- downlad the files named in # data source and keep them in the project folder with .cpp and .h files.
- run the c++ file.
Note: These tsv files from idmb are quite large. Rather read the c++ code or see the data structure of IDMB tsv files and make your own tsv files/file entries.
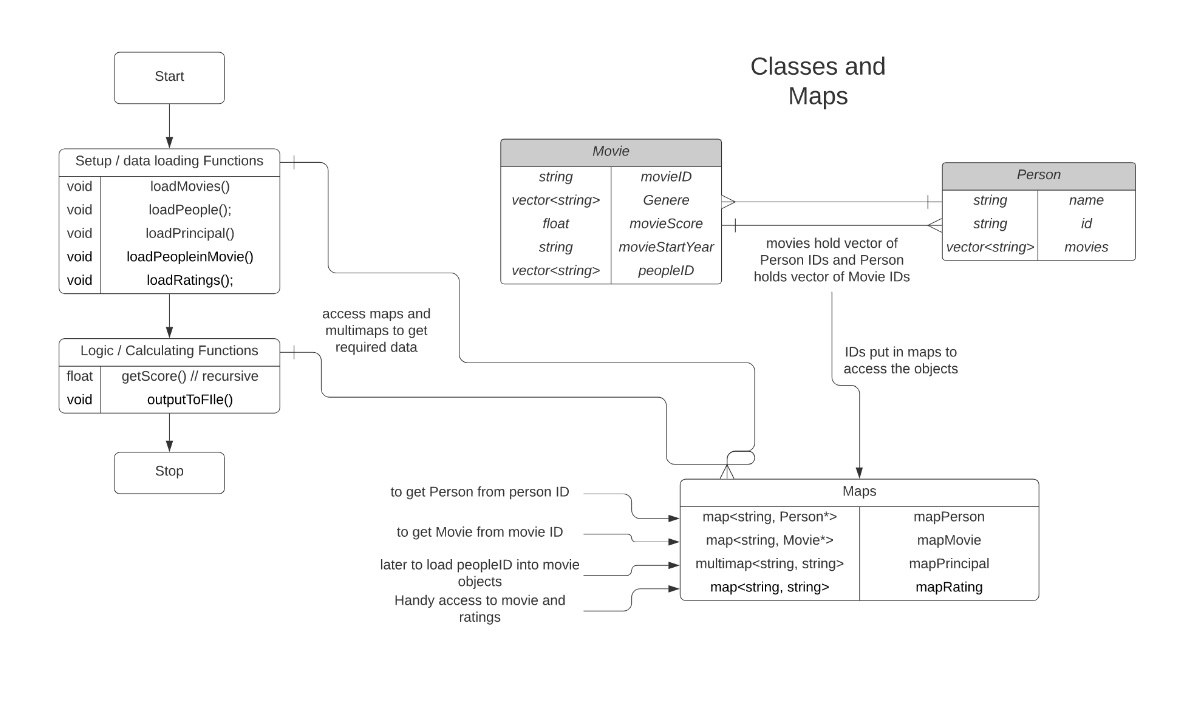
- suppose each movie has a score, and score of the person is addition of scores of his movies. This is the basic logic (depth/indirection 1).
- now if we extend the logic.. the score of the preson is sum of scores of movies of people that participated in the movie with the person(depth/indirection 2).
- now a tree starts forming of movies and people, where root node being the perosn whose score we want to find for any given depth of the tree.
- the above can be easily achieved with BFS algorithm
- we have STL liabrary, wherin we can use vectors, maps, multimaps and iterators to iterate over them.
- fstream can be used to write to output file
- sstream can be used to break the strings into relevant data (Data Analysis)
- for reference
- one can get below files from IDMB website (https://www.imdb.com/interfaces/)
- Four files are used:
-
name.tsv: information on each person: nconst, primaryName, birthyear,deathYear,primaryProfession, knownForTitles. nconst is the unique identifier. Some title do not have a birthYear, instead it is “\N”. When a person does not have a birthYear, the year 1900 is used.
-
title.tsv: information on each movie: tconst, titleType, primaryTitle, originalTitle, isAdult, startYear, endYear, runtimeMinutes, genres. tconst is the unique identifier. Some title do not have a startYear, instead it is “\N”. When a movie does not have a startYear, the year 2200 is used. Some genres can be empty, with the value “\N”.
-
principals.tsv: person and their role per title: tconst, ordering, nconst, category, job, characters. Per movie (tconst), per person(nconst) the category(actress-actor, director, producer, editor..) they had.
-
ratings.tsv: rating per movie: tconst, averageRating, numVotes
- Read readme.txt for more clear understanding.