{kind=link}
{kind=link}
This time, I created an NLP-based project which you can use to solve a very famous problem of topic modeling in NLP with the help of the LDA model.
LDA (Latent Dirichlet Allocation) is a powerful technique used for topic modeling. It teaches us that every document is comprised of several different topics, and each topic consists of similar words. For example, if you are reading about a topic related to football, the possibility of words like "child labor" and "murder" may be very low or even zero. Conversely, if you are reading about topics related to crime, these words might be more common.
LDA uses a similar approach in this context.
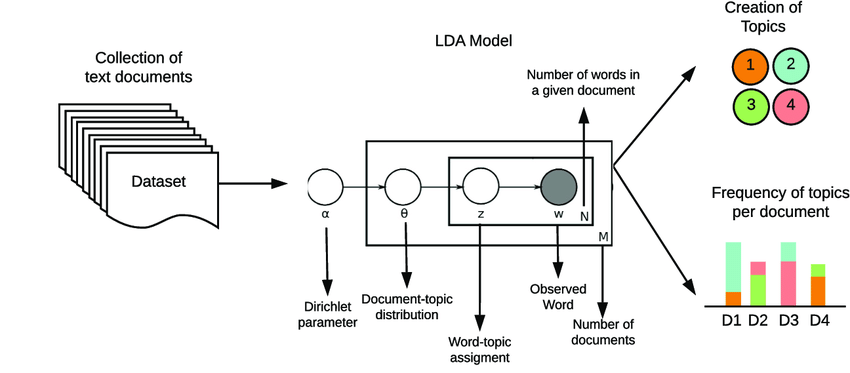
LDA is an unsupervised learning technique that does not require labeled data and is helpful for tasks such as document classification, information retrieval, and recommender systems.
LDA is a probabilistic graphical model that represents the probability distributions of observed and hidden variables and their dependencies using graphs. In LDA, the observed variables are the words in the documents, and the hidden variables are the topics and topic proportions. The graphical representation of LDA allows us to visualize and understand the complex relationships between the variables.
In LDA, the Dirichlet distribution is used to model the distribution of topics in each document and the distribution of words in each topic.
The generative process of LDA is a probabilistic model that describes how a corpus of documents is generated. It assumes that each document is a mixture of latent topics, and each topic is a distribution over words. The generative process is as follows:
For each document ( d ) in the corpus:
- Choose a distribution over topics ( \theta_d ) from a Dirichlet distribution with parameter ( \alpha ).
- For each word ( w ) in the document:
- Choose a topic ( z_d ) from the distribution ( \theta_d ).
- Choose a word ( w ) from the topic ( z_d ).
The generative process assumes that each document is generated independently of the others, and the same set of topics is used across all documents. By assuming a generative process for the data, LDA allows us to infer the latent variables that generate the observed data and discover the underlying topics in the corpus.
LDA requires some preprocessing of the raw text data before the model can be trained. Preprocessing steps can significantly affect the quality of the results obtained from LDA. These steps include:
- Stop Words Removal
- Lemmatization and Stemming
- Tokenization
- Other techniques for data preparation
There are total 5 api endpoints for news article, research topics and for getting topic dictionary
{kind=link}
{kind=link}
{kind=link}
To use LDA in your own system, follow these steps:
You will need Python libraries such as gensim, nltk, and spacy. You can install these libraries using pip:
pip install gensim nltk spacy