dos escores de cada uma das suas posições, na ordem das jogadas. O escore de uma posição é medido em "centi-peões", o que significa que um valor de 100 equivale a uma vantagem média de um peão. Um escore positivo significa posição melhor para as peças brancas, enquanto que um escore negativo significa uma posição melhor para as peças pretas. Imagem obtida em Chess.com.

Uma vez que os escores das posições de uma partida são calculados, podemos gerar as seguintes métricas:
- TTB (time to blunder): número de lances até o primeiro blunder.
- NB (number of blunders): número de blunders cometidos na partida.
- Média dos escores na partida.
- Desvio-padrão dos escores na partida.
Definimos um blunder como um lance que resulta numa posição pior para o jogador que a executou em pelo menos 250 centi-peões. Essa definição não é canônica no jodo de Xadrez, apenas escolhida com base na nossa intuição de quanto um lance "ruim" piora a posição.
A ideia é usar as anotações de lances (ex: Nf3, e4, Be7) como palavras individuais em um texto para servir de tokens. Daí um modelo autorregressivo tipo BERT e/ou GPT seria treinado a partir dessa tokenização.
Quando usamos um CLM, a parte generativa (decoder) retorna a probabilidade de cada palavra no vocabulário dadas as palavras anteriores (prompt). Usaremos os escores da saída do método generate para criar partidas baseadas em diferentes estratégias de amostragem. A mais simples delas é a greedy, onde cada novo token é gerado e concatenado aos últimos. Outra forma de amostrar sequências de tokens consiste em pegar os próximos k tokens com maior probabilidade conjunta (dados os anteriores). O caso onde k = 1 equivale ao greedy.
Nossa geração de partidas possui três parâmetros principais:
- O tamanho do lookahead na busca por jogadas, sendo 1, 2 ou 3.
- O lance inicial (start) das peças brancas, sendo "e4", "d4", "c4" ou "Nf3".
- O número de repetições dados os parâmetros acima. Esse valor é igual a 10.
outputs = model.generate(
input_ids,
do_sample=False,
max_length=len(input_ids[0]) + 1,
output_scores=True,
return_dict_in_generate=True,
pad_token_id=tokenizer.eos_token_id
)
A biblioteca python-chess, é útil para validar as saídas do modelo, de modo que apenas partidas válidas sejam geradas.
- Python 3.7 ou superior.
- Google Colab para suporte à execução de notebooks na nuvem com GPU.
- Biblioteca python-chess para processar as partidas no formato PGN.
- Biblioteca Hugginface Transformers para carregar e treinar os modelos de linguagem.
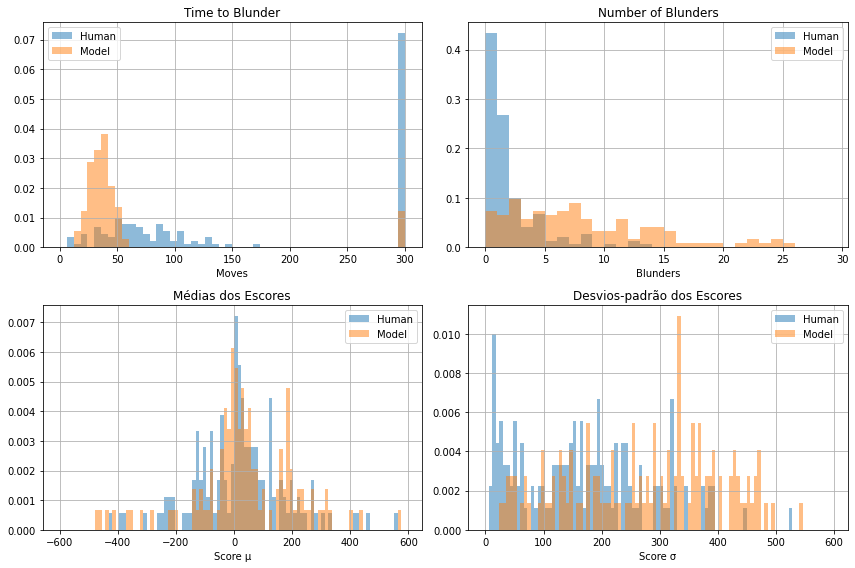
A seguir comparamos as distribuições de partidas entre humanos com a distribuição de partidas sintéticas. Não fazemos uma comparação explícita com as engines pelo fato de que a própria engine é usada para gerar os escores das posições. Isso significa que uma engine sempre atribuiria alto valor para suas próprias jogadas e faria partidas "perfeitas" sob seu ponto de vista.
Podemos notar que o primeiro blunder tende a ocorrer, em média, mais cedo do que nos jogos humanos, apesar de que há mais jogos humanos com blunder nos 10 primeiros lances do que nos jogos sintéticos. Acreditamos que isso se deva ao fato de que o modelo aprende bem as aberturas, mas comete erros logo em seguida. Já os humanos tendem a saber aberturas mas eventualmente esquecem partes, principalmente em aberturas mais longas, compensando depois no meio-jogo e nos finais.
A média dos escores tende a ter o mesmo comportamento entre as partidas reais e as sintéticas. A moda próxima a 0 indica o equilíbrio entre as peças brancas e pretas, apesar das brancas possuirem uma leve vantagem inicial. Já o intervalo dos desvios-padrão é maior nas partidas sintéticas, refletindo o fato de que o número de blunders maior gera mais oscilação na sequência de escores de cada partida.
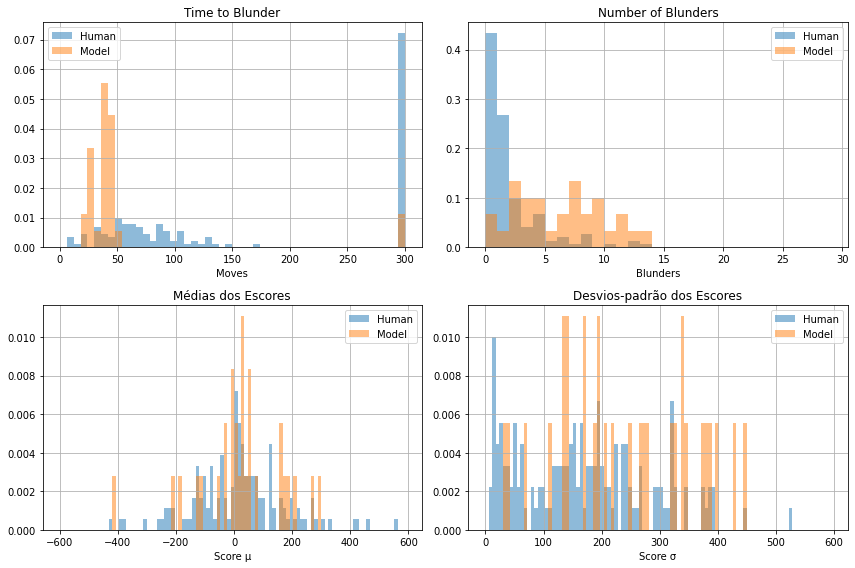
A seguir temos a mesma comparação só que com as partidas geradas com lookeahead = 3. Nesse caso, podemos dizer que as partidas geradas tem melhor qualidade que aquelas com lookahead 1 ou 2, pois tiveram mais profundidade na amostragem dos lances. Essa qualidade é refletida da distribuição dos blunders, pois tendem a possuir menos blunders que as de lookahead 1 e 2, mesmo que ainda não alcance as partidas de humanos. Na mesma linha de raciocínio, o Time to Blunder parece aumentar nessa parte das partidas sintéticas, assim como o intervalo dos desvios-padrão parece diminuir.
Assim como nas partidas com lookahead 1 e 2, essas possuem um bom reportório de aberturas.
A seguir temos alguns exemplos dentre as melhores (maior TTB e menor NB) partidas sintéticas (clique para visualizar isoladamente). Podemos perceber que são partidas que terminam em empate. De certa forma, é mais comum que partidas sem lances errados terminem empatadas.
As três primeiras partidas (de cima pra baixo e da esquerda para a direita) são posições similares às de Abertura Inglesa. A quarta possui posição similar ao Gambito da Dama negado, embora a ordem dos lances seja diferente. Gifs obtidos em Chess.com.
.gif)
.gif)
.gif)
.gif)
.gif)
.gif)
Neste trabalho, apresentamos um modelo autoregressivo baseado em Transformer treinado para gerar partidas de Xadrez jogadas entre humanos em torneios. Nosso objetivo era que essas partidas sintéticas parecessem "naturais", ao contrário das engines. Para tanto usamos as avaliações numéricas da engine Stockfish para comparar as partidas reais e as sintéticas. Observamos que o modelo autoregressivo é capaz de aprender uma boa variedade de aberturas e executá-las perfeitamente, mas sofre degradação do jogo a partir do meio-jogo e tem dificuldade em executar lances básicos nos finais de partida. Por outro lado, alguns parâmetros da amostragem dos lances podem ser ajustados para conseguir partidas melhores, mas com custo computacional exponencialmente crescente. Para trabalhos futuros é possível investigar as partidas nessas configurações mais profundas, com modelos de maior capacidade treinados por mais tempo e com mais dados.
- "Standard: Portable Game Notation Specification and Implementation Guide". 12 March 1994.
- "Language Models are Few-Shot Learners" (2020). Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, Dario Amodei.
- "Evaluating Large Language Models Trained on Code" (2021). Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian, Clemens Winter, Philippe Tillet, Felipe Petroski Such, Dave Cummings, Matthias Plappert, Fotios Chantzis, Elizabeth Barnes, Ariel Herbert-Voss, William Hebgen Guss, Alex Nichol, Alex Paino, Nikolas Tezak, Jie Tang, Igor Babuschkin, Suchir Balaji, Shantanu Jain, William Saunders, Christopher Hesse, Andrew N. Carr, Jan Leike, Josh Achiam, Vedant Misra, Evan Morikawa, Alec Radford, Matthew Knight, Miles Brundage, Mira Murati, Katie Mayer, Peter Welinder, Bob McGrew, Dario Amodei, Sam McCandlish, Ilya Sutskever, Wojciech Zaremba.
- "DeepSVG: A Hierarchical Generative Network for Vector Graphics Animation" (2020). Alexandre Carlier, Martin Danelljan, Alexandre Alahi, Radu Timofte.
- "Generating Music Transition by Using a Transformer-Based Model" (2021). Jia-Lien Hsu and Shuh-Jiun Chang.
- The Chess Transformer: Mastering Play using Generative Language Models (2020). David Noever, Matt Ciolino, Josh Kalin.
- The Go Transformer: Natural Language Modeling for Game Play (2020). Matthew Ciolino, David Noever, Josh Kalin.
- Attention Is All You Need (2017). Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin.
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (2018). Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova.