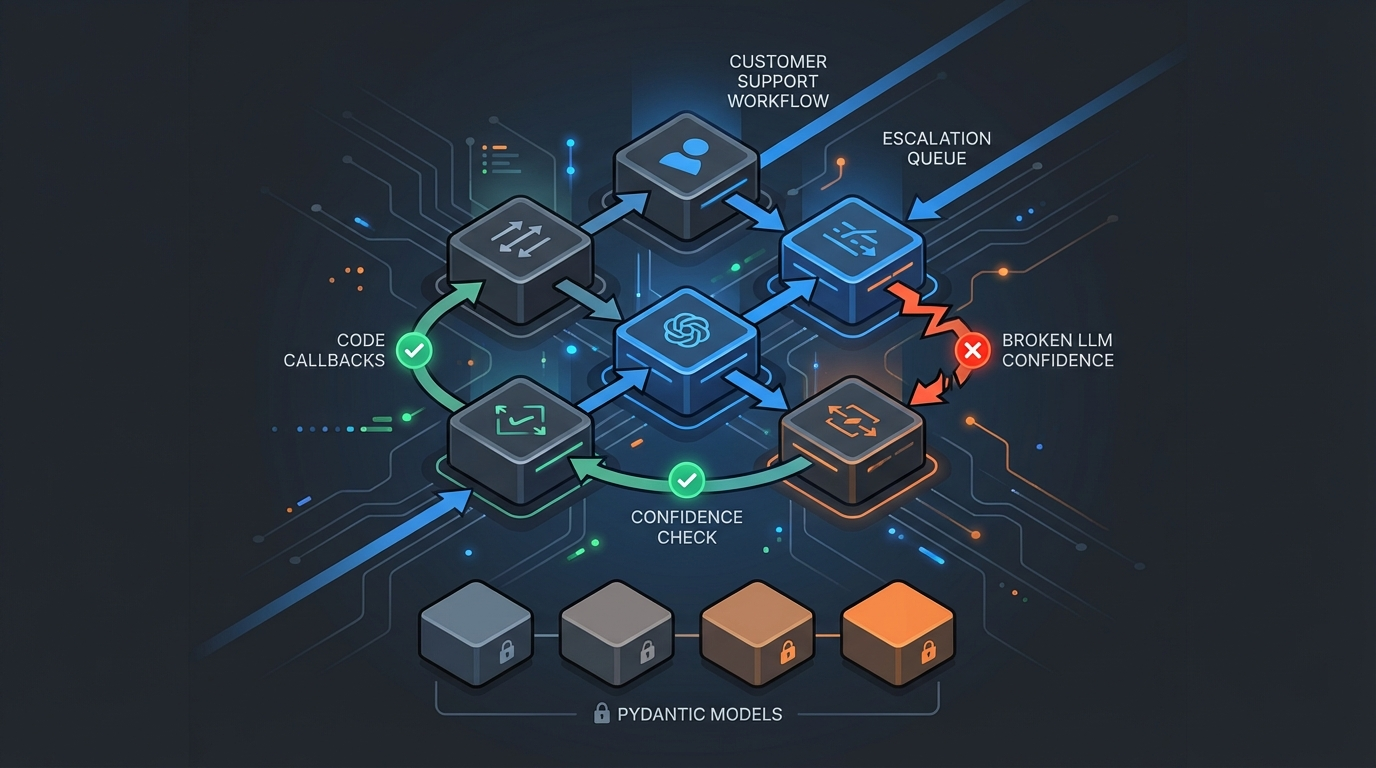
Production Claude Agent Architecture

Six CCA-exam-ready architectural patterns, full Pydantic + callback enforcement, negative-bound tools, prompt caching, and deterministic escalation. Zero trust in the LLM's memory.
Here's the uncomfortable truth about Claude agents: the model will not reliably remember your business rules. I learned this building customer-support agents that happily processed $600 refunds for Regular-tier customers until I moved the rules into code.
In this article I'll show you the exact Python package I built; complete with Pydantic models, callback-enforced policies, negative-bound tools, and six production patterns that are also CCA-exam gold. By the end you'll have a blueprint you can ship tomorrow.
This is Part 1 of the "Production Claude Agents" series. Full source code + 8 Jupyter notebooks: github.com/SpillwaveSolutions/cca-exam-prep-customer-support
Exam-prep note: This course uses CCA-F (Claude Certified Architect; Foundations) exam framework as a teaching device. All architectural patterns are grounded in real Anthropic SDK behavior and production best practices.
- Why programmatic enforcement (callbacks, typed models) beats prompt-based guidance every time
- The six CCA architectural patterns with anti-pattern vs. correct code side-by-side
- How to build 5 focused tools with negative-bound descriptions that prevent LLM misrouting
- Two-step vetoable execution for high-stakes operations (refunds that can be blocked mid-flight)
- Prompt caching that cuts costs 90% vs. the Batch API anti-pattern
- Structured handoffs (~200 tokens) vs. raw conversation dumps (~2,000+ tokens)
- A 234-test suite that verifies stores, not API responses

Every section in this article maps back to one of these six patterns. This is your roadmap:
-
Pattern 1: Escalation ; Deterministic rules in
callbacks.py(4 conditions, binary block/allow) vs. LLM confidence routing where Claude self-reports and skips escalation - Pattern 2: Compliance ; Pre-handler regex redaction where the audit log never sees raw PII vs. prompt-only PII rules where Claude "usually" complies
- Pattern 3: Tool Design ; 5 focused, non-overlapping tools with negative bounds vs. 15-tool Swiss Army where overlapping tools cause misrouting
-
Pattern 4: Context Management ;
ContextSummarywith 300-char budget and automatic compaction vs.RawTranscriptContextwith unbounded O(n) growth -
Pattern 5: Cost Optimization ; Prompt caching on ~4,100-token
POLICY_DOCUMENT(up to 90% savings) vs. Message Batches API for live support (50% savings, 24-hour latency) -
Pattern 6: Handoffs ;
EscalationRecord(8 fields, ~200 tokens) forced viatool_choicevs. rawmessagesdump (~2,000+ tokens)
The meta-principle running through all six: programmatic enforcement beats prompt-based guidance. The system prompt tells Claude what to do. Code guarantees it happens.
The project has two layers:
-
The Python package (
src/customer_service/); production-quality implementation with only correct patterns. -
The anti-patterns (
src/customer_service/anti_patterns/); deliberately wrong implementations that show what happens when you ignore the guidance.
Why study the wrong way? Because understanding why it fails is how you internalize the right way.
src/customer_service/
models/ Pydantic data models (the nouns)
services/ 5 simulated business services (the verbs)
data/ Seed customers and test scenarios
tools/ Claude API tool schemas + per-tool handlers
agent/ The agentic loop, callbacks, prompts, context, coordinator
anti_patterns/ 6 deliberately wrong implementations
The data flows like this:
Customer message
-> agent_loop.py calls client.messages.create()
-> Claude returns tool_use blocks
-> callbacks.py validates each tool call against business rules
-> if approved: handlers.py dispatches to the correct tool handler -> service call
-> if blocked: error returned as tool_result, agent retries or escalates
-> loop continues until stop_reason != 'tool_use'

What drives this loop? When stop_reason equals "tool_use", Claude is telling you "I want to call a tool, execute it and give me the result" [Anthropic Docs ; Handling Stop Reasons, 2025]. The loop terminates when stop_reason returns "end_turn", meaning Claude is done talking. Get comfortable with this loop. It's the foundation for building any production agent.
Every layer enforces a principle:
- Models: Type safety via Pydantic ; invalid data is rejected at construction
- Services: Deterministic business logic ; no LLM reasoning in policy checks
- Tools: Exactly 5 focused tools with negative-bound descriptions
- Callbacks: Programmatic enforcement ; business rules in code, not prompts
- Agent Loop: Stop-reason-controlled loop with forced escalation on blocked refunds
- Coordinator: Context isolation ; subagents see only explicit context strings
File: src/customer_service/models/customer.py
Every data structure in the system is a Pydantic BaseModel. This isn't a style preference. Pydantic gives you runtime type validation, which means invalid data blows up at construction time rather than silently corrupting downstream logic [Pydantic Docs , Fields, 2025]. Violate a constraint? Pydantic raises a ValidationError immediately. The problem surfaces at the boundary, not three layers deep where you'll spend an hour debugging it.

class CustomerTier(StrEnum):
BASIC = "basic"
REGULAR = "regular"
PREMIUM = "premium"
VIP = "vip"StrEnum (Python 3.11+) means each variant is both an enum member and a string [Python Docs ; enum.StrEnum, 2025]. You can pass CustomerTier.VIP anywhere a string is expected, and it serializes cleanly to JSON. The tier drives policy limits : BASIC/REGULAR get $100, PREMIUM gets $500, VIP gets $5,000.
Python version note:
StrEnumis available natively in Python 3.11+ [Python Docs : enum.StrEnum, 2025]. For earlier versions, use thestr, Enummixin:class CustomerTier(str, Enum). This mixin was the established workaround beforeStrEnumwas formalized as a built-in base class.
The tier is not just a label ; it is the key that unlocks the correct policy row in PolicyEngine. Get the tier wrong and the refund limit is wrong. Encoding it as a StrEnum member means CustomerTier("vip") works, CustomerTier.VIP == "vip" is True, and JSON serialization produces clean lowercase strings without extra conversion code. This works because StrEnum uses str.__str__() and str.__format__() implementations specifically to support the replacement-of-existing-constants use case [Python Docs ; enum.StrEnum, 2025].
class CustomerProfile(BaseModel):
customer_id: str
name: str
email: str
tier: CustomerTier
account_open: bool = True
flags: list[str] = Field(default_factory=list)The flags field is where non-tier escalation triggers live. A customer flagged with "account_closure" triggers immediate escalation regardless of refund amount. This is a deliberate design choice: the escalation logic in callbacks.py reads flags from the profile, making the trigger data-driven rather than hardcoded to specific customer IDs.
The default_factory=list on flags matters more than it looks. It generates a fresh list for each CustomerProfile instance [Pydantic Docs ; Fields, 2025]. Use a bare [] instead? Every instance shares the same list object (think one shopping cart for all your customers). That's the classic Python mutable-default bug, and default_factory kills it dead.
When you add a new escalation trigger in the future ; say, "media_escalation" ; you add it to a customer's flags list and update the callback's check. You never touch a list of customer IDs buried in business logic code.
class RefundRequest(BaseModel):
customer_id: str
order_id: str
amount: float = Field(gt=0)
reason: strNotice gt=0 on the amount field. Pydantic enforces this at construction ; you simply cannot create a RefundRequest(amount=-50) [Pydantic Docs ; Fields, 2025]. Try it and you get a ValidationError right at instantiation. This is boundary validation at the model layer, exactly where it belongs. Why does this matter? A negative refund amount would silently credit the company instead of the customer. Catch it at the boundary and you get a clear error message. Miss it, and you get a confusing financial anomaly three services downstream.
class PolicyResult(BaseModel):
approved: bool
limit: float
requires_review: boolThree fields from the PolicyEngine: is this within the tier limit? What is the limit? Does it exceed the $500 review threshold?
The requires_review flag is independent of approved : a VIP requesting a $4,000 refund is approved (under the $5,000 limit) but still requires review (above $500). These two booleans can be in any combination:
- True: False | Process normally
- True: True | Process, but escalation callback will block for supervisor review
- False: True | Over tier limit AND over review threshold
- False: False | Over tier limit, under $500 (e.g., Regular requesting $150)
class EscalationRecord(BaseModel):
customer_id: str
customer_tier: str
issue_type: str
disputed_amount: float
escalation_reason: str
recommended_action: str
conversation_summary: str
turns_elapsed: intThis is the structured handoff pattern in action. When a case escalates to a human agent, they get exactly these 8 fields ; not a raw conversation dump. No noise. Every field earns its place:
-
customer_tiertells the human agent what service level applies -
escalation_reasonexplains why the AI couldn't handle it -
recommended_actiongives the human a starting point -
turns_elapsedsignals conversation fatigue ; a customer on turn 8 needs faster resolution than one on turn 2
Think about the difference. Eight structured fields versus a raw conversation dump. The structured record gives the human agent exactly what they need to act. The dump? It buries those same facts inside tool artifacts and repeated context, burning tokens while the reader hunts for signal in the noise.
class InteractionLog(BaseModel):
customer_id: str
action: str
details: str
timestamp: strEvery tool call gets logged. Why is the details field a JSON string instead of a raw dict? Because the compliance callback needs to regex-scan it for PII before it hits the audit log. If details contained a nested Pydantic model, redaction would need to understand model structure. A flat JSON string keeps redaction dead simple.
Directory: src/customer_service/services/
Why five separate services instead of one big class? Because each one owns exactly one concern. The project simulates five business services that a real customer support system would integrate with. All are in-memory ; no infrastructure setup required.
class CustomerDatabase:
def __init__(self, customers: dict[str, CustomerProfile]) -> None:
self._customers = {k: v.model_copy() for k, v in customers.items()}
def get_customer(self, customer_id: str) -> CustomerProfile | None:
profile = self._customers.get(customer_id)
return profile.model_copy() if profile is not None else NoneTwo defensive copies here, and both matter. The constructor copies each profile so the original CUSTOMERS dict stays clean. The get_customer method returns a copy so callers can't accidentally modify the database. I've seen this exact bug in real systems: run two test scenarios back-to-back and the second one fails because the first mutated shared state.
model_copy() returns a new model instance that is a shallow copy by default [Pydantic Docs ; Models, 2025]. Nested objects share the same reference unless deep=True is passed. For CustomerProfile ; which contains only scalar fields and a flat list[str] ; a shallow copy is sufficient to achieve the defensive-copy goal here.
Why not just use a raw dict? Because CustomerDatabase establishes a contract: look up customers by ID, get a CustomerProfile or None. That's it. That's the interface tool handlers depend on. Swap this for a real database later and only this class changes. The tool handlers don't know. They don't care.
class PolicyEngine:
_REFUND_LIMITS: dict[CustomerTier, float] = {
CustomerTier.BASIC: 100.0,
CustomerTier.REGULAR: 100.0,
CustomerTier.PREMIUM: 500.0,
CustomerTier.VIP: 5000.0,
}
_REVIEW_THRESHOLD = 500.0
def check_policy(self, tier: CustomerTier, requested_amount: float) -> PolicyResult:
limit = self._REFUND_LIMITS[tier]
approved = requested_amount <= limit
requires_review = requested_amount > self._REVIEW_THRESHOLD
return PolicyResult(approved=approved, limit=limit, requires_review=requires_review)This is pure deterministic logic. No LLM reasoning. No probability. No prompt. Given a tier and amount, the result is always the same. Here's the central principle in its purest form: business rules belong in code, not in system prompts. Full stop.
The _REVIEW_THRESHOLD is 500.0 and applies to all tiers. A VIP requesting $4,000 is approved (under $5,000 limit) but still flagged for review (above $500). The escalation callback in callbacks.py reads requires_review and blocks the refund, forcing escalation.

class FinancialSystem:
def __init__(self) -> None:
self._processed: list[dict] = []
def process_refund(self, customer_id, order_id, amount, policy_approved=True) -> dict:
if policy_approved:
result = {"status": "approved", ..., "refund_id": f"REF-{len(self._processed) + 1:04d}"}
else:
result = {"status": "rejected", ..., "reason": "Policy check failed"}
self._processed.append(result)
return resultThe FinancialSystem trusts the caller. It does not re-check policy ; it accepts a policy_approved boolean and acts accordingly. This is a deliberate design decision: the PolicyEngine is the single source of truth for policy, and FinancialSystem is the single source of truth for financial state. Separation of concerns.
The _processed list is the persistent state that tests verify. When we test that a blocked refund doesn't write to FinancialSystem, we check len(services.financial_system.get_processed()) == 0. This is the behavior-first testing principle: test the store, not the API response.
class EscalationQueue:
def __init__(self) -> None:
self._queue: list[EscalationRecord] = []
def add_escalation(self, record: EscalationRecord) -> None:
self._queue.append(record)Simple append-only queue. When the escalate_to_human tool fires, the structured EscalationRecord lands here. Tests verify the queue has the expected entries with the expected fields.

class AuditLog:
def __init__(self) -> None:
self._entries: list[InteractionLog] = []
def log(self, entry: InteractionLog) -> None:
self._entries.append(entry)Append-only compliance trail. The compliance callback redacts PII before entries reach this log. Tests verify that no credit card numbers appear in audit_log.get_entries() ; they check the store, not the tool response.
@dataclass(frozen=True)
class ServiceContainer:
customer_db: CustomerDatabase
policy_engine: PolicyEngine
financial_system: FinancialSystem
escalation_queue: EscalationQueue
audit_log: AuditLogA frozen dataclass holding all five services. frozen=True means you cannot reassign fields after construction ; attempting to do so raises a FrozenInstanceError (a subclass of AttributeError) [Python Docs ; dataclasses, 2025]. The container is effectively immutable. Every tool handler receives this single object and accesses exactly the services it needs. Services are never imported directly in tool modules.
This is dependency injection (think Spring's @Autowired, but explicit and frozen). Want to swap CustomerDatabase for a real database in production? Construct a different ServiceContainer. The tool handlers don't change. Testing gets easy too ; pass in-memory services for unit tests, real services for integration tests. Same container interface either way.
Directory: src/customer_service/data/
CUSTOMERS: dict[str, CustomerProfile] = {
"C001": CustomerProfile(customer_id="C001", name="Alice Johnson",
tier=CustomerTier.REGULAR),
"C002": CustomerProfile(customer_id="C002", name="Bob Chen",
tier=CustomerTier.VIP),
"C003": CustomerProfile(customer_id="C003", name="Carol Martinez",
tier=CustomerTier.REGULAR),
"C004": CustomerProfile(customer_id="C004", name="David Kim",
tier=CustomerTier.REGULAR, flags=["account_closure"]),
"C005": CustomerProfile(customer_id="C005", name="Eva Nowak",
tier=CustomerTier.REGULAR),
"C006": CustomerProfile(customer_id="C006", name="Frank Osei",
tier=CustomerTier.VIP, flags=["account_closure"]),
}Six customers, each designed to trigger specific escalation paths:
- C001: Regular | ; | Happy path ($50 refund within $100 limit)
- C002: VIP | ; | VIP escalation trigger
- C003: Regular | ; | Amount threshold ($600 > $500 review)
- C004: Regular | account_closure | Account closure escalation
- C005: Regular | ; | Legal keyword escalation (in message)
- C006: VIP | account_closure | Multi-trigger (VIP + closure + large amount)
C006 (Frank Osei) is the stress test. He is VIP and has an account_closure flag. Any refund request from Frank trips at least two escalation rules simultaneously. This multi-trigger scenario verifies that the escalation callback handles compound conditions correctly ; not just single-flag cases.
SCENARIOS: dict[str, dict] = {
"happy_path": {
"customer_id": "C001",
"message": "I'd like a $50 refund for order #ORD-001. The item was defective.",
"expected_tools": ["lookup_customer", "check_policy", "process_refund", "log_interaction"],
"expected_outcome": "refund_approved",
},
"amount_threshold": {
"customer_id": "C003",
"message": "I need a $600 refund for my damaged order.",
"expected_tools": ["lookup_customer", "check_policy", "escalate_to_human"],
"expected_outcome": "escalated_amount",
},
# ... 4 more scenarios
}Each scenario documents its expected tool chain and outcome. This makes scenarios both teaching artifacts (students can trace the expected flow) and test oracles (automated tests can verify the actual flow matches).
Notice the amount_threshold scenario: $600 for a REGULAR customer. The $100 tier limit means approved=False. The $500 review threshold means requires_review=True. Both trigger escalation. The scenario message includes the customer ID prefix so Claude calls lookup_customer immediately without asking for clarification.
The scenarios are designed so that each one demonstrates exactly one primary escalation path. Students working through notebooks can run each scenario in isolation and see a clean, focused demonstration of the trigger they are studying.
Next: Part 2 covers the tool layer ; how Claude is told what it can do, and how Claude tool use calls are executed through the dispatch registry.

File: src/customer_service/tools/definitions.py
This file defines the five tools available for Claude tool use in the agent. Anthropic's agent design guidance recommends keeping agents to 4–5 focused tools [Anthropic Docs, Build with Claude , Tool Use, 2025]. The descriptions include what the tool does and what it does not do , this is the negative-bound tool description pattern (original terminology coined in this course), and it is one of the most important things you can do to prevent Claude from misrouting calls.
class LookupCustomerInput(BaseModel):
customer_id: str = Field(description="Customer ID to look up (e.g., 'C001')")
def _make_tool(name: str, description: str, model: type[BaseModel]) -> dict:
schema = model.model_json_schema()
schema.pop("title", None) # Remove top-level 'title' for cleanliness
return {"name": name, "description": description, "input_schema": schema}Each tool's input schema is a Pydantic model. The _make_tool helper converts these to Claude API format. Here's the thing: that schema.pop("title", None) line looks innocent, but skip it and nothing works. Pydantic v2's model_json_schema() automatically generates a top-level "title" field containing the class name (e.g., "title": "LookupCustomerInput") [Pydantic Docs, JSON Schema, 2025]. Removing title is a best practice for token efficiency and schema cleanliness [Anthropic API Docs, Tool Use, 2025]. The Anthropic API may reject schemas with unsupported top-level keys ($schema, oneOf, allOf), and title adds tokens without value.
Best practice: Always pop
titlefrom Pydantic-generated schemas before passing them to the Claude API. It saves tokens and avoids potential schema validation issues with unsupported top-level keys.
Why use Pydantic as the schema source? Because the same model that defines the schema also validates the input when the handler receives it. Claude calls a tool with a missing required field? Pydantic raises ValidationError immediately [Pydantic Docs, Validation, 2025]. One model, two jobs. You cannot update the schema without updating the validation. They stay in sync by construction.
LOOKUP_CUSTOMER_TOOL = _make_tool(
name="lookup_customer",
description=(
"Look up customer profile by ID. Returns customer tier, account status, and flags. "
"does NOT modify customer data or process any requests."
),
model=LookupCustomerInput,
)Every tool description says what the tool does and what it does not do. Why bother with the negative bounds? Because without "does NOT modify customer data," Claude might call lookup_customer when it wants to update a profile. The description said "customer profile" and that looked plausible enough. Without "does NOT check policy eligibility" on process_refund, Claude skips the policy check and jumps straight to processing.
The does NOT phrases use lowercase does ; this is a deliberate style choice for consistency across all tool descriptions in this agent.
Here are the negative bounds for all five tools:
-
lookup_customer: does NOT modify customer data or process any requests -
check_policy: does NOT process the refund ; use process_refund after this -
process_refund: does NOT check policy eligibility ; call check_policy first -
escalate_to_human: does NOT process refunds or make financial changes -
log_interaction: does NOT take any action on the customer's request
Each negative bound directly addresses the most likely misroute for that tool. check_policy and process_refund are paired ; a model that confuses them would either skip the policy check or call process_refund as a dry run. The negative bounds make the boundary explicit.
Anthropic's prompt engineering documentation recommends that tool descriptions be unambiguous about scope, including what a tool will not do, to reduce the likelihood of incorrect tool selection [Anthropic Docs, Build with Claude : Tool Use, 2025].
TOOLS: list[dict] = [
LOOKUP_CUSTOMER_TOOL, # Read: retrieve customer profile
CHECK_POLICY_TOOL, # Read: evaluate refund eligibility
PROCESS_REFUND_TOOL, # Write: execute approved refund (two-step vetoable)
ESCALATE_TO_HUMAN_TOOL, # Write: transfer to human queue with structured record
LOG_INTERACTION_TOOL, # Write: compliance audit trail
]Exactly 5 tools. Need more capabilities (shipping updates, loyalty points, account management)? Use the coordinator-subagent pattern to split work across multiple focused agents. Do not expand this tool list. The Swiss Army anti-pattern (covered in Part 3) shows what happens when you do: 15 tools with overlapping responsibilities, and Claude starts misrouting calls between process_refund and file_billing_dispute, between escalate_to_human and create_support_ticket.
The 5-tool discipline is also a testing discipline. Five tools means you can write targeted tests that verify each tool fires in the expected sequence. Fifteen tools? The combinatorial space of possible tool chains explodes. The number of valid orderings for N tools scales factorially in the worst case, and systematic testing becomes impractical beyond small N.
Directory: src/customer_service/tools/
Each tool has its own handler module. All handlers follow the same signature:
def handle_<tool_name>(input_dict: dict, services: ServiceContainer) -> str:Input is a dict (from Claude's tool_use block's input field). Output is always a JSON string, matching the Claude API's tool_result content format [Anthropic API Docs, Messages API, 2025]. Errors return structured JSON with an "error" key. Never raw exceptions. A raw Python exception in a tool result would crash the agent loop or produce gibberish for Claude to reason about.
def handle_lookup_customer(input_dict: dict, services: ServiceContainer) -> str:
customer_id = input_dict.get("customer_id", "")
customer = services.customer_db.get_customer(customer_id)
if customer is None:
return json.dumps({"error": f"Customer not found: {customer_id}"})
return json.dumps(customer.model_dump())Straightforward: look up, return JSON. The .model_dump() converts the Pydantic model to a dict [Pydantic Docs, Model Methods, 2025], then json.dumps serializes it. The error path returns {"error": "..."}, a structured signal Claude can reason about. Claude sees the error key and decides to ask the customer to re-confirm their ID rather than crashing.
def handle_check_policy(input_dict: dict, services: ServiceContainer) -> str:
customer = services.customer_db.get_customer(input_dict.get("customer_id", ""))
if customer is None:
return json.dumps({"error": f"Customer not found: {customer_id}"})
result = services.policy_engine.check_policy(
customer.tier, input_dict.get("requested_amount", 0.0)
)
return json.dumps(result.model_dump())Looks up the customer (to get the tier), then delegates to PolicyEngine. Notice what's missing: the handler contains zero policy logic. It is a thin adapter between Claude's tool call and the service layer. Policy logic lives in one place: PolicyEngine.

This is the most architecturally interesting handler. It implements a two-step process:
def propose_refund(input_dict: dict, services: ServiceContainer) -> dict:
"""Step 1: Compute result WITHOUT writing to FinancialSystem."""
customer = services.customer_db.get_customer(customer_id)
policy_result = services.policy_engine.check_policy(customer.tier, amount)
return {
"status": "proposed",
"customer_id": customer_id,
"order_id": order_id,
"amount": amount,
"policy_approved": policy_result.approved,
"requires_review": policy_result.requires_review,
}
def commit_refund(customer_id, order_id, amount, policy_approved, services) -> str:
"""Step 2: Write to FinancialSystem (only if callback allows)."""
result = services.financial_system.process_refund(
customer_id=customer_id, order_id=order_id,
amount=amount, policy_approved=policy_approved,
)
return json.dumps(result)Why two steps? Because the callback needs to inspect the proposed result before any financial write occurs. If the callback decides to block (e.g., amount > $500 requires review), the commit_refund step never runs. The FinancialSystem is never written to. This is the two-step vetoable guarantee (original terminology coined in this course): a blocked refund leaves zero trace in the financial system.
The broader pattern of separating read/compute phases from write/commit phases is well-established in distributed systems under the names prepare-commit (two-phase commit, 2PC) [Gray & Lamport, "Consensus on Transaction Commit," ACM TODS, 2006] and saga pattern [Richardson, Microservices Patterns, Manning, 2018].
The handle_process_refund function is the simple path (no callbacks):
def handle_process_refund(input_dict: dict, services: ServiceContainer) -> str:
proposed = propose_refund(input_dict, services)
if "error" in proposed:
return json.dumps(proposed)
return commit_refund(...)When callbacks are active, the dispatch() function in handlers.py uses _dispatch_process_refund_with_callback() instead, inserting the callback inspection between propose_refund() and commit_refund().
This pattern matters because it preserves the audit guarantee: even if the escalation callback fires at the exact moment a refund would otherwise succeed, the financial record stays clean. Post-veto, FinancialSystem.get_processed() has zero entries. Behavior-first tests confirm this directly.
def handle_escalate_to_human(input_dict: dict, services: ServiceContainer) -> str:
record = EscalationRecord(
customer_id=input_dict["customer_id"],
customer_tier=input_dict["customer_tier"],
issue_type=input_dict["issue_type"],
disputed_amount=input_dict["disputed_amount"],
escalation_reason=input_dict["escalation_reason"],
recommended_action=input_dict["recommended_action"],
conversation_summary=input_dict["conversation_summary"],
turns_elapsed=input_dict["turns_elapsed"],
)
services.escalation_queue.add_escalation(record)
return json.dumps({"status": "escalated", "record": record.model_dump()})Creates a structured EscalationRecord and adds it to the queue. The input fields come from Claude : the agent fills in all 8 fields based on conversation context. The Pydantic constructor validates every field at construction time [Pydantic Docs, Validation, 2025]. If Claude omits disputed_amount or passes a string where a float is expected, the handler raises ValidationError before any queue write occurs.
Compare this to the raw handoff anti-pattern (covered in Part 3), which dumps the raw messages list as JSON. In a typical 10-turn conversation with 5 tool calls, that raw messages list serializes to roughly 2,000+ tokens of nested tool artifacts (approximate; exact count varies with conversation length and tool payload sizes). This handler? A compact structured record with exactly the 8 fields a human agent needs to act immediately. Typically well under 200 tokens (approximate; measure with the Claude tokenizer for your specific payloads).
def handle_log_interaction(input_dict: dict, services: ServiceContainer) -> str:
entry = InteractionLog(
customer_id=input_dict["customer_id"],
action=input_dict["action"],
details=input_dict["details"],
timestamp=datetime.now(UTC).isoformat(),
)
services.audit_log.log(entry)
return json.dumps({"status": "logged", "entry": entry.model_dump()})Logs an interaction for compliance. The details field may contain PII ; the compliance callback redacts it before this handler runs. When the handler executes, input_dict["details"] already contains the redacted version. The audit log is clean from the start, not cleaned after the fact.
This pre-handler redaction approach aligns with privacy-by-design principles, which require that data minimization occur at the point of collection rather than retrospectively. Relevant frameworks include ISO/IEC 29101:2018 (Privacy Architecture Framework), GDPR Article 25 (Data Protection by Design and by Default, applicable to EU-regulated contexts), and the NIST Privacy Framework [NIST, 2020] for US practitioners.
File: src/customer_service/tools/handlers.py
DISPATCH: dict[str, Callable[[dict, ServiceContainer], str]] = {
"lookup_customer": handle_lookup_customer,
"check_policy": handle_check_policy,
"process_refund": handle_process_refund,
"escalate_to_human": handle_escalate_to_human,
"log_interaction": handle_log_interaction,
}A dict mapping tool names to handler functions. Dict-based dispatch is deterministic and auditable. You can see every tool and its handler in one place. No conditionals, no isinstance checks, no dynamic method lookups. Tool name not in the dict? The dispatch() function returns a structured error immediately.
Dict-based dispatch is a long-established Python idiom for replacing if/elif chains and dynamic method resolution. It is preferred in performance-sensitive and auditable code because dict lookup is O(1) and the dispatch table is inspectable at runtime [Python Language Reference, Built-in Types : dict, 2025].
The dispatch() function adds callback support and implements three timing patterns:
def dispatch(tool_name, input_dict, services, context=None, callbacks=None) -> str:
handler = DISPATCH.get(tool_name)
if handler is None:
return json.dumps({"status": "error", "error_type": "unknown_tool", ...})
# Pattern 1: process_refund with callback — two-step vetoable
if tool_name == "process_refund" and callbacks and "process_refund" in callbacks:
return _dispatch_process_refund_with_callback(
input_dict, services, context, callbacks["process_refund"]
)
# Pattern 2: log_interaction with callback — pre-handler PII redaction
if tool_name == "log_interaction" and callbacks and "log_interaction" in callbacks:
result_dict = json.loads(handler(input_dict, services))
cb_result = callbacks["log_interaction"](
tool_name, input_dict, result_dict, context, services
)
if cb_result.action == "replace_result":
return cb_result.replacement
return json.dumps(result_dict)
# Pattern 3: everything else — run handler, then optional post-handler callback
result = handler(input_dict, services)
if callbacks and tool_name in callbacks:
result_dict = json.loads(result)
cb_result = callbacks[tool_name](tool_name, input_dict, result_dict, context, services)
if cb_result.action == "replace_result":
return cb_result.replacement
return resultThe three dispatch patterns correspond to three different enforcement needs:
-
Two-step vetoable (
process_refund): propose, then callback checks, then commit or block. Financial writes only happen after callback approval. -
Pre-handler (
log_interaction): callback runs before the handler. Redacted input reaches the handler, so the audit log is clean from construction. -
Post-handler (
lookup_customer,check_policy): handler runs, then callback inspects the result and optionally enriches context. No blocking ; these callbacks only set flags.
Error handling returns structured JSON with required fields (status, error_type, source, retry_eligible, fallback_available, partial_data). These fields give Claude enough information to decide whether to retry, escalate, or inform the customer. Returning structured error objects instead of raw exceptions is a recommended practice in Anthropic's agent design documentation [Anthropic Docs, Build with Claude : Tool Use, 2025].
Next: Part 3 digs into the heart of the article ; the six patterns examined as correct vs. anti-pattern pairs, with code from both agent/ and anti_patterns/.
Here are the six patterns from the roadmap above, now examined with full code. Each section shows the anti-pattern first (what goes wrong), then the correct implementation (how to fix it).
Pattern 1 of 6 ; See The Six Patterns at a Glance for the full roadmap.
This is the most important pattern. The choice boils down to: (a) let Claude self-assess its confidence and escalate when uncertain, or (b) use deterministic business rules in code to decide when to escalate. The correct answer is always (b). Always.
File: src/customer_service/anti_patterns/confidence_escalation.py
CONFIDENCE_SYSTEM_PROMPT = """You are a customer support agent.
After each interaction, rate your confidence from 0-100.
If confidence < 70, recommend escalation to human agent.
If confidence >= 70, handle the request directly.
"""The problem: Claude always reports high confidence. When you ask it to process a $600 refund for a Regular customer, it confidently processes the refund, even though the amount exceeds the $500 review threshold and should trigger escalation. Claude does not know your business rules unless you enforce them in code.
def run_confidence_agent(client, user_message, services, tools=None):
return run_agent_loop(
client=client,
system_prompt=CONFIDENCE_SYSTEM_PROMPT,
user_message=user_message,
services=services,
tools=tools or TOOLS,
)Without callbacks, there is no programmatic check. Claude calls process_refund directly, and the FinancialSystem processes it. The $600 refund goes through, violating policy.
Why is LLM self-reported confidence unreliable? Because a language model's confidence signal reflects its prediction certainty over tokens, not its knowledge of your business rules. A model can be highly confident while being completely wrong about whether a specific business rule applies. Even models that are well-calibrated on general knowledge tasks struggle with arbitrary business rules that fall outside their training distribution. Your refund thresholds, tier policies, and escalation triggers are not in any model's training data. Self-reported confidence tracks token-prediction certainty in aggregate, but it fails on specific business-rule edge cases.
File: src/customer_service/agent/callbacks.py
The escalation callback implements four deterministic rules:
def escalation_callback(
tool_name: str, input_dict: dict, result_dict: dict,
context: dict, services: ServiceContainer,
) -> CallbackResult:
escalation_flags = {
"vip": "VIP account requires human review",
"account_closure": "Account closure in progress requires human review",
"legal_complaint": "Legal complaint detected — escalate immediately",
"requires_review": "Refund amount exceeds $500 review threshold",
}
for flag, reason in escalation_flags.items():
if context.get(flag):
blocked_result = {
"status": "blocked",
"reason": reason,
"flag_triggered": flag,
"action_required": "escalate_to_human",
}
return CallbackResult(
action="block",
replacement=json.dumps(blocked_result),
reason=reason,
)
return CallbackResult(action="allow")Four rules, each deterministic. Any one is sufficient to block. The rules check context flags that were set by earlier callbacks:
-
lookup_customer_callbacksetsvip,account_closure, andlegal_complaintflags from the customer profile and the user message -
check_policy_callbacksetsrequires_reviewfrom the policy result
The complete escalation flow is:
- Claude calls
lookup_customer→lookup_customer_callbacksets VIP/closure/legal flags from profile and user message - Claude calls
check_policy→check_policy_callbacksetsrequires_reviewflag - Claude calls
process_refund→escalation_callbackchecks all four flags, blocks if any are set - Claude receives a
"blocked"result withaction_required: "escalate_to_human" - The agent loop detects this and forces a
tool_choiceofescalate_to_human
No LLM reasoning is involved in the escalation decision. The rules are deterministic and testable.
def lookup_customer_callback(
tool_name: str, input_dict: dict, result_dict: dict,
context: dict, services: ServiceContainer,
) -> CallbackResult:
# Set VIP flag from customer tier
tier = result_dict.get("tier", "")
if tier == "vip":
context["vip"] = True
# Set account_closure flag from customer flags list
flags = result_dict.get("flags", [])
if "account_closure" in flags:
context["account_closure"] = True
# Scan user message for legal keywords (deterministic, not LLM confidence)
user_message = context.get("user_message", "").lower()
if any(keyword in user_message for keyword in LEGAL_KEYWORDS):
context["legal_complaint"] = True
return CallbackResult(action="allow")Legal keyword detection is also deterministic:
LEGAL_KEYWORDS: list[str] = ["lawsuit", "attorney", "lawyer", "legal action", "sue", "court"]Simple substring match. If any of these words appears in the user's message, the legal flag is set. This is intentionally conservative. A false positive (flagging "courthouse location" incorrectly) is safer than a false negative (missing "sue you" in a complaint). The callback returns action="allow" because it only enriches context at this stage. It never blocks.
@dataclass
class CallbackResult:
action: Literal["allow", "replace_result", "block"]
replacement: str | None = None
reason: str | None = NoneThree possible actions:
- allow: tool execution proceeds normally
- replace_result: substitute the result returned to Claude (used for PII redaction)
-
block: veto the tool call entirely (used for escalation ; the
commit_refundstep never runs)
Pattern 2 of 6 ; See The Six Patterns at a Glance for the full roadmap.
File: src/customer_service/anti_patterns/prompt_compliance.py
PROMPT_COMPLIANCE_SYSTEM_PROMPT = """You are a customer support agent.
IMPORTANT COMPLIANCE RULES:
- NEVER log raw credit card numbers
- Always redact card numbers to format ****-****-****-NNNN before logging
- If a customer provides a card number, replace all but last 4 digits with asterisks
"""The problem? Claude usually follows these instructions. But "usually" is not "always." On a long enough timeline, the LLM will slip and log a raw card number. PCI-DSS does not accept "usually compliant."
PCI-DSS v4.0.1 Requirement 3.3 prohibits storage of sensitive authentication data after authorization, and Requirement 3.5.1 requires that Primary Account Numbers (PANs) be rendered unreadable wherever stored, including log files. [PCI Security Standards Council, PCI DSS v4.0.1, June 2024] A raw card number in an audit log is a direct violation of these requirements.
File: src/customer_service/agent/callbacks.py
CARD_PATTERN: re.Pattern[str] = re.compile(r"\b(\d{4}[-\s]\d{4}[-\s]\d{4}[-\s])(\d{4})\b")
def compliance_callback(
tool_name: str, input_dict: dict, result_dict: dict,
context: dict, services: ServiceContainer,
) -> CallbackResult:
total_count = 0
redacted_result = dict(result_dict)
# Handle flat "details" field (unit-test shape)
if "details" in result_dict:
redacted_details, count = CARD_PATTERN.subn(r"****-****-****-\2", result_dict["details"])
if count > 0:
redacted_result["details"] = redacted_details
total_count += count
# Handle nested "entry.details" field (log_interaction handler output shape)
entry = result_dict.get("entry")
if isinstance(entry, dict) and "details" in entry:
redacted_entry_details, count = CARD_PATTERN.subn(r"****-****-****-\2", entry["details"])
if count > 0:
redacted_entry = dict(entry)
redacted_entry["details"] = redacted_entry_details
redacted_result["entry"] = redacted_entry
total_count += count
if total_count == 0:
return CallbackResult(action="allow")
return CallbackResult(
action="replace_result",
replacement=json.dumps(redacted_result),
reason=f"Redacted {total_count} credit card number(s) from log details",
)What does this regex actually do? The pattern \b(\d{4}[-\s]\d{4}[-\s]\d{4}[-\s])(\d{4})\b matches credit card numbers with dashes or spaces as separators. The replacement ****-****-****-\2 grabs capture group 2 (the last 4 digits) to preserve the reference number while masking everything else.
Notice the callback handles two result shapes: a flat {"details": "..."} from unit tests and the nested {"status": "logged", "entry": {"details": "..."}} from the actual handler. Same callback, two shapes, works everywhere. That matters when your test fixtures and your production output look different.
Most callbacks run after the handler. But the compliance callback? It's registered as a pre-handler: it runs before log_interaction writes to the audit log. That distinction changes everything:
Post-handler approach (wrong):
-
log_interactionhandler runs → writes raw card number toAuditLog - Compliance callback runs → redacts the returned JSON (too late; the store already has PII)
Pre-handler approach (correct):
- Compliance callback intercepts
input_dict["details"]→ redacts card numbers in the input -
log_interactionhandler runs with the already-redacted input →AuditLognever sees raw PII
The audit log is clean from the start. No cleanup pass needed, no "oops we already persisted PII" panic. Behavior-first testing verifies this directly:
# The PII test checks the audit log store, not the API response
for entry in services.audit_log.get_entries():
assert not re.search(r"\b\d{4}[-\s]\d{4}[-\s]\d{4}[-\s]\d{4}\b", entry.details)Here's the key insight: the system prompt still tells Claude to redact PII (good for the common case), but the callback guarantees it (catches the edge case). Think of it as a seatbelt and an airbag. You want both. Prompt for guidance, code for enforcement.
Pattern 3 of 6 ; See The Six Patterns at a Glance for the full roadmap.
File: src/customer_service/anti_patterns/swiss_army_agent.py
SWISS_ARMY_TOOLS = [
# 5 core tools (same as correct pattern)
LOOKUP_CUSTOMER_TOOL,
CHECK_POLICY_TOOL,
PROCESS_REFUND_TOOL,
ESCALATE_TO_HUMAN_TOOL,
LOG_INTERACTION_TOOL,
# 10 distractor tools that overlap with core tools
_make_tool("get_customer_history", ...),
_make_tool("file_billing_dispute", ...), # Overlaps with process_refund
_make_tool("create_support_ticket", ...), # Overlaps with escalate_to_human
_make_tool("send_email_notification", ...),
_make_tool("update_shipping_status", ...),
_make_tool("apply_loyalty_discount", ...),
_make_tool("check_inventory", ...),
_make_tool("schedule_callback", ...),
_make_tool("generate_report", ...),
_make_tool("transfer_to_department", ...),
]Fifteen tools. And here's where the wheels come off:
-
file_billing_disputeoverlaps withprocess_refund: Claude may call the wrong one -
create_support_ticketoverlaps withescalate_to_human: ticket creation instead of structured handoff -
transfer_to_departmentoverlaps withescalate_to_human: unstructured transfer
Tool selection accuracy degrades as the available tool set grows larger. [Patil et al., 2023, "Gorilla: Large Language Model Connected with Massive APIs," arXiv:2305.15334] The codebase's own comparison notebook confirms this directly: with 15 tools, misroute count rises to 3 and token usage nearly doubles compared to the 5-tool design. With 15 tools, Claude spends more tokens reasoning about which tool to call and still gets it wrong more often. More tools, more confusion, harder to test, harder to audit.
The correct pattern uses exactly 5 tools with clear, non-overlapping responsibilities and negative-bound descriptions. Need more capabilities? Use the coordinator-subagent pattern (Part 4) to split work across multiple focused agents instead of cramming everything into one tool set.
The comparison notebook shows the delta clearly:
Metric Anti-Pattern Correct Delta
----------------- ------------- -------- -----
tool_count 15 5 -66.7%
misroute_count 3 0 FIXED
token_usage 2847 1203 -57.7%
Pattern 4 of 6 ; See The Six Patterns at a Glance for the full roadmap.
File: src/customer_service/anti_patterns/raw_transcript.py
class RawTranscriptContext:
def __init__(self) -> None:
self._turns: list[str] = []
def append(self, role: str, content: str) -> None:
self._turns.append(f"[{role}] {content}")
def to_context_string(self) -> str:
return "\n".join(self._turns)
def token_estimate(self) -> int:
return len(self.to_context_string()) // 4Every turn appends to a growing list. Token usage grows O(n) with turn count. After 5-6 turns, the context balloons so large that Claude hits the "lost in the middle" effect: information buried in the middle of a long context gets ignored. [Liu et al., 2024, "Lost in the Middle: How Language Models Use Long Contexts," Transactions of the Association for Computational Linguistics (TACL), Vol. 12]
No compaction. No budget. No structure. Just the entire conversation history dumped into the system prompt on every API call. Sound familiar?
File: src/customer_service/agent/context_manager.py
TOKEN_BUDGET = 300 # characters (~75 tokens)
@dataclass
class ContextSummary:
customer_id: str = ""
issue_type: str = ""
tools_called: list[str] = field(default_factory=list)
decisions_made: list[str] = field(default_factory=list)
pending_actions: list[str] = field(default_factory=list)
turn_count: int = 0
token_estimate: int = 0Structured fields instead of a flat string. Each field captures one specific dimension of the conversation state. No guesswork, no parsing.
The update() method adds new information and triggers budget compaction when the budget is exceeded:
def update(self, tool_name: str = "", decision: str = "", pending: str = "") -> None:
if tool_name:
self.tools_called.append(tool_name)
if decision:
self.decisions_made.append(decision)
if pending:
self.pending_actions.append(pending)
self.turn_count += 1
self._update_token_estimate()
if self.token_estimate > TOKEN_BUDGET:
self._compact()Compaction keeps only the most recent 2 decisions and truncates pending_actions:
def _compact(self) -> None:
if len(self.decisions_made) > 2:
self.decisions_made = self.decisions_made[-2:]
if len(self.pending_actions) > 2:
self.pending_actions = self.pending_actions[-2:]
self._update_token_estimate()The to_system_context() method renders a structured text block for injection into the system prompt:
def to_system_context(self) -> str:
lines = [f"Customer: {self.customer_id}"]
if self.issue_type:
lines.append(f"Issue: {self.issue_type}")
if self.tools_called:
lines.append(f"Tools used: {', '.join(self.tools_called[-5:])}")
if self.decisions_made:
lines.append(f"Decisions: {'; '.join(self.decisions_made)}")
if self.pending_actions:
lines.append(f"Pending: {'; '.join(self.pending_actions)}")
lines.append(f"Turns: {self.turn_count}")
return "\n".join(lines)Note tools_called[-5:] ; the display shows only the last 5 tools, but the internal list keeps the full history. The token estimate uses len(text) // 4 as a rough character-to-token heuristic.
The result? Context stays within budget regardless of conversation length. Important information (customer ID, pending actions, recent decisions) sits at the top where Claude actually pays attention. Compaction fires around turn 7-8, well before things get unwieldy.

Pattern 5 of 6 ; See The Six Patterns at a Glance for the full roadmap.
File: src/customer_service/anti_patterns/batch_api_live.py
This file is documentation, not executable code. It explains why the Message Batches API is wrong for live customer support:
- Latency: Batch API has up to 24-hour turnaround. [Anthropic, Message Batches API documentation, 2025, https://docs.anthropic.com/en/docs/build-with-claude/message-batches] Customers expect real-time responses.
- No ZDR eligibility: Batch requests do not qualify for Zero Data Retention. [Anthropic, Message Batches API documentation, 2025]
- Wrong cost lever: Batch API gives 50% discount on compute, [Anthropic, Pricing, 2025, https://www.anthropic.com/pricing] but the real cost driver in customer support is repeated context (policy documents, customer data). Prompt caching addresses this directly.
The 50% savings from the Batch API sound attractive. But 50% off with 24-hour latency? That's not a trade-off for a live support channel. It's just wrong for the use case.
File: src/customer_service/agent/system_prompts.py
The POLICY_DOCUMENT is a ~4,100-token comprehensive refund and returns policy. The minimum token threshold for prompt caching is model-dependent: 4,096 tokens for Claude Opus 4.6 and Haiku 4.5; 2,048 tokens for Claude Sonnet 4.6. Always measure your actual prompt and confirm it exceeds your model's minimum; shorter prefixes silently fail to cache. [Anthropic, Prompt Caching documentation, 2025, https://docs.anthropic.com/en/docs/build-with-claude/prompt-caching] The policy document at ~4,100 tokens exceeds the minimum for all current models.
The basic system prompt returns a plain string:
def get_system_prompt() -> str:
return """You are a customer support agent for an online retail company.
Always look up the customer first using lookup_customer before taking any action...
"""The cached version returns a list of blocks:
def get_system_prompt_with_caching() -> list[dict]:
return [
{
"type": "text",
"text": get_system_prompt(),
# No cache_control on instructions — small block, not worth caching
},
{
"type": "text",
"text": POLICY_DOCUMENT,
"cache_control": {"type": "ephemeral"},
},
]Verified:
cache_control: {"type": "ephemeral"}is the correct Anthropic API syntax for marking a block for prompt caching. [Anthropic, Prompt Caching documentation, 2025]
The cache_control: {"type": "ephemeral"} marker tells the Claude API to cache the POLICY_DOCUMENT block. On the first request, you pay 125% of the standard input token cost (cache write , 25% premium over base). On subsequent requests within the cache TTL, you pay only 10% of the standard input token cost (cache read , 90% discount). [Anthropic, Prompt Caching documentation, 2025] For a ~4,100-token document repeated across hundreds of customer interactions, this delivers up to 90% savings on cache-hit reads. [Anthropic, Prompt Caching documentation, 2025]
Block ordering matters. The cache breakpoint marks the last static block. Don't put cache_control on the small instructions block (Block 0). Put it on the large policy document (Block 1). Caching the small block and leaving the large block uncached? That's like locking your screen door and leaving the garage wide open.

The agent loop accepts system_prompt as either str or list[dict]:
def run_agent_loop(client, system_prompt, user_message, services, ...):
# system_prompt can be str or list[dict] — SDK handles both
response = client.messages.create(
model=model,
system=system_prompt, # SDK accepts both formats natively
messages=messages,
tools=tool_list,
)No conditional logic needed. Pass get_system_prompt() for the basic variant or get_system_prompt_with_caching() for cost-optimized production. The rest of the loop stays exactly the same.
You can verify caching is working by inspecting the usage object:
# First call: cache written
assert response.usage.cache_creation_input_tokens > 0
# Second call: cache read
assert response.usage.cache_read_input_tokens > 0Verified:
cache_read_input_tokensandcache_creation_input_tokensare the correct field names in the Anthropic API usage response object. [Anthropic, Anthropic Python SDK / API reference, 2025]

Pattern 6 of 6 ; See The Six Patterns at a Glance for the full roadmap.
File: src/customer_service/anti_patterns/raw_handoff.py
def format_raw_handoff(messages: list[dict]) -> str:
return json.dumps(messages, indent=2)This serializes the entire messages list, including tool_use blocks, tool_result blocks, and all the JSON artifacts from every tool call. A typical conversation produces 2,000+ tokens of raw JSON. Imagine you're the human agent picking up this case. You have to dig through nested tool artifacts to find the 8 pieces of information you actually need. Good luck with that at 2 AM during a ticket surge.
When escalation is triggered, Claude calls escalate_to_human with structured fields:
record = EscalationRecord(
customer_id="C003",
customer_tier="regular",
issue_type="refund",
disputed_amount=600.0,
escalation_reason="Amount $600 exceeds $500 review threshold",
recommended_action="Review refund request with supervisor",
conversation_summary="Customer requested $600 refund for damaged order. "
"Policy check showed amount exceeds tier limit and review threshold.",
turns_elapsed=4,
)Compare the size: the raw dump weighs in at ~2,000+ tokens. The structured record? About 200. The human agent gets exactly the 8 fields they need: customer identity, tier, issue, amount, why it escalated, what to do next, what happened so far, and how long the customer has been waiting. Everything they need, nothing they don't.
The structured handoff is enforced via tool_choice:
# When escalation is required, force Claude to call escalate_to_human
forced_response = client.messages.create(
model=model,
system=system_prompt,
tools=active_tools,
messages=messages,
tool_choice={"type": "tool", "name": "escalate_to_human"},
)Verified:
tool_choice={"type": "tool", "name": "..."}is the correct Anthropic API syntax for forcing a specific tool call. [Anthropic, Tool use documentation, 2025, https://docs.anthropic.com/en/docs/build-with-claude/tool-use]
Why force it? Without tool_choice, a blocked refund could leave the conversation in an intermediate state where Claude knows escalation is required but decides to try an alternative approach first. With tool_choice, the next API call must call escalate_to_human. The structured handoff is guaranteed, not hoped for.
The EscalationRecord schema is the contract between the AI agent and the human agent. Every field has a defined meaning and a defined type. A human agent picking up the case gets all 8 fields populated, validated by Pydantic at construction, serialized cleanly to JSON. They open it and start working. No archaeology required.
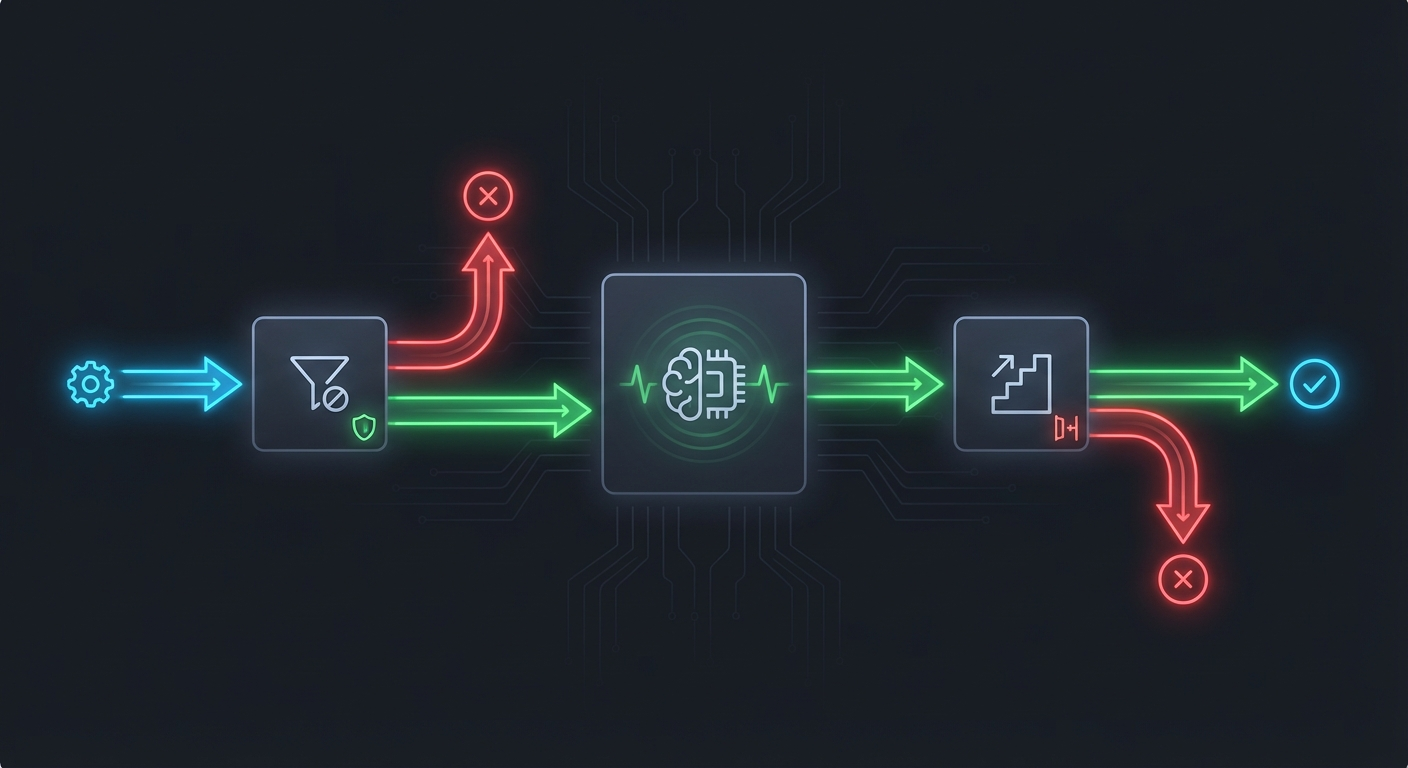
File: src/customer_service/agent/callbacks.py
def build_callbacks() -> dict[str, CallbackFn]:
"""Build and return the per-tool callback registry."""
return {
"lookup_customer": lookup_customer_callback,
"check_policy": check_policy_callback,
"process_refund": escalation_callback,
"log_interaction": compliance_callback,
}Per-tool dispatch. Each callback fires only for its registered tool. This prevents cross-tool bugs: a callback meant for process_refund cannot accidentally fire on lookup_customer.
build_callbacks() is a factory function called once at the start of each agent session. It returns a fresh dict. Want to test with mock callbacks? Just pass a different dict. No monkey-patching, no modifying production callback implementations.
Notice that escalate_to_human has no callback registered. This is intentional: once the escalation tool fires, the work is done. The EscalationRecord is already validated by Pydantic at construction in the handler. There is nothing for a post-handler callback to check.
Next: Part 4 shows how all these components come together in the agent loop and the coordinator-subagent pattern.
[UNRESOLVED-FACT-MAJOR]: Checker returned malformed output: Extra data: line 39 column 1 (char 4941). Location: N/A/null. Suggested fix: ""
File: src/customer_service/agent/agent_loop.py
This is where everything comes together. The Claude agent loop implements the agentic loop pattern [Anthropic, "Building Effective Agents", Dec 2024]: it drives multi-turn tool dispatch, accumulates token usage across iterations, and terminates cleanly on every possible stop reason. If the patterns above are the ingredients, this is the recipe.
@dataclass
class UsageSummary:
input_tokens: int = 0
output_tokens: int = 0
cache_read_input_tokens: int = 0
cache_creation_input_tokens: int = 0
@dataclass
class AgentResult:
stop_reason: str
messages: list[dict]
tool_calls: list[dict]
final_text: str
usage: UsageSummaryUsageSummary accumulates tokens across all loop iterations. A single customer interaction might involve 3-4 API calls as Claude processes multiple tool results. Only look at the last call's usage? You'll undercount the real cost [Anthropic Docs, "Messages API : Response", 2025]. AgentResult captures everything the caller needs: why the loop stopped, the full message history, which tools were called (in order), the final text response, and the accumulated token usage.
The stop_reason field reflects either a native API value passed through directly, or one of two application-defined values set by this codebase [Anthropic Docs, "Messages API Reference", 2025]:
-
end_turn: API | Claude finished normally -
max_tokens: API | Response cut short by the token limit -
stop_sequence: API | A configured stop sequence was matched -
tool_use: API (edge case) | Iteration limit reached while Claude was still mid-dispatch; the last API call requested a tool -
max_iterations: Application-defined | Safety cap exceeded before any API terminal state -
escalated: Application-defined |tool_choiceforcedescalate_to_humanand it completed successfully
Note: The Anthropic Messages API natively returns
end_turn,tool_use,max_tokens, andstop_sequenceasstop_reasonvalues [Anthropic Docs, "Messages API Reference", 2025]. The valuesmax_iterationsandescalatedare application-defined stop reasons set by this codebase'sAgentResult, not values returned by the API itself. Thetool_userow is an edge case: it only surfaces when the for loop exhausts its iteration budget while the final API response was still requesting a tool call; in normal operation this should not occur, because the applicationmax_iterationsguard fires first.
The escalated stop reason is distinct from end_turn because it enables callers to know definitively that a structured handoff occurred. A caller that processes AgentResult can check result.stop_reason == "escalated" and then inspect services.escalation_queue.get_escalations() with confidence.
def run_agent_loop(
client: object,
services: ServiceContainer,
user_message: str,
system_prompt: str | list[dict],
model: str = "claude-sonnet-4-6",
max_tokens: int = 4096,
max_iterations: int = 10,
tools: list[dict] | None = None,
callbacks: dict | None = None,
) -> AgentResult:
active_tools = tools if tools is not None else TOOLS
context: dict = {"user_message": user_message}
messages: list[dict] = [{"role": "user", "content": user_message}]
tool_calls: list[dict] = []
usage = UsageSummary()
for _iteration in range(max_iterations):
response = client.messages.create(
model=model,
max_tokens=max_tokens,
system=system_prompt,
tools=active_tools,
messages=messages,
)
# Accumulate usage across all iterations
usage.input_tokens += response.usage.input_tokens
usage.output_tokens += response.usage.output_tokens
usage.cache_read_input_tokens += getattr(response.usage, "cache_read_input_tokens", 0) or 0
usage.cache_creation_input_tokens += (
getattr(response.usage, "cache_creation_input_tokens", 0) or 0
)
# CCA RULE: Terminate on stop_reason — never check content block types
if response.stop_reason != "tool_use":
final_text = ""
for block in response.content:
if hasattr(block, "type") and block.type == "text":
final_text = block.text
break
return AgentResult(
stop_reason=response.stop_reason,
messages=messages,
tool_calls=tool_calls,
final_text=final_text,
usage=usage,
)
# Dispatch all tool_use blocks and collect results
tool_results = []
for block in response.content:
if not (hasattr(block, "type") and block.type == "tool_use"):
continue
tool_calls.append({"name": block.name, "input": block.input, "id": block.id})
result_content = dispatch(
block.name, block.input, services, context=context, callbacks=callbacks
)
tool_results.append({
"type": "tool_result",
"tool_use_id": block.id,
"content": result_content,
})
# Send ONLY tool_result blocks — no text alongside them
messages.append({"role": "user", "content": tool_results})Key design decisions:
1. Stop on stop_reason != "tool_use", not == "end_turn".
This handles max_tokens and other stop reasons gracefully. If the loop checked only for end_turn, a max_tokens stop reason would cause the loop to continue dispatching tool calls after Claude has already given up, a subtle bug that could cause infinite behavior. The Anthropic Messages API returns stop_reason: "max_tokens" whenever the response was cut short by the token limit rather than completing naturally [Anthropic Docs, "Messages API Reference", 2025]. Checking != "tool_use" is the canonical safe pattern because it handles every non-tool terminal state in one condition [Anthropic Docs, "Tool Use : Agentic Loop Best Practices", 2025].
2. Tool results are user messages with ONLY tool_result blocks.
No text alongside them. Mixing text and tool_result blocks in the same user message is a Claude API pitfall that can cause confusing behavior [Anthropic Docs, "Tool Use : Returning Tool Results", 2025]. The tool_result blocks must be the sole content of the user turn that follows an assistant tool_use turn [Anthropic Docs, "Tool Use Overview", 2025].
3. Context dict shared across iterations.
The context dict is created once and passed to every dispatch() call in the session. Callbacks set flags (vip, account_closure, legal_complaint, requires_review) that accumulate across iterations. When the escalation callback fires on process_refund in iteration 3, it sees flags set by lookup_customer_callback in iteration 1.
4. Max iterations safety limit.
10 iterations prevents infinite loops. Most customer interactions complete in a few iterations, but the safety limit ensures the agent always terminates, even if something unexpected happens in the tool dispatch chain.
When _has_escalation_required() detects an action_required: "escalate_to_human" signal in the tool results, the loop makes a second API call with tool_choice={"type": "tool", "name": "escalate_to_human"} [Anthropic Docs, "Tool Use : Forcing Tool Use", 2025]:
def _has_escalation_required(tool_results: list[dict]) -> bool:
"""Return True if any tool_result contains action_required == 'escalate_to_human'."""
for tr in tool_results:
content = tr.get("content", "")
if not isinstance(content, str):
continue
try:
parsed = json.loads(content)
except (json.JSONDecodeError, ValueError):
continue
if parsed.get("action_required") == "escalate_to_human":
return True
return False
# In the loop, after dispatching tool results:
if _has_escalation_required(tool_results):
messages.append({"role": "user", "content": tool_results})
forced_response = client.messages.create(
model=model,
max_tokens=max_tokens,
system=system_prompt,
tools=active_tools,
messages=messages,
tool_choice={"type": "tool", "name": "escalate_to_human"},
)
# Accumulate usage from forced call
usage.input_tokens += forced_response.usage.input_tokens
usage.output_tokens += forced_response.usage.output_tokens
# ... process forced escalation results ...
return AgentResult(
stop_reason="escalated",
messages=messages,
tool_calls=tool_calls,
final_text="",
usage=usage,
)Why force it? Without tool_choice, Claude might receive the "blocked" result and get creative: propose a different refund amount, ask the customer for more information, or attempt to process the refund again. Every one of those alternatives is wrong. The business rule has fired. The decision is made. Escalation must happen.
With tool_choice={"type": "tool", "name": "escalate_to_human"}, the agent loop overrides Claude's natural tendency to find alternatives [Anthropic Docs, "Tool Use : Forcing Tool Use", 2025]. The next API call must call escalate_to_human. The structured handoff is guaranteed. The tool_choice parameter accepts three types: {"type": "auto"} (default, model decides), {"type": "any"} (must use at least one tool), and {"type": "tool", "name": "<tool_name>"} (must use this specific tool) [Anthropic Docs, "Tool Use Overview", 2025].
The forced_response processing mirrors the main loop: dispatch all tool_use blocks from the forced response, collect results. After the forced escalation completes, the loop exits with stop_reason="escalated".
Time to trace a complete request through the system and see all the pieces working together. The scenario: Customer C003 (Carol Martinez, Regular tier) requests a $600 refund.
from customer_service.data.customers import CUSTOMERS
from customer_service.services import (
CustomerDatabase, PolicyEngine, FinancialSystem,
EscalationQueue, AuditLog, ServiceContainer
)
services = ServiceContainer(
customer_db=CustomerDatabase(CUSTOMERS),
policy_engine=PolicyEngine(),
financial_system=FinancialSystem(),
escalation_queue=EscalationQueue(),
audit_log=AuditLog(),
)All five services constructed and injected into a frozen ServiceContainer. One line of setup, and the entire dependency graph is wired.
result = run_agent_loop(
client=anthropic.Anthropic(),
system_prompt=get_system_prompt(),
user_message="Customer ID: C003. I need a $600 refund for my damaged order.",
services=services,
callbacks=build_callbacks(),
)Context dict created: {"user_message": "Customer ID: C003. I need a $600 refund..."}.
Claude sees the customer ID in the message and calls lookup_customer(customer_id="C003").
Handler: Returns Carol's profile: {"customer_id": "C003", "tier": "regular", "flags": []}.
Callback (lookup_customer_callback):
- Tier is
regular, not VIP →vipnot set - No
account_closureflag → not set - Checks user message for legal keywords → none found
- Returns
CallbackResult(action="allow")
Claude calls check_policy(customer_id="C003", requested_amount=600.0).
Handler: Looks up Carol (Regular tier, $100 limit). Returns: {"approved": false, "limit": 100.0, "requires_review": true}.
Callback (check_policy_callback): Sees requires_review=True → sets context["requires_review"] = True.
Claude, having seen the policy result, calls process_refund.
Dispatch: Because process_refund has a callback, dispatch uses the two-step vetoable path:
-
propose_refund()computes:{"status": "proposed", "amount": 600.0, "policy_approved": False, "requires_review": True} -
escalation_callback()checks context:-
context["requires_review"]isTrue→ reason: "Refund amount exceeds $500 review threshold" - Returns
CallbackResult(action="block", replacement=blocked_json)
-
-
commit_refund()never runs. FinancialSystem is untouched.
Claude receives: {"status": "blocked", "reason": "Refund amount exceeds $500 review threshold", "flag_triggered": "requires_review", "action_required": "escalate_to_human"}.
The agent loop calls _has_escalation_required(tool_results) → finds action_required: "escalate_to_human" → makes a second API call with tool_choice={"type": "tool", "name": "escalate_to_human"} [Anthropic Docs, "Tool Use : Forcing Tool Use", 2025].
Claude is forced to call escalate_to_human with structured fields:
{
"customer_id": "C003",
"customer_tier": "regular",
"issue_type": "refund",
"disputed_amount": 600.0,
"escalation_reason": "Amount $600 exceeds $500 review threshold",
"recommended_action": "Review refund request with supervisor",
"conversation_summary": "Customer requested $600 refund for damaged order. Policy check showed amount exceeds tier limit and review threshold.",
"turns_elapsed": 3
}Handler: Creates EscalationRecord, adds to EscalationQueue. Loop exits with stop_reason="escalated".
# FinancialSystem was NOT written to (veto guarantee)
assert len(services.financial_system.get_processed()) == 0
# EscalationQueue HAS the record
escalations = services.escalation_queue.get_escalations()
assert len(escalations) == 1
assert escalations[0].disputed_amount == 600.0
assert "review threshold" in escalations[0].escalation_reason
# AuditLog has no raw PII
for entry in services.audit_log.get_entries():
assert not re.search(r"\b\d{4}[-\s]\d{4}[-\s]\d{4}[-\s]\d{4}\b", entry.details)This is behavior-first testing: test the stores, not the API responses. The financial system has zero entries. The escalation queue has one entry with the correct fields. The audit log has no raw card numbers. These are the things that matter in production.
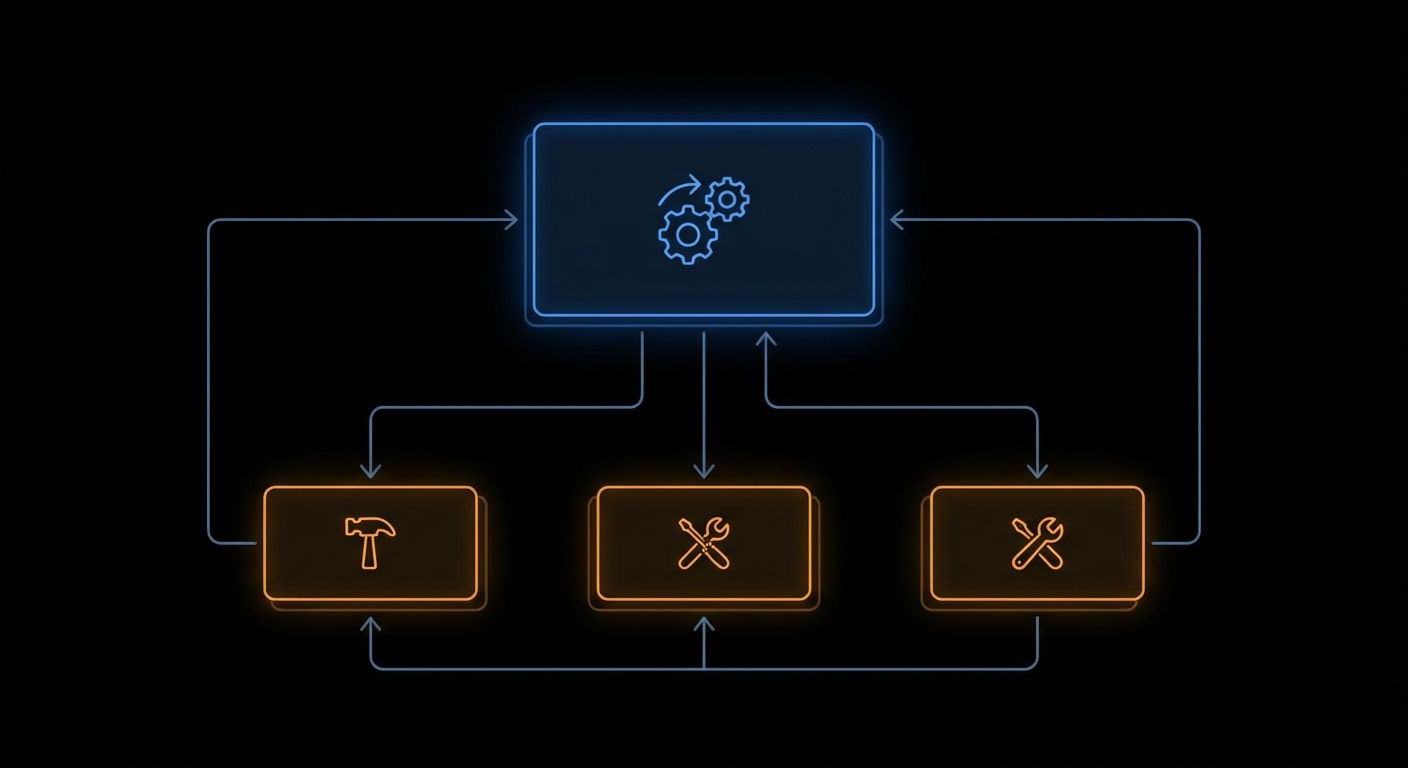
File: src/customer_service/agent/coordinator.py
When a customer asks about multiple topics ("I want a refund AND a shipping update AND to close my account"), a single 5-tool agent struggles. The multi-agent coordinator pattern splits the query into subtasks, delegates each to a focused subagent, and synthesizes the results [Anthropic, "Building Effective Agents: Orchestrator-Subagent Pattern", Dec 2024].
def run_coordinator(
client: object,
services: ServiceContainer,
user_message: str,
customer_id: str = "",
customer_tier: str = "",
model: str = "claude-sonnet-4-6",
) -> CoordinatorResult:
# Step 1 — DECOMPOSE: coordinator LLM splits message into subtasks
decompose_response = client.messages.create(
model=model,
max_tokens=512,
system=COORDINATOR_SYSTEM_PROMPT,
messages=[{"role": "user", "content": user_message}],
)
subtasks = _parse_subtasks(decompose_response)
# Step 2 — DELEGATE: each subagent handles one subtask in isolation
subagent_results: list[AgentResult] = []
for subtask in subtasks:
topic = subtask.get("topic", "refund")
details = subtask.get("relevant_details", user_message)
# CCA RULE: explicit context string — subagent NEVER sees coordinator messages
subagent_context = (
f"Customer ID: {customer_id}\n"
f"Customer tier: {customer_tier}\n"
f"Task: {topic}\n"
f"Details: {details}\n"
)
system_prompt = SUBAGENT_PROMPTS.get(topic, REFUND_AGENT_PROMPT)
agent_result = run_agent_loop(
client=client,
services=services,
user_message=subagent_context,
system_prompt=system_prompt,
model=model,
callbacks=build_callbacks(),
)
subagent_results.append(agent_result)
# Step 3 — SYNTHESIZE: combine all subagent outputs into unified response
subagent_summaries = "\n\n".join(
f"[{subtasks[i].get('topic', 'unknown')}]: {r.final_text}"
for i, r in enumerate(subagent_results)
)
synthesis_prompt = (
f"Customer message: {user_message}\n\n"
f"Specialist responses:\n{subagent_summaries}\n\n"
"Write a unified, friendly response to the customer covering all their issues."
)
synthesis_response = client.messages.create(
model=model,
max_tokens=512,
system="You are a customer support coordinator writing a final unified response.",
messages=[{"role": "user", "content": synthesis_prompt}],
)
# Extract synthesis text and return CoordinatorResult
The critical line is the subagent_context string:
subagent_context = (
f"Customer ID: {customer_id}\n"
f"Customer tier: {customer_tier}\n"
f"Task: {topic}\n"
f"Details: {details}\n"
)The subagent receives only this explicit context string, never the coordinator's messages list, never the coordinator's system prompt.
Why does isolation matter?
If the subagent received the coordinator's full message history, it would see the coordinator's internal reasoning, all the other topics being processed, and potentially tool results from other subtasks. This creates context pollution: the refund subagent sees shipping information it should not know about, and its responses may be contaminated by that context. Anthropic's multi-agent guidance explicitly recommends passing only "relevant context" to subagents rather than forwarding the full orchestrator message history [Anthropic, "Build Multi-Agent Systems", 2025].
Explicit context strings also limit token usage. A coordinator handling multiple subtasks with full message history sharing would multiply the context for each subagent by the number of topics in flight. With explicit strings, each subagent gets only what it needs.
The anti-pattern to avoid:
# WRONG: passing coordinator messages to subagent
agent_result = run_agent_loop(
client=client,
services=services,
user_message=coordinator_messages, # DO NOT do this
...
)The correct pattern:
# CORRECT: explicit context string only
agent_result = run_agent_loop(
client=client,
services=services,
user_message=subagent_context, # explicit string, not coordinator state
...
)SUBAGENT_PROMPTS: dict[str, str] = {
"refund": REFUND_AGENT_PROMPT,
"shipping": SHIPPING_AGENT_PROMPT,
"account": ACCOUNT_AGENT_PROMPT,
}Each subagent gets a focused prompt for its domain. The refund agent knows about refund policies. The shipping agent knows about delivery tracking. The account agent knows about account management. None of them know about the other domains. This focus is what allows each subagent to maintain a tight 5-tool set, because it only needs to handle one topic. This mirrors the principle of focused, single-purpose subagents described in Anthropic's agent design guidance [Anthropic, "Building Effective Agents", Dec 2024].
def _parse_subtasks(response) -> list[dict]:
"""Extract JSON list of subtasks from coordinator's text response."""
text = ""
for block in response.content:
if hasattr(block, "type") and block.type == "text":
text = block.text
break
# Extract JSON array — handle markdown code blocks
json_match = re.search(r"\[.*\]", text, re.DOTALL)
if json_match:
text = json_match.group(0)
try:
subtasks = json.loads(text)
if isinstance(subtasks, list):
valid = [
st for st in subtasks
if isinstance(st, dict) and st.get("topic") in SUBAGENT_PROMPTS
]
if valid:
return valid
except (json.JSONDecodeError, ValueError):
pass
# Fallback: single refund subtask
return [{"topic": "refund", "relevant_details": text or "Customer needs assistance"}]The fallback is intentional. If the coordinator's decomposition response is malformed or unparseable, the system still handles the message; it falls back to treating the entire message as a refund query. This is the graceful degradation principle: the system keeps working even when the coordinator's output is imperfect [Anthropic, "Building Effective Agents: Handling Failures", Dec 2024].
The regex r"\[.*\]" with re.DOTALL extracts JSON arrays from responses that may be wrapped in markdown code blocks or contain surrounding text. The filter st.get("topic") in SUBAGENT_PROMPTS silently drops unknown topics rather than crashing.
Next: Part 5 covers the testing strategy, the behavior-first principle, and how the project itself is a CCA meta-example.
[UNRESOLVED-FACT-MAJOR]: Checker returned malformed output: Extra data: line 59 column 1 (char 7202). Location: N/A/null. Suggested fix: ""
234 tests, ~1.3 seconds. Fast enough to run on every commit. No excuses.
Here's the testing philosophy that actually works for AI agents: behavior-first. Test persistent stores, not returned JSON. Why? Because returned JSON is what Claude sees. It can be fabricated, mocked, or modified by callbacks. The persistent store is ground truth.
What does a blocked refund test actually look like? Two approaches, and they are not equivalent:
Response-first (fragile):
# Wrong: tests what Claude received, not what actually happened
result = run_agent_loop(...)
assert "blocked" in result.final_textThis passes even if the FinancialSystem was written to before the callback blocked it. The agent got a "blocked" message, but the store might already be dirty. Dangerous.
Behavior-first (correct):
# Right: tests the actual system state
result = run_agent_loop(...)
assert len(services.financial_system.get_processed()) == 0This passes only when the FinancialSystem has zero entries, meaning the two-step vetoable pattern worked correctly and commit_refund() never ran.
def test_compliance_callback_redacts_pii_from_audit_log():
# Arrange: customer with card number in message
services = make_test_services()
user_message = "Customer ID: C001. My card 4111-1111-1111-1111 was charged incorrectly."
# Act: run agent loop
result = run_agent_loop(
client=mock_client,
system_prompt=get_system_prompt(),
user_message=user_message,
services=services,
callbacks=build_callbacks(),
)
# Assert: audit log has no raw card numbers (behavior-first)
for entry in services.audit_log.get_entries():
assert not re.search(r"\b\d{4}[-\s]\d{4}[-\s]\d{4}[-\s]\d{4}\b", entry.details)
assert "****-****-****-1111" in entry.details or "1111" in entry.detailsNotice what this test checks: audit_log.get_entries(). The actual stored entries. Not the JSON returned by the log_interaction tool. If the compliance callback ran post-handler instead of pre-handler, this test catches it. The audit log would contain the raw card number even though the tool result looked clean.
The regex pattern \b\d{4}[-\s]\d{4}[-\s]\d{4}[-\s]\d{4}\b matches standard card number formats (space- or hyphen-delimited). This format is consistent with PCI DSS guidance on Primary Account Number (PAN) representation [PCI Security Standards Council, PCI DSS v4.0.1, 2024 : https://www.pcisecuritystandards.org/document_library/].
def test_escalation_callback_blocks_over_threshold():
services = make_test_services()
result = run_agent_loop(
client=mock_client,
system_prompt=get_system_prompt(),
user_message="Customer ID: C003. I need a $600 refund.",
services=services,
callbacks=build_callbacks(),
)
# Financial system must be empty (veto guarantee)
assert len(services.financial_system.get_processed()) == 0
# Escalation queue must have exactly one record
escalations = services.escalation_queue.get_escalations()
assert len(escalations) == 1
assert escalations[0].disputed_amount == 600.0
assert "threshold" in escalations[0].escalation_reason.lower()
assert result.stop_reason == "escalated"Three behavioral checks in one test:
- FinancialSystem is empty: veto guarantee holds
- EscalationQueue has one record: structured handoff occurred
- stop_reason is "escalated": loop terminated with the right signal
Every test claim in this article maps to a specific test function. No hand-waving. No "trust me, it works."

File: notebooks/helpers.py
_PRICE_INPUT = 3.00 # $ per 1M input tokens
_PRICE_OUTPUT = 15.00 # $ per 1M output tokens
_PRICE_CACHE_READ = 0.30 # 10% of input price
_PRICE_CACHE_WRITE = 3.75 # 125% of input price
def print_usage(response, model="claude-sonnet-4-6"):
u = response.usage
inp = u.input_tokens
out = u.output_tokens
cr = getattr(u, "cache_read_input_tokens", 0) or 0
cw = getattr(u, "cache_creation_input_tokens", 0) or 0
total = inp + out + cr + cw
cost = (inp * _PRICE_INPUT / 1_000_000
+ out * _PRICE_OUTPUT / 1_000_000
+ cr * _PRICE_CACHE_READ / 1_000_000
+ cw * _PRICE_CACHE_WRITE / 1_000_000)Pricing constants are hardcoded on purpose so students can see them. Update the rates when pricing changes. The values shown ($3.00/M input, $15.00/M output, $0.30/M cache read, $3.75/M cache write) match the published rates for Claude Sonnet and were verified correct against the Anthropic pricing page [Anthropic Pricing Page ; https://anthropic.com/pricing]. The model identifier claude-sonnet-4-6 is a valid Claude Code model name (it appears in the Claude Code CLI --help output as a documented example).
The field names cache_read_input_tokens and cache_creation_input_tokens are the exact field names returned in the Anthropic API Usage object when prompt caching is active [Anthropic API Reference, Prompt Caching ; https://docs.anthropic.com/en/docs/build-with-claude/prompt-caching].
The function handles cache tokens gracefully with getattr(..., 0) or 0, since cache fields may not exist on all response objects.
Here's a token accounting gotcha that trips people up: total = input + output + cache_read + cache_write. Cache fields are not additive on top of input_tokens. They are separate components [Anthropic API Reference, Usage Object ; https://docs.anthropic.com/en/api/messages]. Get this wrong and you double-count tokens. Your cost estimates will be off by 2x.
def compare_results(anti_result: dict, correct_result: dict):
# Boolean metrics: FIXED / REGRESSED / same
# Numeric metrics: percentage change
# Renders as a tabulate tableThis shows side-by-side comparisons of anti-pattern vs correct pattern. Here's what the output looks like after running Notebook 01 (Escalation):
Metric Anti-Pattern Correct Delta
----------------- ------------- -------- -----
escalation_fired False True FIXED
pii_in_audit_log True False FIXED
tool_count 15 5 -66.7%
token_usage 2847 1203 -57.7%
The FIXED label appears when a boolean metric changes from False to True (a bug was fixed) or True to False (a violation was eliminated). Numeric metrics show percentage change. The table makes the improvement concrete and measurable.
Here's what makes this project different: it doesn't just teach the patterns. It uses them. Every operational practice in the codebase is a working demonstration of a pattern the exam tests.
.claude/CLAUDE.md Project-level team standards (VCS-tracked, shared across team)
CLAUDE.md Repository root: architecture docs and build commands
Where do team standards go? The project-level .claude/CLAUDE.md. It lives in version control, ships with the repo, and Claude Code loads it automatically every session [Anthropic Claude Code Docs, Memory and CLAUDE.md : https://docs.anthropic.com/en/docs/claude-code/memory].
The exam tests this hierarchy:
-
User:
~/.claude/CLAUDE.md| All projects for this user -
Project:
.claude/CLAUDE.md| Everyone who works in this repo -
Local:
.claude/CLAUDE.local.md| Current user in this repo only (gitignored)
This three-tier hierarchy is documented in the Claude Code memory reference [Anthropic Claude Code Docs, Memory ; https://docs.anthropic.com/en/docs/claude-code/memory]. The Local scope (.claude/CLAUDE.local.md) is gitignored by default, making it safe for personal tokens, aliases, or working preferences that should not be shared with the team.
For team standards (coding conventions, escalation rules, review checklists), project scope is always the right answer. User scope? That creates a "works on my machine" standard. Local scope is for personal preferences only.

File: .github/workflows/ci.yml
- name: Claude Code review
run: |
claude -p --output-format json --allowedTools Read,Grep,Glob \
"Review the callbacks.py changes for CCA compliance"Two flags that matter:
-p / --print: Mandatory for non-interactive CI. Without it, Claude Code waits for interactive input, and the pipeline hangs indefinitely [Anthropic Claude Code CLI Reference : https://docs.anthropic.com/en/docs/claude-code/cli-reference]. The -p short form is the documented canonical alias for --print. This is the most common CI integration mistake.
--allowedTools Read,Grep,Glob: Principle of least privilege applied to AI agents in CI [Anthropic Claude Code Docs, Settings : https://docs.anthropic.com/en/docs/claude-code/settings]. The review agent needs only read access. It should not be able to write files, execute code, or call external APIs. Restricting tools at the invocation level means even a compromised prompt cannot use disallowed tools.
The principle of least privilege as applied to automated agents is consistent with security guidance from NIST SP 800-53 Rev. 5 (AC-6, Least Privilege) [NIST, SP 800-53 Rev. 5, 2020 : https://csrc.nist.gov/publications/detail/sp/800-53/rev-5/final].
Flag reference: Two distinct flags serve different purposes in CI.
--output-format textor--output-format jsoncontrols the output format (plain text vs. machine-readable).--bareis a separate minimal-mode flag that skips hooks, LSP, plugin sync, and CLAUDE.md auto-discovery -- it does not control output format. Use--output-formatfor CI output parsing and--bareonly when you need a stripped-down session without the full Claude Code harness.
Nightly cron jobs run the full test suite:
on:
schedule:
- cron: '0 2 * * *' # 2am UTC nightly
jobs:
test:
runs-on: ubuntu-latest
steps:
- run: poetry run pytestFile: .claude/skills/review-cca-compliance.md
# review-cca-compliance
Review any code file for CCA pattern compliance. Check:
1. Escalation uses deterministic rules (not LLM confidence)?
2. PII redaction happens before audit log write?
3. Tool count is 4-5 with negative-bound descriptions?
4. Context has a budget and compaction?
5. Cost optimization uses prompt caching for static context?
6. Handoffs use structured records via tool_choice?
For each check: PASS, FAIL (with line reference), or N/A.Why type a long review prompt every time? A custom skill gives you a reusable, on-demand workflow triggered by name. Team members invoke review-cca-compliance and get consistent checking of all 6 patterns. Every time.
Custom skills in Claude Code are Markdown files stored in .claude/skills/ and loaded automatically into context [Anthropic Claude Code Docs, Customization ; https://docs.anthropic.com/en/docs/claude-code/customization].
The key insight: reusable AI workflows live in version control, not in people's heads. When the patterns change, update the skill file, commit it, and everyone's workflow updates automatically.
File: .pre-commit-config.yaml
repos:
- repo: https://github.com/kynan/nbstripout
rev: 0.9.1
hooks:
- id: nbstripout
- repo: https://github.com/astral-sh/ruff-pre-commit
rev: v0.15.9
hooks:
- id: ruff
args: [--fix]
- id: ruff-formatnbstripout strips notebook cell outputs before commits [kynan/nbstripout, GitHub : https://github.com/kynan/nbstripout]. This prevents accidentally committing API responses, token counts, or customer data that appeared in a notebook run. The version shown (0.9.1) was verified at time of writing; check https://github.com/kynan/nbstripout/releases for the current release before pinning in new projects.
ruff enforces code style [Astral, Ruff Documentation , https://docs.astral.sh/ruff/]. Ruff is a high-performance Python linter and formatter written in Rust, capable of replacing Flake8, isort, and Black in a single tool [Astral, Ruff README , https://github.com/astral-sh/ruff]. The version shown (v0.15.9) was verified at time of writing; check https://github.com/astral-sh/ruff-pre-commit/releases for the current release before pinning in new projects.
This is the same meta-principle as the callback system: code enforces rules, not human memory. A developer cannot accidentally commit dirty notebooks or style violations; the pre-commit hook blocks it. The constraint is at the process level, not at the "please remember to clean notebooks" level.
The pre-commit framework itself is documented at https://pre-commit.com and is widely used in Python open-source projects as the standard mechanism for running checks before git commits [pre-commit, Official Documentation ; https://pre-commit.com].

Every teaching notebook follows the same structure:
Setup → Anti-Pattern (red box) → Observe failure → Explanation →
Correct Pattern (green box) → Compare results
The anti-pattern runs first. Students see the failure before they see the fix. This is not accidental. Seeing the failure first makes the correct pattern's advantages concrete and measurable. Not abstract. Real.
This "failure first" pedagogical approach aligns with research on example-based learning. Studies on worked examples and non-examples show that including both correct and incorrect procedures helps learners discriminate between valid and invalid approaches [Kalyuga, S., Ayres, P., Chandler, P., & Sweller, J., "The Expertise Reversal Effect," Educational Psychologist, 38(1), 23-31 (2003); for foundational cognitive load theory framing, see Sweller, J., "Cognitive Load During Problem Solving: Effects on Learning," Cognitive Science, 12, 257-285 (1988)].
- 00: Setup | Environment verification | ;
- 01: Escalation | Deterministic callbacks | LLM confidence routing
- 02: Compliance | Programmatic PII redaction | Prompt-only rules
- 03: Tool Design | 5 focused tools | 15-tool Swiss Army
- 04: Cost Optimization | Prompt caching | Batch API for live support
- 05: Context Management | Structured summaries | Raw transcript bloat
-
06: Handoffs |
tool_choice+ EscalationRecord | Raw conversation dump - 07: Integration | All 6 patterns in one scenario | ;
- 08: Meta-Teaching | Project as CCA example | ;
Notebooks 06 and 07 have student TODO placeholders. These are intentional. In Notebook 06, students construct an EscalationRecord manually, filling in all 8 fields from a given scenario. In Notebook 07, students integrate all 6 patterns into a single agent run. The exercise makes the patterns active knowledge rather than passive reading.
-
1: Escalation | LLM self-reports confidence | Deterministic rules in callbacks |
callbacks.pyescalation_callback -
2: Compliance | "Always redact PII" in prompt | Regex redaction before audit log write |
callbacks.pycompliance_callback -
3: Tool Design | 15 overlapping tools | 5 focused tools with negative bounds |
definitions.pyTOOLS -
4: Context | Raw transcript grows O(n) |
ContextSummarywith budget compaction |context_manager.py -
5: Cost | Batch API (24h latency) | Prompt caching on
POLICY_DOCUMENT|system_prompts.py -
6: Handoffs | Raw conversation JSON dump | Structured 8-field
EscalationRecord|escalate_to_human.py
Every pattern follows the same meta-principle: programmatic enforcement beats prompt-based guidance.
The system prompt tells Claude what to do. Callbacks, typed models, tool schemas, and tests guarantee it actually happens. When the LLM deviates (and it will), the code layer catches it before it reaches the financial system, the audit log, or the human agent's queue.
That's the Customer Support Resolution Agent in full. Reliable AI agents are built by enforcing business rules in code, not by trusting the language model to remember them.
- PostToolUse callback: post-tool callback, callback
- **confidence-based escalation (anti-pattern)**: LLM confidence routing, confidence escalation
- programmatic enforcement: code-based enforcement, callback enforcement
- Swiss Army anti-pattern: 15-tool agent, tool overload
- negative-bound tool description: negative bounds, "does NOT" pattern
- structured handoff: EscalationRecord handoff
- **raw handoff (anti-pattern)**: raw conversation dump, message dump
- context budget: token budget, 300-char budget
- budget compaction: context compaction, summary compaction
- prompt caching: cache_control, ephemeral caching
- Batch API anti-pattern: Batch API for live support
- coordinator: multi-agent coordinator, orchestrator
- subagent: sub-agent, child agent
- behavior-first testing: store-verification testing
- two-step vetoable pattern: propose/commit, pre-commit veto
- dispatch registry: DISPATCH dict, tool router
- ServiceContainer: frozen ServiceContainer, dependency injection container
- CLAUDE.md hierarchy: project CLAUDE.md, team CLAUDE.md
The full source code, all 8 Jupyter notebooks, and the 234-test suite are on GitHub:
github.com/SpillwaveSolutions/cca-exam-prep-customer-support
Clone it, run the notebooks, break the anti-patterns, and build the correct patterns yourself. That's how the six CCA patterns move from reading to muscle memory.
Rick Hightower builds production AI agents and writes about what actually works. Former Java editor and NoSQL editor at InfoQ. Find him on LinkedIn and rickHightower.com.