This Machine learning model detect the illegitimates transactions.
Financial fraud is becoming a growing problem in the financial sector, with catastrophicimplications.Payments-related fraud is a major concern for cyber-crime organisations, and recentresearch has demonstrated that machine learning approaches may successfully detect fraudulent transactions in vast amounts of data. Such algorithms are capable of detecting fraudulent transactions that human auditors may be unable toidentify, and they can do so in real time. In this project, Using publicly available payment transaction data, we apply different supervised machine learning algorithms to the problem of fraud detection. Aim is to compare the results of several supervised machine learning algorithms, including Logistic Regression (LR), Support Vector Machines (SVM), Decision Tree (DT), and Random Forests (RF) and Neural Network.Aim is to show how supervised machine learning techniques may be utilised to accurately categorise data with substantial class imbalance.Exploratory analysis was used to distinguish between fraudulent and non fraudulent transactions. The both Decision Tree classifier and Logistic Regression outperformed the other algorithms, with an accuracy of 93.26 percent and an F1-score of 0.937500. However, the SVM Model performed worse with very low accuracy of 39.34 percent and 0.58427 F1 Score.
Financial fraud has a huge impact on the financial industry as well as ordinary life. Fraud can weaken confidence in the sector, undermine savings, and raise living costs. According to the PwC Global Economic Crime(PricewaterhouseCoopers nodate) and Fraud Survey 2020, respondents reported $42 billion in losses in the previous 24 months. Worse, only 56% of financial institutions asked indicated they investigated their worst fraudincidence.The ever-increasing use of technology in the finance business is contributing to the rise in fraud. While technology has made it easier to make digital payments and transactions, it has also increased the number of frauds, scams, and phishing attempts. As a result, businesses have begun to concentrate on solutions to prevent payment system vulnerabilities.Traditionally, banks and financial institutions have used manual procedures or rule-based methods to detect fraud, which have had limited success. A rule-based method necessitates the human establishment and assessment of a complex set of criteria for identifying questionable transactions.While this is useful for spotting anomalies that follow well-known patterns, it is ineffective for detecting fraud that follows new or unexpected patterns. This provides an incentive for criminals to devise ever more sophisticated tactics to get around the regulations, and they are using new technology to do so. Machine learning is a solution that is assisting banks and financial organisations in staying one step ahead of the competition. Machine learning is based on the idea that fraudulent transactions exhibit specific characteristics that distinguish them from legitimate ones. These tendencies are recognised by machine learning algorithms, which can distinguish betweenscammers and legitimate clients. Because they can use larger quantities of data, these algorithms can detect fraudulent activity much faster and with greater accuracy than traditional rules-based systems.Machine learning systems, rather than becoming more expensive to operate over time, tend to grow more effective and efficient without requiring any more specialised staff.Several studies have been conducted in the past to detect fraudulent transaction automatically using various machine learning and statistical methodologies. For highly and anonymous datasets, a credit card fraud detection approach was proposed. To address the problem of class imbalance, frequent item set mining was utilised to identify legal and illegitimate transaction patterns for each client. The pattern of an incoming transaction was then analysed using a matching algorithm to determine if it was real or fraudulent. This model’s evaluation revealed that it can both detect fraudulent transactions and improve imbalance classification(Seeja and Zareapoor 2014) . Bidirec-tional neural networks were used to suggest a model for real-time fraud detection. They used a big data set of cell phone transactions given by a credit card business in their research. In terms of false positive rate, the results
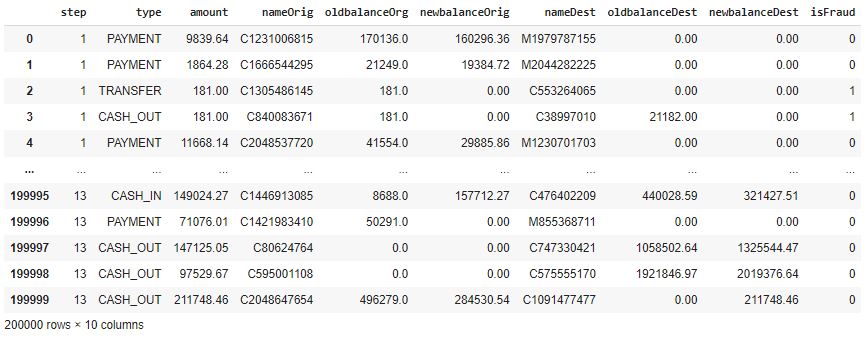
Figure 1. Fraudulent Transaction Data frame
confirmed that the suggested model outperforms rule-based algorithms(Krenker andothers 2009). To detect fraud, a two-layer statistical classifier was proposed for sensitive, highly skewed, and huge data sets. The method was inspired by the need to analyse a data set of over fifteen million real-world online banking transactions from 2011 to 2013 in order to spot frauds from legitimate transactions. The algorithm is especially successful at detecting abnormalities, with high true positive rates and reasonable low false positive rates, according to the results(Panaro, Riccomagno and Malfanti 2015). Logistic regression, decision trees, random forests, SVM (Support Vector Machine), and neural networks are some of the common supervised machine learning methods used to handle these problems in this project. In addition, we compare the results of numerous supervised machine learning approaches to distinguish between fraud and non-fraud transactions.
The proposed problem makes use of the publicly available dataset downloaded from the website kaggle and dataset are generated by collecting the data using payment card transaction including genuine transaction and fraudulent transactions. It consist of 10 columns, in which 9 columns are the features and the one class is the target class contain binary class which decides about whether the transaction is fraud or genuine. The shape of the data frame is 199999 records and 10 features shown in figure 1.
Exploratory Data Analysis is the crucial process of using descriptive statistics and graphical representations to undertake initial investigations on data in order to uncover patterns, spot anomalies, test hypotheses, and verify assumptions(Patil 2018). The below graphs shows how many fraud transactions and non-fraud transactions are there in our dataset.1.2.1. FRAUDULENT AND NON-FRAUDULENT RATIO OFTHE DATA The figure 2. shows the fraud transaction ratio of the whole dataset,from table 2 we can notice there are 147 fraud transaction out of 199999 transactions.
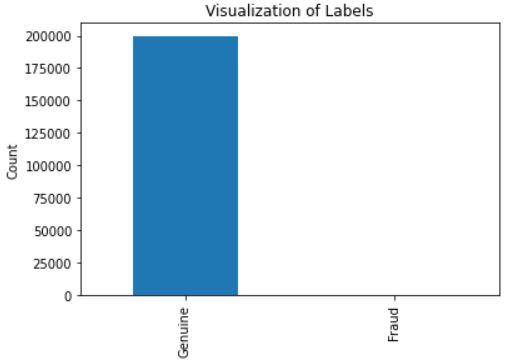
Figure 2. Fraudulent and non-fraudulent ratio
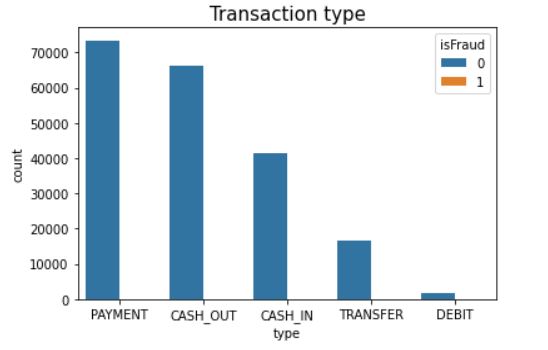
Figure 3. Fraudulent and non�fraudulent ratio
There are no missing values found in the dataset.
Table 1. Missing Values
| Attributes | Counts |
|---|---|
| isFraud | 0 |
| newbalanceDest | 0 |
| newbalanceDest | 0 |
| oldbalanceDest | 0 |
| nameDest | 0 |
| newbalanceOrig | 0 |
| oldbalanceOrg | 0 |
| nameOrig | 0 |
| amount | 0 |
| type | 0 |
| step | 0 |
In data-driven fraud detection systems, one of the most common challenges is to tackle class imbalance. In the real world, fraudulent transactions comprise of a tiny proportional in comparison with legitimate transactions. From figure 2 and Table 2 we can notice that there are imbalance of the data.there are low amount of fraud transaction(147) compare to legit transaction(199853).As a result, AI models face risks of overfitting on the legitimate data. Table 2. Class Imbalance
| Label | Counts |
|---|---|
| non-fraud(0) | 199853 |
| Fraud(1) | 147 |
The below figure 4 describes the statistic of the dataset such as mean,quartile,maximum value, counts etc.The mean of the isfraud class is 0.000735.
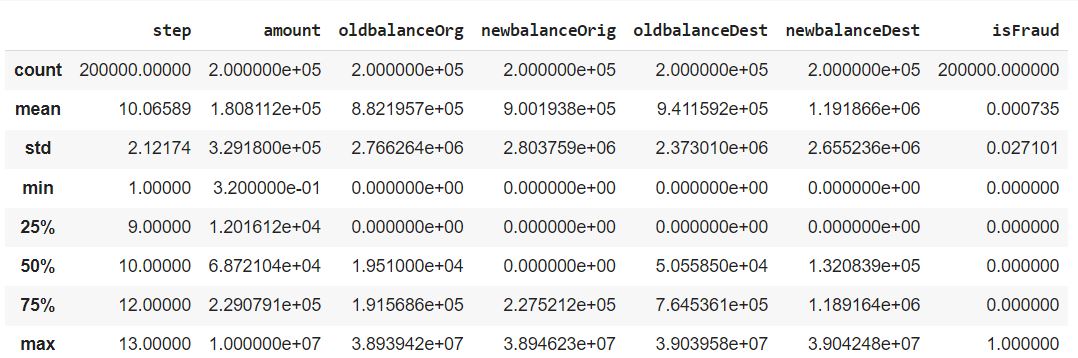
Figure 4. Descriptive Statistics
By creating correlation maps we can identify features that are closely correlated with the legitimacy of our transactions. This can be a crucial step when performing dimensionality reduction, removing/adding features.The figure 5 shows the correlation between the classes. The dark color shows the weak correlation and the light color shows very strong correlation.from that it can be notice that there are strong correlation between oldbalanceorigin,newbalanceroging and oldbalancedest, newbalancedest.Also there is no correlation found with isfraud class.
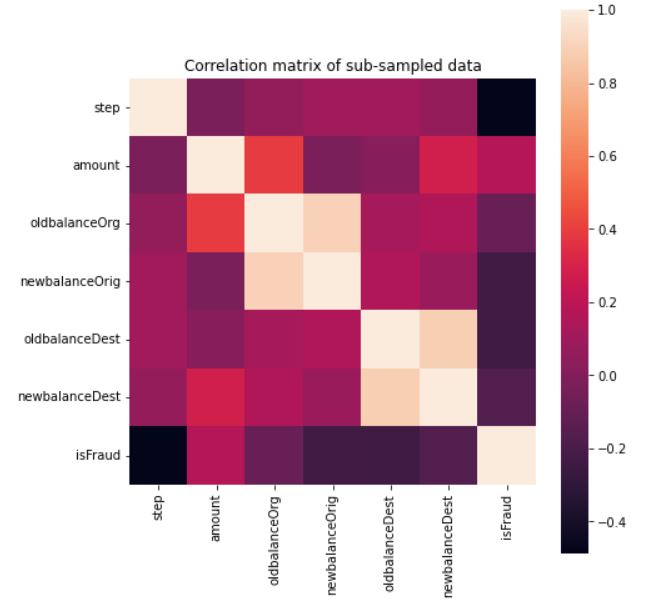
Figure 5. Correlation
This section explains about the implementation, which includes the algorithm used for implementation of proposed system.In this project we have used multiple supervised machine learning algorithm to find the fraudulent transaction.Such as Logistic regression, Random forest, Neural network, SVM and decision trees.
Logistic regression is a popular method, which determines the strength of cause and effect relationships between variables in data sets. It can be used to create an algorithm which predicts whether a transaction is ‘fraud’ or not. Decision trees can be used to create a set of rules that model customers’ normal behavior and can be trained, using examples of fraud, to detect anomalies.Random forests (boosting techniques) ensemble multiple weak classifiers into one strong classifier – they can be built using an ensemble of decision trees.Neural networks are a powerful technique inspired by the workings of the human brain. Able to learn and adapt to patterns of normal behavior, neural networks can identify fraud in real-time.
In this project I have used Python as a programming language.Python is one of the best languages for the implementing machine learning. It provides rich packages and libraries that used in machine learning. and the libraries
Numpy,Pandas,Scikitlearn,matplotlib,seaborn and Keras.
we dont have a missing values in the dataset so data are cleaned already. But to balance the data we need to apply the data sampling method. Also there are some categorial values in the dataset so it needs to perform some method to make data useful.
There are many ways to address class imbalance by using sampling techniques. but for this data we will use undersampling technique because we have 2 million samples so it will be easy to make it same as minority class size. under sampling removes records from the majority class (non-fraud)such that its size approximates the minority class’s size.(See figure 3)
We have categorical data as well in our dataset such as step,nameorig,namedest,hasDest. to convert it into numeric data we have performed on-hot encoding method.
We have split the data into training and test sets, with a 70/30 split. Training samples are 205 and Testing samples are 89.This is done to measure and avoid possible overfitting. By measuring the model’s performance on separate data,
In the Experiments section, It is to describe the dataset, experimental settings, evaluation criteria, results, and discussion.
In this project different supervised machine learning models have been trained to achieve the best accuracy and F1 scores to detect the fraudulent transactions. All these models can be built feasibly using the algorithms provided by the scikit-learn package. some processing method has been performed on the data. After processing the data, Data has been splitted to perform the training and testing on the data. All the algorithm has been performed on the training data one by one to check the performance of the model on the data.
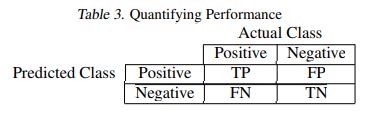
The end result is evaluated based on the confusion matrix and precision, recall and accuracy is calculated.It can be expressed as:
P recision = True Positive / (TruebPositive + False Positive)
recall =True Positive / (True Positive + False Negative)
F1 = 2X (Precision ∗ recall)/(Precision + recall)
It contains two classes: actual class and predicted class. The confusion metrics depends on these features: True Positive: in which both the values positive that is 1. True Negative: it is case where both values are negative that is 0. False Positive: this is the case where true class is 0 and non-true class is 1. False Negative: It is the case when actual class is 1 and non-true class is 0(Asha and KR 2021).
Typically, a confusion matrix is a visualization of a classification model that shows how well the model has predicted the outcomes when compared to the original ones.
The below figure 3 shows the F1 scores and the accuracy of each model. From that It can be notice that the model Decision Tree and Logistic Regression has same and the highest accuracy(0.93258) and F1 scores(0.937500) compare to other model, It means that these two model have outperformed on this dataset of fraudulent transaction and has predicted the best compare to other models. However, the SVM has performed the worse on the dataset and gives very Low F! score and accuracy. And the other two model has very close accuracy to the best performed model.
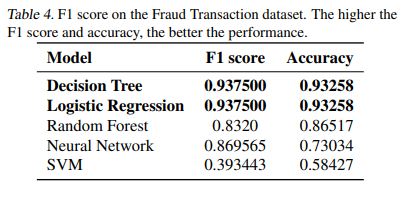
In this Financial Fraudulent transaction detection problem first we have used the Decision tree algorithm after applying the under-sampling method to the fraud class to balance the data at minority size. Then we have checked the decision tree accuracy which performed best on this proposed system. Then we have compared the other algorithm to check the better performance than Decision tree. However at end of the all model evaluation we got best accuracy model as Decision tree as well as linear regression for the proposed problem.
To conclude, It can be notice from the above tables 4, that shows the comparison of the accuracy of the model, the best accuracy model is Decision tree and Linear regression method for the Fraud transaction prediction based on the highest accuracy and F1 scores.
Asha, RB and Suresh Kumar KR (2021). “Credit card fraud detection using artificial neural network”. inGlobal Transitions Proceedings: 2.1, pages 35–41.
Krenker, Andrej andothers (2009). “Bidirectional Artificial Neural Networks for Mobile-Phone Fraud Detection”. inEtri Journal: 31.1, pages 92–94.
Panaro, Delio, Eva Riccomagno and Fabrizio Malfanti (2015). “A Fraud Detection Algorithm For Online Banking”. inBOOK OF ABSTRACTS: page 271. Patil, Prasad (may 2018). What is exploratory data analysis? URL: https://towardsdatascience.com/exploratory-data-analysis-8fc1cb20fd15
PricewaterhouseCoopers (nodate). PWC’s Global Economic Crime and Fraud Survey 2020. URL: https://www.pwc.com/gx/en/services/forensics/economic-crime-survey.html.
Seeja, KR and Masoumeh Zareapoor (2014). “Fraudminer: A novel credit card fraud detection model based on frequent itemset mining”.inThe Scientific World Journal: 2014