The purpose of this analysis was to create a binary classifier that is capable of predicting whether appplicants would be successful if funded by the Alphabet Soup Company.
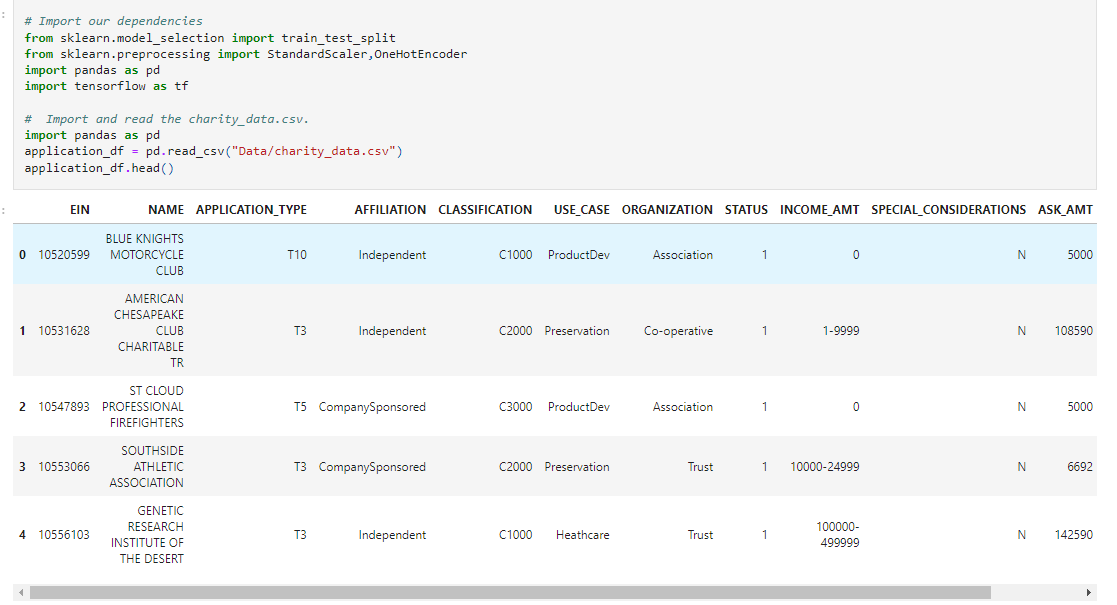
The data provided was a CSV file that contained organization data. A preview of the CSV file is below and can be found in the "Data" folder of this repo.
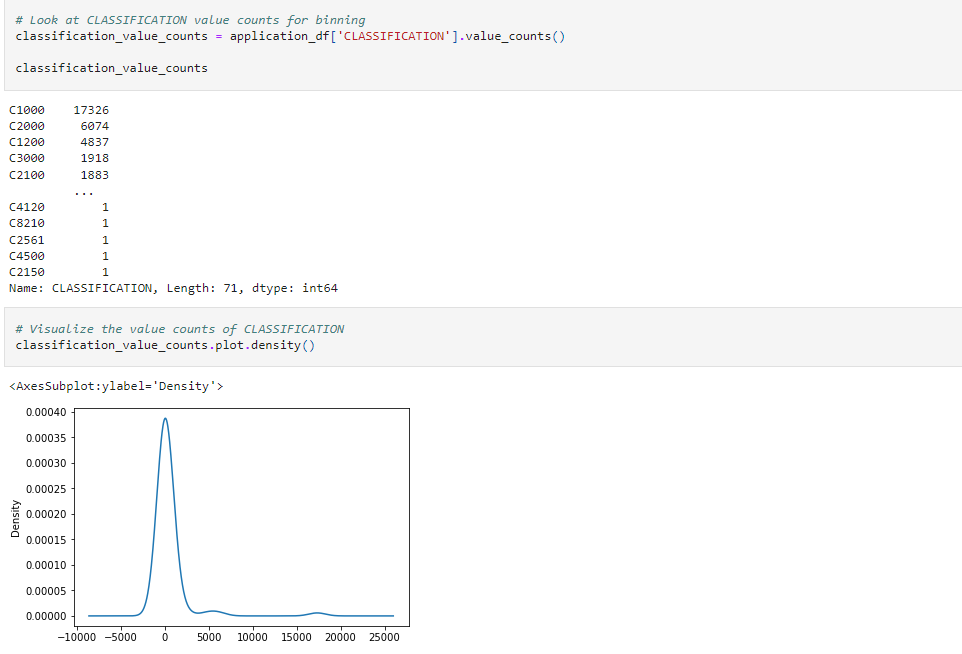
In the first iteration of the model created the first steps taken were removing unnecessary information from the CSV. That included the "Ein" and the "Name" column. The next step after checking unique values and also counting the values for each remaining column was to determine the appropriate number using a density chart for binning large values. The below example is for the Application column but the same process was done for the Classification column. Both columns had more that 10 values in comparision to the rest of the columns.
The Categorical data was encoded and the original values were dropped. Once the data was preprocessed the new dataset was split into training and testing sets.
The first iteration of the model had two hidden layers. The first layer contained 200 neurons and the second contained 150. The number of neurons was determined based on the number of features. The first layer had a "relu" activation model and the second layer had a "sigmoid" activation. Once compiled and trained for 100 epochs the accuracy score was about 48%.

For many of the attempts the pre-processing steps were the same. There was an attempt in the first new attempt to remove more data that was thought to be unnecessary. The "Use_Case" and "Application_Type" was also dropped.
The new model was run with significantly less neurons. Layer 1 had 10 and layer 2 had 5. The rest of the model remained the same.
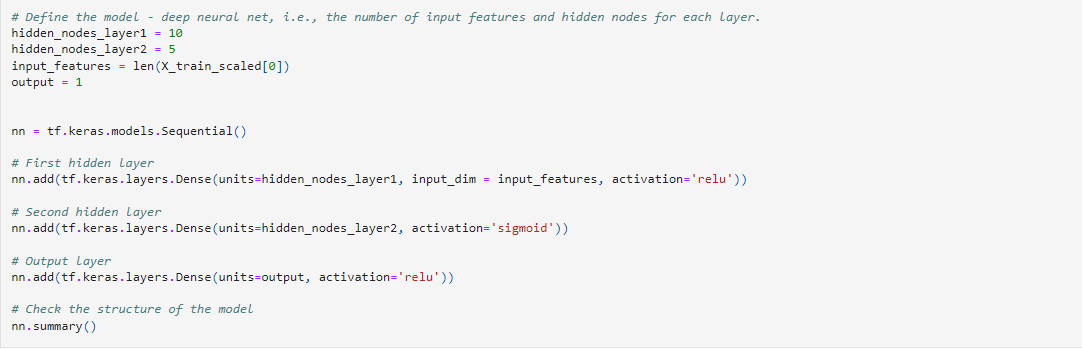
After compiling and training to test data the model only increased by 1% in accuracy.
In the second attempt the pre-processing and model stayed mostly the same. This time the second layer changed from "sigmoid" to "relu" activation and the output layer was changed to "sigmoid"
This was the first change that brought the accuracy of the model up 10% to 56%. This ended up being the best performing model.

There were a few more attempts that included shuffling activation models, and neuron amounts to see if that helped. The worst performing model had an additional layer added, so 3 in total and the accuracy score shot down to 42%.
Unfortunately, this model needs more exploring and fleshing out. I think a better look at what features may or may not be important or beneficial to the model would need to be explored as well as more trial and error in model formation.