Zip #2012
Zip #2012
Conversation
|
@lainsworth8801 -- thanks for the PR. Can you add the issue ID into the PR description? That way we know what issue to test. Thanks! |
…r property and taxlot postal code.
There was a problem hiding this comment.
Thanks for the updates! I made a small change to support the owner postal code as well.
Is a zip code of 0 suppose to stay 0 or resolve to 00000?
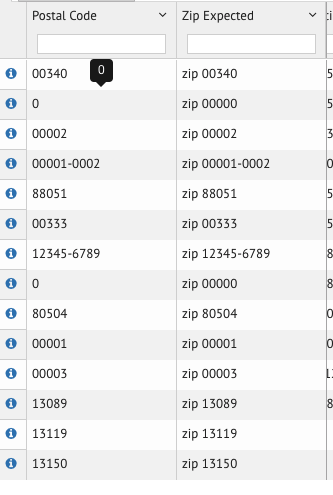
Also, note that the mapping screen does not pad the zip codes; however, I think this is right because the user is seeing the raw data from the spreadsheet. Once they choose to map to postal code then it will get converted.

Also, do you think we should go back and update all the zip codes in the database with a migration (and rehash)? I think this is mostly a question for @adrian-lara, @axelstudios and/or @ClearlyEnergy.
| if '-' in ts.postal_code: | ||
| self.assertEqual(len(ts.postal_code.split('-')[0]), 5) | ||
| self.assertEqual(len(ts.postal_code.split('-')[1]), 4) | ||
| self.assertEqual(ts.postal_code.split('-')[0].lstrip('0'), |
There was a problem hiding this comment.
making these explicit checks would be nice, (i.e., something like self.assertEqual(ts.postal_code.split('-')[0].lstrip('0'), '05005'))
There was a problem hiding this comment.
I can change that. Was thinking about doing a general format check instead of spot checking.
There was a problem hiding this comment.
For whether '0' zip should stay '0' or be packed with 0s, my reason of packing it with 0s is to show users that this is supposed to be a zip code but it's 0. Although I'm not sure if this is a better idea than leaving it as it is which is just a single digit 0.
There was a problem hiding this comment.
Yeah, I think we want this to be packed, that is 0 -> 00000. Right now it doesn't appear to do that.
seed/lib/mcm/mapper.py
Outdated
| table_name, mapped_column_name, display_name, is_extra_data = mapping.get(raw_column_name) | ||
|
|
||
| # special postal case: | ||
| if mapped_column_name == 'postal_code': |
|
That would be nice. Thank you. It allows the developer to see what it is expecting instead of having to .split and .zfill.
|
seed/lib/mcm/mapper.py
Outdated
| if mapped_column_name in ['postal_code', 'owner_postal_code']: | ||
| if column_value: | ||
| if '-' in str(column_value): | ||
| postal = str(column_value).split('-')[0].zfill(5) |
There was a problem hiding this comment.
Thanks for catching the owner_postal_code.
There was a problem hiding this comment.
@nllong I recalled wrong...the reason it's not packing 0 zip with 0s is because i checked column_value here before I convert. Will change that.
I think a migration to update zip codes on pre-existing records and recalculating |
| ext = str(column_value).split('-')[1].zfill(4) | ||
| column_value = postal + '-' + ext | ||
| column_value = str(column_value).zfill(5) | ||
| if '-' in str(column_value): |
|
Yeah, I like the idea of a migration to fix existing data and then rehash |
|
@axelstudios -- I would like testing the migration on existing data to be something that is in the Test column of the Dec 19 Github project. Not sure how to do that, but if a PR comes through for that migration, I will add it to the Test column. |
|
@lainsworth8801 -- can you add in a migration for this? See this as an example: https://github.com/SEED-platform/seed/blob/develop/seed/migrations/0111_rehash.py |
Hey @lainsworth8801 -- can you implement this rehashing migration before we merge this PR? |
|
@nllong yes sorry was gonna work on this next |
There was a problem hiding this comment.
@lainsworth8801 Thanks! Did you test running this migration on a dump of the existing production database?
|
I only ran it on my local db which is a very small size db. i'll add a run on the production. |
Thanks. Mainly concerned because you are updating the postal codes here and want to make sure that it works. What if postal code is a number/string/double/etc. |
Back tracking on this previous comment after conversations with Lin and a closer look at the proposed migration. I don't think an additional rehashing is needed after updating the @nllong @axelstudios What do you guys think? |
|
I think you are right @adrian-lara. Since we are calling .save(), then we only need to find the records that need to be updated. I think we should run with SQL (or Django)... something like: I did not test the above command... but this would save iterating over all the records. |
|
|
||
| property_sql = ( | ||
| "UPDATE seed_propertystate " + | ||
| "SET created = seed_propertyauditlog.created, updated = seed_propertyauditlog.created " + |
There was a problem hiding this comment.
I think we'd only need to restore the updated field and not the created field here and in the tax lot query.
There was a problem hiding this comment.
I actually think we don't need to SET the created nor updated field in either of these... just the postal_code, right?
There was a problem hiding this comment.
I updated my comment (meant to switch created and updated). I'd think we'd need to "revert" the updated field since changing postal_codes one at a time using save() will change the updated time for each record.
There was a problem hiding this comment.
I guess, I'm just assuming we wouldn't actually want the updated times to change, but I could definitely understand wanting those values to change.
There was a problem hiding this comment.
Ah, that makes sense. I think it is okay if the updated times change as it really is a change.
Yeah something like that would help decrease the number of records getting updated. |
We need to handle the rehash better. See comments in the PR.
|
@lainsworth8801 -- did you have a chance to update this rehash method to filter down to only the fields that are going to be updated? Let me know if you can get to it otherwise I'll work on it. |
|
@nllong was trying to fix the Xcode version issue for timescales on Friday to work on this but didn’t get far. I’ll be back on Monday it could wait through the weekend. My apologies. |
|
@lainsworth8801 I just updated the migration to fix the dependency error. I think this PR is really close can you update the migration to only find records that have 4 zip code characters and update only those records? As Adrian points out you only need to run .save() to have the hash get updated. Note that you probably will need to recreate your local database since I merged in some other db migrations. |
|
@nllong definitely. Thanks nick. |
Issue #1480
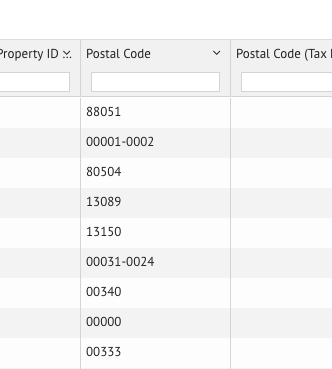
Added leading zeros for postal codes under 5 digits;
Added leading zeros for postal codes with 4 digits extension;
Added test excel sheet with postal codes added (fake column name for user mapping purpose).
original uploaded:
