![]()
![]()
Catch machine-learning data leakage at runtime — in one import.
The one tool that automatically catches group leakage (the same entity in train and test),
zero config, pointing at the exact line.
Install · Quickstart · When to use it · Comparison · Benchmarks · Limitations
- shipped a model that scored 95% in cross-validation and ~50% in production, and only then went looking for why?
- fitted a scaler, imputer, or feature selector on the full dataset before splitting — and not been sure whether it actually leaked?
- let the same user / patient / store land in both train and test with a plain
KFold, and watched a too-good score you couldn't reproduce?
All three are data leakage. They're quiet — the code runs fine — and they reward you with a score that looks great, which is exactly why you tend to find out too late. splitguard catches them while your code is still running.
A bit of context. This is one of a handful of small tools I'm putting out — each one a problem I ran into on my own ML projects, and the fix I wish I'd had on hand at the time. I wrote splitguard in an evening; it isn't trying to be everything. But the leak it catches has cost me real hours of "why is this score too good?" more than once, so here it is in case it saves you some. It's narrow on purpose, and honest about where it stops (the limits are spelled out below).
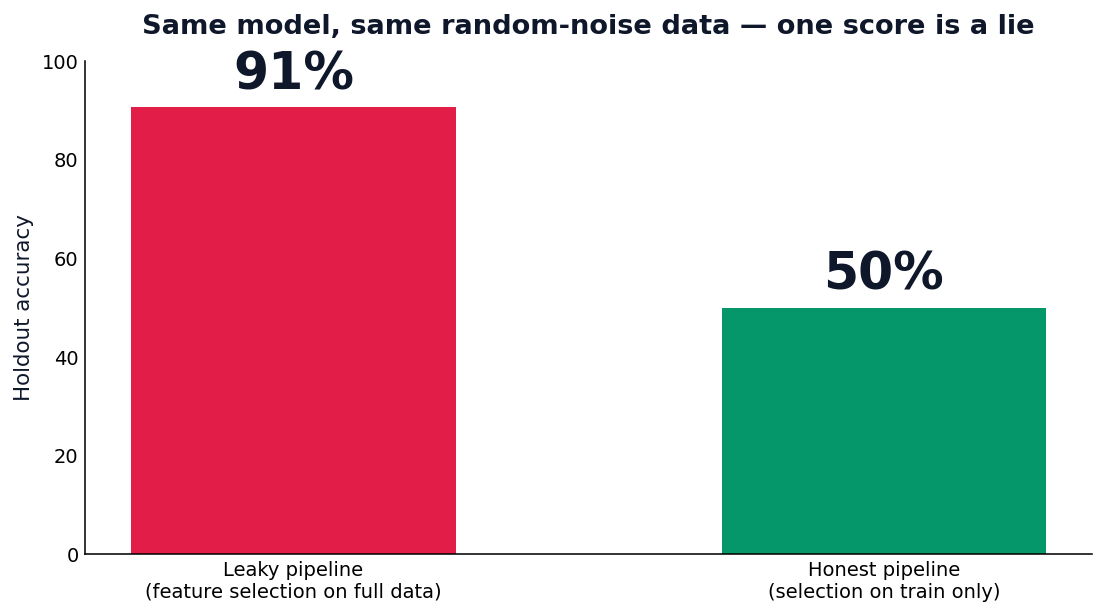
In examples/leaky_pipeline.py, fitting a feature selector on the
full matrix of pure random noise inflates the holdout accuracy from an honest 50.0% to a
seductive 90.6%. splitguard flags the offending fit and the exact line; nothing else in the
standard toolbox does.
pip install splitguard # core (numpy only)
pip install "splitguard[rich]" # prettier terminal reportsRequires Python ≥ 3.10. scikit-learn ≥ 1.2 enables the automatic hooks.
Wrap the code you want checked in guard() — no datasets to wrap, no schema, no config:
import splitguard
from sklearn import model_selection
from sklearn.preprocessing import StandardScaler
with splitguard.guard():
X_tr, X_te, y_tr, y_te = model_selection.train_test_split(X, y)
scaler = StandardScaler().fit(X) # leak: the scaler saw the held-out rows
...
# on exit, splitguard reports the leak (and raises in scripts/tests)Or guard the whole run with a single line at the top of any script or notebook:
import splitguard.auto # a report card prints automatically when the run endsImport order matters for the one-line mode:
import splitguard.auto(orsplitguard.install()) must run beforefrom sklearn.model_selection import train_test_split, or that name is bound to the unpatched function and the split isn't tracked. If you fit models but no split is ever tracked, splitguard warns rather than reporting a misleading clean result.
with splitguard.guard(groups=(X, group_ids)):
model_selection.train_test_split(X, y) # flagged if a group spans train and testThe fix is GroupKFold / GroupShuffleSplit, which splitguard confirms stays clean.
def test_pipeline(no_leakage): # provided fixture; fails the test on any leak
train_my_pipeline()[tool.pytest.ini_options]
splitguard = true # or guard every test project-wide| Use it for… | Why |
|---|---|
Ad-hoc scripts & notebooks that don't use a Pipeline |
catches the manual scaler.fit(X)-before-split mistakes a Pipeline would have prevented |
| Grouped / panel / time-series data (user, patient, store, session) | group leakage is the one class no Pipeline and no static tool catches — splitguard does |
| A CI gate on training code | the no_leakage fixture fails the build if a held-out row reaches a fit |
| Onboarding / teaching | shows where and why a leak happened, with a one-line fix |
And when not to bother: if your whole pipeline already lives inside a scikit-learn Pipeline
with cross_val_score, overlap and preprocessing leakage basically can't happen — they're
prevented by construction. splitguard just stays quiet there (zero false positives), so what it
adds is mostly group leakage and the messier ad-hoc code that lives outside a Pipeline.
splitguard tracks row identity, not values:
- Taint — at
train_test_split(auto-wrapped), a cross-validator.split, ormark_test(...), it records each held-out row's identity (the index label for pandas — a sample's true identity, preserved by the split — or a content hash for NumPy). - Watch — it wraps every estimator's
fit(scikit-learn, plus XGBoost / LightGBM / CatBoost, and the nativexgboost.train/lightgbm.train); each fit checks its rows against the held-out set. - Report — it names the offending step, the leaked-row count, the order pattern, and the fix. It never mutates your data, never changes an estimator's result, and never raises out of its own hooks — instrumented code behaves identically to uninstrumented code.
Works across train_test_split, three-way train/val/test, dynamic splits (across_splits), and
cross-validators (KFold, StratifiedKFold, GroupKFold, TimeSeriesSplit, ShuffleSplit, …),
with per-fold tracking that does not false-positive on a correct CV loop.
splitguard observes the computation at runtime; data-quality suites inspect the data; static analysers read the code. Each sees a different class of leakage.
| splitguard | deepchecks | cleanlab | leakage-analysis (static) | sklearn Pipeline |
|
|---|---|---|---|---|---|
| Approach | runtime hook | inspect assembled datasets | data-issue scan | static AST (souffle) | prevention |
| Setup | 1 line | wrap Dataset + suite.run |
call find_issues |
CLI / Docker (Py 3.8) | adopt it |
| Overlap (shared rows) | ✅ | ✅ | ✅ | ✅ | prevents |
| Preprocessing fitted on full data | ✅ | ❌ (data looks clean) | ❌ | ✅ | prevents |
| Group leakage | ✅ | ❌ | ❌ | ❌ | ❌ |
Preprocessing via statistics (np.mean) |
❌ | ❌ | ❌ | ✅ | prevents |
| Points at the exact line | ✅ | ❌ | ❌ | ✅ | n/a |
Where splitguard wins: it's one line, it runs live, it points at the exact line, and it's the only
one here that catches group leakage on its own. Where it doesn't: it isn't a data-quality suite
(deepchecks does drift and distribution checks it has no opinion on), it misses statistics-only
preprocessing that a static analyser would catch, and on a disciplined Pipeline codebase it adds
little beyond group leakage. Treat it as complementary to these tools, not a replacement.
All figures are produced from live runs by
tools/make_analysis_figures.py — no hardcoded numbers.
Validated against a published benchmark. On the labelled corpus from Yang et al. (ASE'22,
leakage-analysis), splitguard scores
3 TP / 1 TN / 0 FP / 0 FN on overlap leakage and is honest about the categories it can't see
(validation/run_benchmark.py).
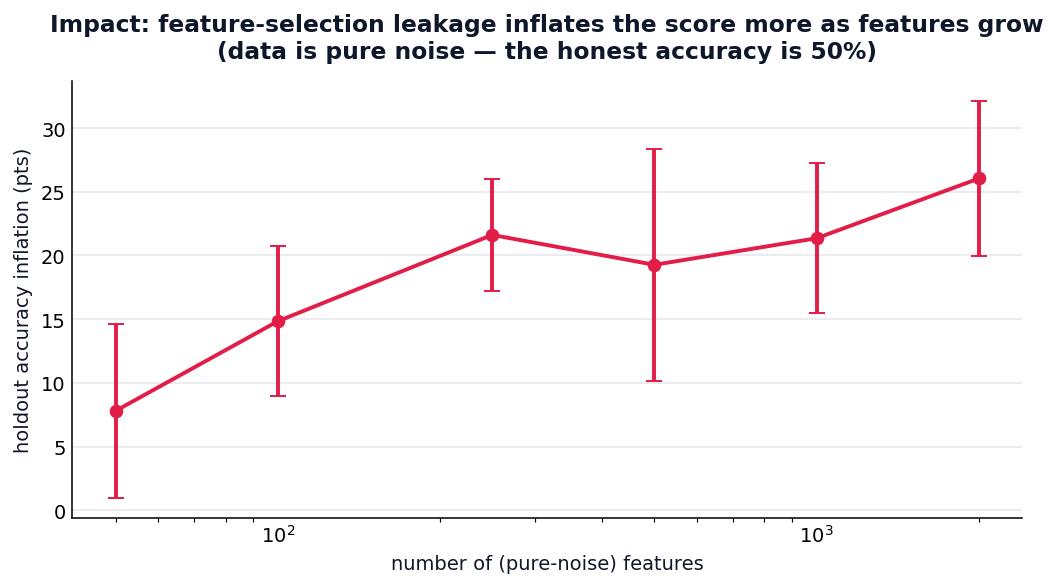
Why leakage matters (impact). With feature-selection leakage on pure-noise data (honest accuracy = 50%), the holdout score inflates by ~8 to ~26 points and grows with the number of features:
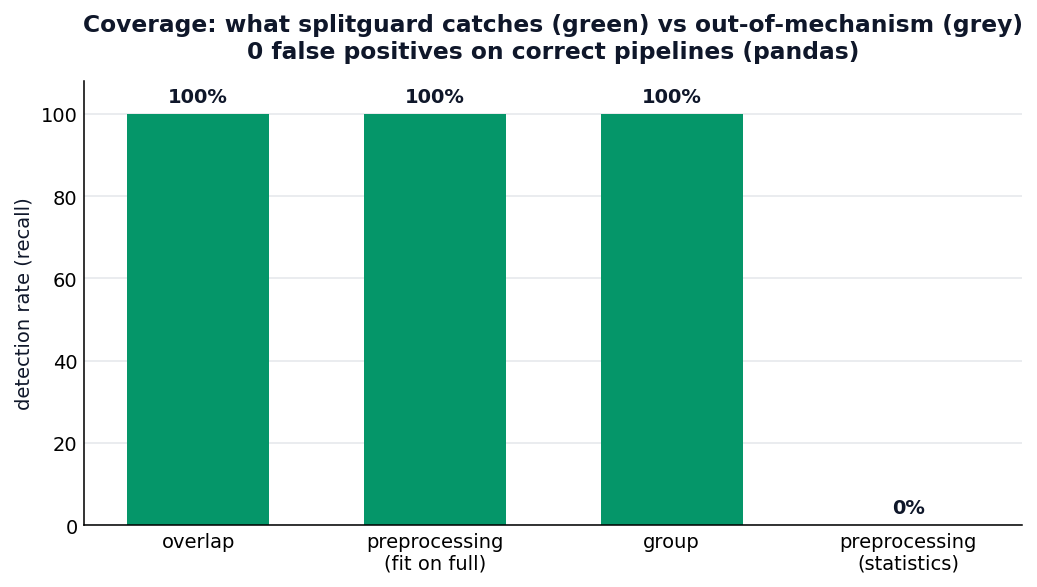
Coverage (recall by leakage type), measured live over 8 seeds. 100% on overlap, preprocessing-fit-on-full, and group leakage; 0% on statistics-only preprocessing (out of mechanism); 0 false positives on correct pipelines (pandas):
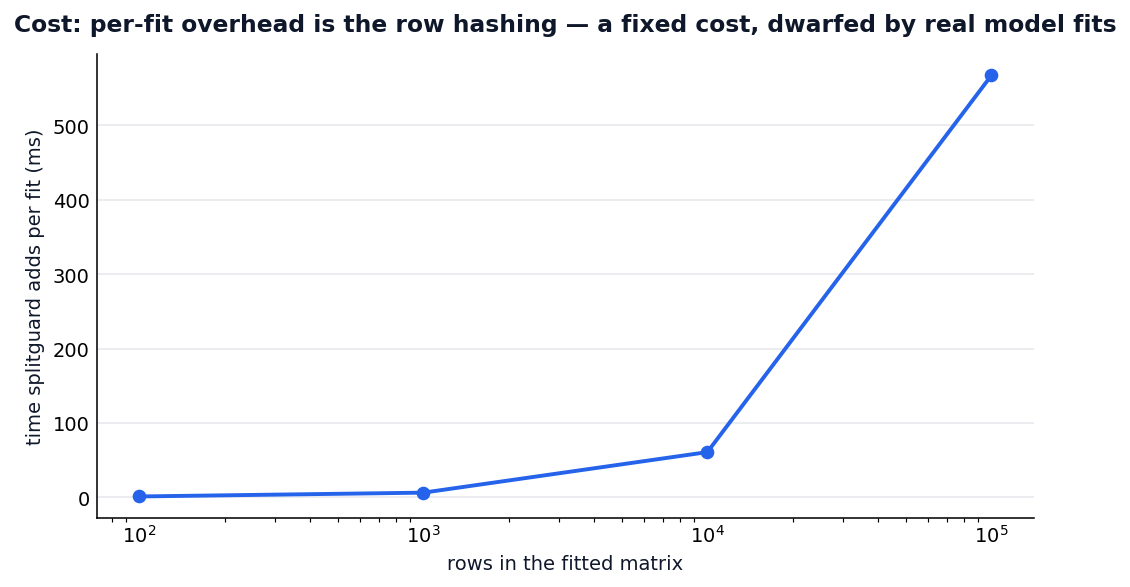
Cost (overhead). The per-fit overhead is row hashing — a fixed cost of roughly 1 ms at 100 rows up to ~0.6 s at 100k rows (~6 µs/row), negligible next to a real model fit at that size and sub-60 ms at typical sizes (≤10k rows):
splitguard tracks held-out row / group identity through fit. Leakage that doesn't move a
held-out row into a fit is invisible to this mechanism — by design, stated plainly:
| Not detected | Why | Use instead |
|---|---|---|
Preprocessing via pure statistics (X -= X.mean()) |
only an aggregate touches the data; no held-out row enters a fit | static analysis (leakage-analysis) |
fit_transform then split |
the split is on transformed rows; identities don't match | a Pipeline; guard(strict_transforms=True) warns |
| Multi-test leakage (reusing the test set to choose a model) | a decision-flow bug; the test rows are legitimately identical every round | a final test set never used for selection |
| Target leakage (a feature derived from the label) | a feature-construction error; no improper held-out row enters a fit | feature / correlation audits |
| Temporal leakage (future predicts past) | needs a time ordering splitguard doesn't model | TimeSeriesSplit + domain review |
Two honest caveats: splitguard is coverage-bounded (it reports leakage that occurs in the executed run — like a passing test, not a proof), and for NumPy inputs without an index, legitimately duplicate rows can register as overlap (it warns when this is the case; pass pandas DataFrames for reliable index-based identity).
- C. Yang, R. Brower-Sinning, G. A. Lewis, C. Kästner. Data Leakage in Notebooks: Static Detection and Better Processes. ASE 2022. arXiv:2209.03345
- S. Kapoor, A. Narayanan. Leakage and the Reproducibility Crisis in Machine-Learning-based Science. Patterns, 2023. https://reproducible.cs.princeton.edu/
- C. Dwork et al. The reusable holdout: Preserving validity in adaptive data analysis. Science, 2015. (test-set reuse / multi-test leakage)
- X. Bouthillier et al. Accounting for Variance in Machine Learning Benchmarks. NeurIPS 2021.
- scikit-learn — Common pitfalls and recommended practices. https://scikit-learn.org/stable/common_pitfalls.html
Issues and pull requests are very welcome — start with CONTRIBUTING.md and the Code of Conduct. If you'd like to contribute, good places to start are native adapters beyond scikit-learn, an index-identity mode for NumPy, or new detectors. And if splitguard ever misses a leak it should have caught — or fires on something that's actually fine — please open an issue with a small reproducer; honestly, those are the reports I value most. You can also reach me on LinkedIn.
MIT © 2026 Tommaso Aiello — free to use, modify, and distribute (including commercially); keep the copyright notice; provided "as is", without warranty.