项目地址:https://github.com/Trust04zh/16kos
项目成员:@Trust_04zh、@zly
- 设计并实现支持基于16k页面的虚拟内存管理系统的操作系统
- 验证系统正确性
- 修改qemu提供16k页面操作系统的模拟运行环境
- 实现基于页的空闲内存分配算法
- First Fit
- Best Fit
- Buddy System
- 在16k页面操作系统上实现进程管理
- 实现用户进程间用户内存的隔离
- 支持CFS进程调度算法
- [] 解释
satp更新后控制流能够正常执行的原理
本项目基于SUSTech CS305/334课程提供的RISC-V ISA下的ucore操作系统代码进行更新,修改qemu-5.0.0以构建相应的模拟硬件环境,实现基于16KB大小的页面进行虚拟内存管理的操作系统,系统支持First Fit、Best Fit、Buddy System三种页分配算法,支持进程管理,每个用户进程通过各自的虚拟内存空间访问物理内存,支持CFS进程调度算法。
由于本项目中虚拟地址有效位数为47位——PTE中的三个分段和页偏移共四个段,各比sv39的设计长2位,本文中有时以sv47的说法指代我们的设计。
项目分支说明: 本项目有多个分支,master分支为主要运行分支,但考虑到在展示过程中有可能需要切换进程调度算法,页面分配算法等,其他分支均为方便展示而用。
项目测试输出说明: 为方便助教查看输出,我们将输出重定向到txt,其中default_all.txt包含对于default scheduler, default swap,default pmm 的输出测试,在主目录中可以查看。
构建qemu环境与操作系统并运行
$ cd 16kos-qemu
$ make clean && make
$ cd ..
$ source setup_env.sh
$ make clean && make && make qemu 使用gdb调试系统
$ make clean && make && make qemu-gdb # listens on port 1234本章节解释为使系统支持按16k大小分页,而非常规的4k分页,所进行的设计与代码实现。
在官网下载qemu-5.0.0源代码包,以sv39为关键字,在三个目录下可以找到相关宏定义,检查后发现其中roms/u-boot/arch/riscv/include/asm和roms/opensbi/include/sbi两个目录下的宏定义没有实际使用,故只需要关注target/riscv目录下的宏定义。
根据20211203版RISC-V特权指令集手册的说明,satp的高4位MODE段保留14-15两个值用于自定义模式,我们定义sv47占用MODE字段值14。我们在qemu中添加sv47模式的宏定义,声明该模式有效,并添加相应的支持。此外,检查发现target/riscv/cpu_bits.h文件中PGSHIFT宏在qemu中的地址转换实现中有使用到,这个值与satp中MODE字段无关地被设置为12,考虑到RISC-V所有基于页的虚拟内存管理系统都使用4k页倒也合理,这里我们将其设置为14。
根据@yuki同学的提醒,target/riscv/cpu-param.h文件中TARGET_PAGE_BITS宏也需要由12修改为14,检查发现另一个宏TARGET_PAGE_SIZE与其有关,该宏在代码中多处被引用。
下图为虚拟地址格式图示

虚拟地址VA(Virtual Address)包括三段VPN(Virtual Page Number)和页偏移四个段。页面大小为16kb = (1 << 14)b,故页偏移长度为14,页表项大小为8字节,每页可以放置16k >> 3 = 2k = (1 << 11)个页表项,故三段VPN长度均为11,虚拟地址长度合计11 + 11 + 11 + 14 = 47,虚拟地址可以寻址(1 << 47)b = 128tb范围。
下图为物理地址格式图示

物理地址PA(Physical Address)包括三段PPN(Physical Page Number)和页偏移四个段,其中PPN总长度为44,这是由页表项中PPN字段的长度决定的,二者相等。物理地址中PPN[1]、PPN[0]和页偏移三段与虚拟地址中相应的VPN和页偏移段长度相等,即PPN[1]和PPN[0]段长度为11,页偏移段长度为14,故PPN[2]长度为44 - 11 - 11 = 22。物理地址总长度为22 + 11 + 11 + 14 = 58,物理地址可以寻址(1 << 58)b = 256pb范围。
下图为PTE/PDE格式图示,在20211203版的特权指令集标准中高10位被分为3个保留段,其中两个分别给特定的指令集拓展使用。在这些拓展均没有实现时,高10位均应置0,我们的系统实现中只需要这样全部置0就可以,因此也不对这三个段作区分。

页表项PTE(Page Table Entry)与页目录项PDE(Page Directory Entry)每项大小仍为8字节,PTE/PDE[9:0]为标志位,PTE/PDE[63:53]为保留位,这与sv39的设计相同,不同之处在于PTE/PDE[53:10]这44位所表示的PPN的三个分段的分隔位置的改变,三段分别为PTE/PDE[53:32],PTE/PDE[31:21],PTE/PDE[20:10],长度为22 + 11 + 11 = 44。PTE与PDE格式相同,区别方法在于后者RWX三个标志位均为0而前者不然。
target/mm/swap.c中的check_content_set函数构造了一组对虚拟地址的访问,并对page fault发生的次数进行断言,首次访问一个未分配的页时,会触发page fault分配物理页,使得计数加一,据此可以判断页的大小。对4k os的测试代码如下
// ...
*(unsigned char *)0x1000 = 0x0a;
assert(pgfault_num==1);
*(unsigned char *)0x1010 = 0x0a;
assert(pgfault_num==1);
*(unsigned char *)0x2000 = 0x0b;
assert(pgfault_num==2);
// ...4k os能通过完整测试,而在我们的16k os中进行该测试,会在第三条断言处报错,说明此时并没有发生新的page fault。我们修改测试访问的地址
// ...
*(unsigned char *)0x4000 = 0x0a;
assert(pgfault_num==1);
*(unsigned char *)0x7fff = 0x0a;
assert(pgfault_num==1);
*(unsigned char *)0x8000 = 0x0b;
assert(pgfault_num==2);
// ...在16k os中通过完整测试。每次访问之前没有访问过的16k大小的地址范围时,计数才加一,说明发生新的page fault,故我们认为页大小确实是16k。
通过检查qemu源代码中target/riscv目录下的代码,很容易发现用于VA到PA转换的函数get_physical_address,其中只有一个出口返回"转换成功"的信号,我们在这里输出sapt、VA、PA作为调试信息。
// target/riscv/cpu_helper.c get_physical_address
printf("debug: get_physical_address: translate success\n");
printf("debug: get_physical_address: env->satp = 0x%016lx va = 0x%016lx pa = 0x%016lx\n", env->satp, addr, *physical);
return TRANSLATE_SUCCESS;我们截取了一张调试信息输出,这里输出的pa是页基址。图中同时出现了用户态进程访问用户空间,和触发时钟中断后内核访问内核空间的情景,两者都通过虚拟地址正确地转换得到了物理地址,因此我们认为我们的16k os能够在修改后的qemu上正确地进行地址转换。

空闲物理页内存管理由ucore实现,关键部分由kern/mm/pmm.c中page_init函数与pmm_manager具体实现的init_memmap函数实现,在page_init函数中对齐计算可用于构建空闲页的内存空间范围,并在init_memmap中构建相应的内核数据结构,通过对数据结构的维护实现对物理页的管理。
页分配算法定义了如何具体地维护上一节所述的数据结构。
First Fit页分配算法由ucore实现在kern/mm/default_pmm.c中,算法在初始化时将所有的空闲页组按地址顺序维护在一个链表中,每个空闲页组包括连续的若干空闲页,需要分配空闲页时,算法找到链表中第一个满足需求页数目的空闲页组,并从中进行分配。需要回收页时,算法根据地址把回收的页组插入到链表中相应的位置,并检查是否能与前后的空闲页组进行合并。First Fit算法的验证由ucore内置,由于不是我们写的代码,我们仅提供运行结果。
我们将Best Fit页分配算法实现在kern/mm/best_fit_pmm.c中,该算法与Best Fit算法的区别在于,其在分配空闲页时选择的是最合适的——在满足需求页数目的前提下最小的——空闲页组,而不是第一个满足需求页数目的空闲页组。Best fit 算法基本扩展于First fit 算法. Best Fit算法的验证主要进行与first fit 不同之处的验证, 在由lab课代码实现first fit验证算法上我们额外加入以下测试
Best fit 实现思路:主要是在alloc 分配的时候添加一个while的循环,然后找到最合适的那一个,主要都是建立在已经有的lab课自带的First fit的基础上。
int min_distance = 2147483647;
while ((le = list_next(le)) != &free_list) {
struct Page *p = le2page(le, page_link);
if (p->property >= n && p->property - n < min_distance) {
min_distance = p->property - n;
page = p;
}
}
Best fit 测试思路:
struct Page *p0 = alloc_pages(12), *p1, *p2;
free_pages(p0 + 2, 3);
free_pages(p0 + 7, 2);
cprintf("p0+7 ppa: %x\n", page2pa(p0 + 7));
cprintf("p0+2 ppa: %x\n", page2pa(p0 + 2));
p1 = alloc_pages(2);
assert(p1 == p0 + 7);
测试Best fit算法思路是先alloc 12个页面,然后再分批次还回去大小是2,3的连续页表,再分配一个大小是2的页表,这时候如果是First fit会直接分配第一个出去,但是Best fit会寻找到大小最合适的那个,最后通过了测试。

我们将张教授上课教的算法实现在'kern/mm/buddy_pmm.c'中,其中维护1,2,4,8,16,32,64,128,256,512,1024 大小的连续页表的数组。每个数组的头列表都是一个free_area结构体,在之后连接属于这个大小的连续页面。所有的空闲页表都是放在这个core_array数组中的,
#define MAX_NUM 11
free_area_t free_area;
free_area_t core_array[MAX_NUM];
int tool_array[11] = {1,2,4,8,16,32,64,128,256,512,1024};
每次alloc page 之时,先寻找到大于等于这个需求页面的大小,然后整块分配,把多余的页表还回数组中。这一点的设计能让我们的buddy system 实际上可以分配任意大小的页面,不只是2的倍数:
//截取于 buddy_alloc_page function,更加完整的代码由于报告篇幅问题请详见源文件'kern/mm/buddy_pmm.c'
page = _buddy_alloc_pages_by_index(temp_index);
if(tool_array[temp_index] == n){
ClearPageProperty(page);
return page; // Which means that it just proper;
}else
{
assert(n < tool_array[temp_index]);
struct Page * page_to_free = page + n;
page_to_free->property = page->property - n;
page->property = n;
free_page_buddy(page_to_free, page_to_free->property);
ClearPageProperty(page);
}
在free页面的时候,需要考虑是否能和周围的页表项进行合并,然后升级。有可能会free超过1024个,所以当超过1024大小时,继续调用这个函数。比如在操作系统最开始会直接分配8007个页面,这个时候我也认为是free而没有为init单独写一个函数。add_page_into_list这个函数是最后加入到core_array的函数,在这里需要注意的要 调用SetPageProperty对于那些要成为“队长”的页表项。在合并之后需要调用 merge_page。 在实现对于PAGE FLAG 的管理上面,我们采取和First fit相同的管理方式,是free page 并且是链表头部,我们会对应page SetPageProperty。
static void
free_page_buddy(struct Page *base, size_t n){ // this method handle the page which is smller or equal or bigger than 1024
// This is the main function of free page
assert(n > 0);
int temp_index= -1;
for(int i=MAX_NUM-1;i >=0;i--){
if (tool_array[i] <= n){
temp_index = i;
break;
}
}
if(temp_index == -1){
temp_index = MAX_NUM - 1;
}
assert(temp_index >= 0);
int rest = n - tool_array[temp_index];
add_page_into_list(base,temp_index);
// cprintf("call the free_page_buddy function, and the rest is %u, and the temp_index is %u \n",rest,temp_index);
if( rest > 0){
free_page_buddy( base + tool_array[temp_index], rest);
}
return;
}
static void add_page_into_list(struct Page *base, int index){
uintptr_t current_pa = page2pa(base);
list_entry_t * head = &(core_array[index].free_list);
list_entry_t * temp = head->next;
base->property = tool_array[index];
SetPageProperty(base);
list_add(&free_area.free_list,&(base->page_link));
free_area.nr_free += base->property;
if( temp == head){
list_add(head, &(base->buddy_link));
core_array[index].nr_free ++;
return;
}
while (1)
{
uintptr_t temp_pa = page2pa(le2page(temp,buddy_link));
if (temp_pa > current_pa){
list_add_before(temp, &(base->buddy_link));
break;
}
temp = temp->next;
if(temp == head){
list_add_before(head, &(base->buddy_link));
break;
}
}
core_array[index].nr_free ++;
merge_page(base,index);
return;
}
判定能否进行合并关键性代码如下。我们采取张教授所提示的依据物理地址或者物理页号的二进制位数结合掩码的形式判断,比如对于页表项大小是1,我们判定物理页面地址前(32-15)位是相同的即可合并。merge这个函数是可以递归的。:
(pre_pa >> (shift_how_many_bit + index)) == (current_pa >> (shift_how_many_bit + index))
// shift_how_many_bit = 14+1,这个值是16kos决定的,是一个宏,可以根据页表大小进行修改
在对于free_area 的遗留问题,这个遗留问题是指在swap的测试中,会检查free_area中空闲的页表的数目,然后我们在实现buddy的时候没有使用这个变量。为了别的地方能继续使用free_area,我们单独使用了buddy_link,并且在对buddy数组维护的过程中,依旧维护free_area所代表的free_page的链表。
struct Page {
int ref; // page frame's reference counter
uint64_t flags; // array of flags that describe the status of the page frame
unsigned int property; // the num of free block, used in first fit pm manager
list_entry_t page_link; // free list link
list_entry_t pra_page_link; // used for pra (page replace algorithm)
uintptr_t pra_vaddr; // used for pra (page replace algorithm)
list_entry_t buddy_link; //used for buddy system
};
buddy system的优势:
对于buddy system 主要相比于First fit有更少的外碎片,对比Best fit 而buddy system能在大部分情况以O(1)的时间分配,尤其是在小页面分配需求比较多的情况下,而Best fit 往往在寻找到不错的解之后,依旧会搜寻整个空闲页表队列。但是对于时间比较少这点由于我的buddy system没有使用红黑树实现,所以无法给出证明,只能在如下给出正确性证明。
buddy system验证:
我们测试buddy system的方法主要是自己写的测试函数: 在basic_check()函数中,我们会先分配3个页面,然后打印输出整个数组的链表,在把页面还回去的时候,也打印输出整个链表,其中会assert总的页面的数量和free_area.nr_free
size_t temp_nr = nr_free_pages();
print_nr();
struct Page *p0, *p1, *p2, * p3, *p4;
p0 = p1 = p2 = NULL;
assert((p0 = alloc_page()) != NULL);
assert((p1 = alloc_page()) != NULL);
assert((p2 = alloc_page()) != NULL);
cprintf("p0 physical address %x \n",page2pa(p0));
cprintf("p1 physical address %x \n",page2pa(p1));
cprintf("p2 physical address %x \n",page2pa(p2));
cprintf("It can prove that we make the page to 16KB\n");
p3 = alloc_pages(4);
p4 = alloc_pages(1023);
print_nr();
free_page(p0);
free_page(p1);
free_page(p2);
print_nr();
free_pages(p3,4);
free_pages(p4,1023);
assert(temp_nr == nr_free_pages());
assert(temp_nr == free_area.nr_free);


可以看见的是,在前一次的页表中level2的页表有1个,在还回去3个页表的时候进行页表的合并,会发现level2的页表变成0个。故此发生了页表的合并,再加上数次对于assert的判断,可以验证buddy system的正确性。在这里会有一个设计就是当你先申请3个页面,再分配3个页面不会回到原来的状态。这是因为在合并的时候我们是按照根据地址右移相应的位数之后数字是否相同来确定是否能合并。但是在最开始是分配8007个初始的页表,然后在这个时候进行的拆分却不一定是按照合并的规则来的,因为我们无法控制最开始物理地址的分配是从哪里开始分配的。
多进程操作系统支持基于页的虚拟内存管理的关键在于,如何恰当地初始化与维护由satp维护的一级页表物理页号信息,和由结构体mm_struct维护的虚拟内存区域(VMA, Virtual Memory Area)信息。前者的切换实现了虚拟内存空间切换,后者维护了进程可访问的内存区域的信息。
进程管理由ucore实现,进程结构体均通过kern/process/proc.c中的alloc_proc创建,satp初始化为boot_cr3即我们在系统启动最开始写入到satp的物理页的基址,mm(mm_struct实例的指针)初始化为NULL。内核进程简单地根据boot_cr3设置satp,并且不创建新的mm_struct实例用于维护虚拟内存信息——其页表能够映射到所有有效的物理地址,内核进程可访问的内存也不需要VMA来约束。用户进程在kern/process/proc.c的load_icode函数中创建新的mm_struct实例并配置VMA信息,为一级页表分配内存页并添加对其基址信息的维护。
通过进程调度切换进程时,satp作为上下文更新,mm随着内核维护的当前进程结构体指针的更新而更新,从而实现了虚拟内存空间的正确切换。
该进程管理的实现是由lab课代码迁移,通过运行ex3.c进行测试
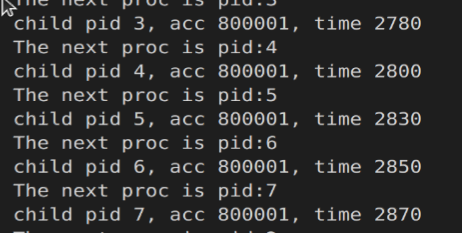
可以看到最后所有进程是完全按照3,4,5,6,7,的顺序结束的,并且结束的时间基本一致。
我们对于CFS进程调度算法进行实现在'kern/schedule/cfs_shed.c',对比算法是轮转优先级直接调度算法,实现在'kern/schedule/rr_q_shed.c'. CFS算法其中核心的思想是通过所谓的优先级的设置来计算核心调度指标vruntime。优先级高的任务每次被调度的时间会更长,但是由于vruntime的存在,它的vruntime比较大,而每次我们在调度的时候会选择vruntime最小的那个,所以优先级高的任务被调度的可能性更小,被调度的次数也更少。所以在完全公平调度算法里面,所谓的优先级设置高或者低不会影响实际的运行时间。这个我们也通过ex3进行了测试,当我们把一个程序的所谓的优先级设置成50后,另外的优先级设置成1,2,3,4.最后5个进程几乎是在一起完成同样大小的任务,所以该调度算法最大保证了公平性。而如果是剥夺性优先级调度算法会完全先执行完优先级高的任务。如果是轮转优先级直接调度算法,会按照优先级线性分配时间片,也对低优先级任务不公平。

对于CFS的测试: 完全公平调度本身的设计核心就是更加敏捷的调度和更加公平的调度。在测试CFS的时候,我们采用之前asssignment3的ex3进行测试。ex3中给的优先级的值如下:

轮转优先级直接调度算法,这个是在assignment3中实现的算法,优先级越高每次实现的时间片越大。
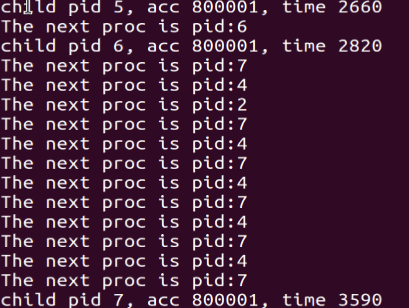
可以看见的是,对于轮转优先级直接调度算法,理论上一个user process故意设计高优先级的进程,那么总是可以获得更长时间的调度。我们可以看见优先级是50的进程运行完的时间远短于其他优先级的进程。
对于CFS调度的结果如下:
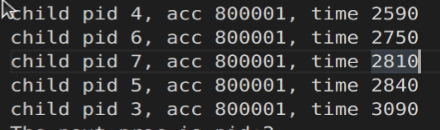
无论某个进程主动设置的这个所谓的优先级有多高,其实最后大家被结束的时间都差不多。调度算法如其名,completely fair scheduler,至于写这个bonus part的原因是张教授在上课大约花了半节课讲这个linux系统实际使用的进程调度,故想实现出来亲自测试下就算所谓的优先级高,能不能违反公平性的约定。
这一章节用于记录一些项目设计与实现过程中我们认为有意思的点,结果上来说,实际的时间投入反而不少体现在这些琐碎的"点"上——尤其是本次项目的基础部分要求不少已经被ucore实现了,我们需要做的代码量并不算大的情况下。对这些内容的思考与探索也是让我们有所收获的。
为了从没有虚拟内存管理切换到分页虚拟内存管理,我们做了一系列设计。
在kern/init/entry.S的kern_entry部分,ucore原有的实现通过lui reg, %hi(symbol)的方法取得符号(symbol)的高位,在sv47沿用这种做法会在链接时出现包含如下片段的报错
... relocation truncated to fit: R_RISCV_HI20 against symbol ...
查阅资料得知,%hi对操作符号的地址范围有所限制,因此需要用其他方法来获取符号地址。
我们使用la reg, symbol。la的作用是将符号地址载入到寄存器中,其作为伪指令,在汇编时翻译为真指令序列。由于我们在kernel.ld中将BASE_ADDRESS设置为高地址的虚拟地址值,乍看起来la似乎会加载得到虚拟地址,但查看汇编可以注意到la翻译得到的指令序列中出现的,用于得到符号相关的地址的关键指令auipc。由于内核代码实际加载在低地址的物理地址处,在我们在配置好虚拟内存管理并更新pc到虚拟地址——这件事会在我们跳至符号kern_init时发生,这个符号由于BASE_ADDRESS的设置而在高地址处——之前,pc维护的仍是低地址的物理地址。因而不同于ucore的sv39实现通过恰好的构造先得到虚拟地址,我们通过la取符号地址得到的是物理地址,如需要虚拟地址则对物理地址加上偏移量0xffff_fff0_0000_0000得到。
我们在上一个问题的讨论中提到,无论是sv39还是sv47的实现,控制流刚进入内核时,pc的值是低地址的物理地址。当satp被更新后,只有我们预先设置的,虚拟地址空间地址最高的一个吉页(由一级页表中的页表项直接建立映射的页)是可以被访问的,但此时pc尚未更新为高地址的虚拟地址,此时pc应该在顺序执行指令的过程中访问到非法地址,导致程序异常退出。然而ucore的sv39实现能够正常运行,这已与我们的分析相违悖,不过我们确实找到了能够佐证我们这一分析的现象:使用gdb调试,在单步执行到satp的更新后,继续单步执行将导致gdb给出如下报错
Warning:
Cannot insert breakpoint 1: Cannot access memory at address 0x80200000
Command aborted.
这与我们的分析是相符的。
为了确认为什么在实际使用qemu模拟的过程中并没有出现这个问题,需要进一步地阅读qemu源代码。我们的一种猜想是这可能是由一种类似指令预取的机制实现的,但是这破坏了基于页的虚拟内存管理机制的内存保护功能,似乎应当视为一种"预测错误"。
不管怎么说,我们可以用一种更"优雅"的方式启用虚拟内存管理机制,在原有设计的基础上,我们将内核一级页表的第一项也布置为有效,并且虚拟地址与物理地址"直接映射",即虚拟地址映射到相等的物理地址,使得启用分页机制后,仍维护物理地址的pc可以正常访问代码段,等效于维护了虚拟地址。在控制流跳转到kern_init后,pc已被更新为高地址的虚拟地址,我们再擦除"直接映射"的页表项使其无效,具体实现如下
# kern/init/entry.S
# ...
boot_page_table_sv47:
.quad 0xcf # VRWXAD # invalid in previous design
.zero 8 * ((1 << PGLEVEL_BITS) - 1 - 1)
.quad 0xcf # VRWXAD// kern/init/init.c
int
kern_init(void) {
extern uint64_t boot_page_table_sv47[];
boot_page_table_sv47[0] = 0;
// ...
}这部分感谢@cobalt-27同学与我们一同交流与查找资料。
启用sv47后,我们在测试用户进程的运行时遭遇了一点阻碍,在通过kern/process/proc.c的kernel_execve函数发起sys_execve系统调用后发生了无法处理的page fault,经过一番调试,我们发现在作为参数传给系统调用的地址0xffff_fff0_8xxx_xxxx,在系统调用处理函数中变成了0xffff_ffff_8xxx_xxxx,怀疑是地址在某处发生了低32位截断再符号扩展,最终发现是其在内联汇编中布置系统调用的参数时使用的是lw而非ld。参数传递范围由32位改成64位可以得到更强的鲁棒性或者满足正确性?但它原来的实现应该也不能算错,在sv39实现中由于地址高32位[63:32]由第31位符号扩展得到的做法总是恰好是正确的,因而没有暴露问题。我们做如下代码修改后系统调用能够正常传递参数,问题得到解决。
asm volatile(
"li a0, %1\n"
"ld a1, %2\n" // previously "lw a1, %2\n"
"ld a2, %3\n" // previously "lw" too
"ld a3, %4\n" // ... too
"ld a4, %5\n" // ... too
"li a7, 10\n"
"ebreak\n"
"sw a0, %0\n"
: "=m"(ret)
: "i"(SYS_exec), "m"(name), "m"(len), "m"(binary), "m"(size)
: "memory");看来课程lab给的代码里看来不少实现是从32位实现搬过来的,包括其内置的print_trapframe等调试输出函数也是按寄存器32位长度实现的。
在上面的内联汇编代码片段中,我们获取返回值用的仍然是sw而非sd,因为ucore的既有实现里系统调用处理函数的返回值类型,无论是内核实现还是用户库用的都是int,64位实现应该把这些int全部改成64位的数据类型,以使得一次系统调用能够传递64位的返回值如地址。考虑到这种纯体力劳动的填坑没什么意思干脆能用就行我们就没继续改了
提到%hi取符号地址时地址范围的限制,我们测试发现不止在code model为默认的编译参数-mcmodel=medlow时存在这个限制,参数-mcmodel=medany时也有这个现象。
riscv-collab/riscv-gnu-toolchain#103