Official implementation for our CVPR 2026 paper "Overthinking Causes Hallucination: Tracing Confounder Propagation in Vision Language Models".
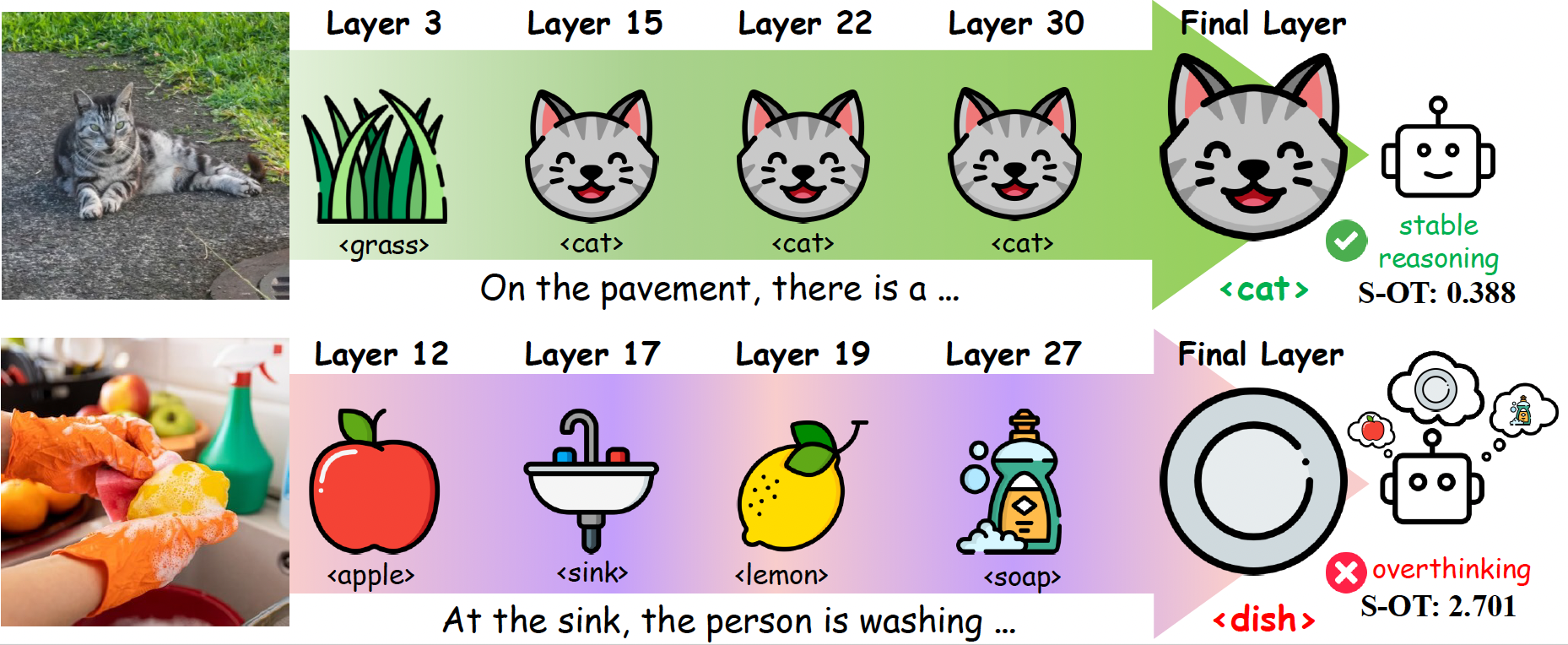
Our key finding: Vision-Language Models can "overthink" and hallucinate. As VLMs process an image across decoder layers, they keep revising their belliefs about the visual content. When an incorrect hypothesis emerges, it can act as a confounder that propagates through subsequent layers, eventually leading to a hallucinated answer. We introduce an Overthinking Score that captures this internal instability and helps detect hallucinations.
The pipeline supports three VLMs out of the box: LLaVA-1.5, Qwen3-VL, and Gemma3.
For each generated token, we probe the model's internal states and extract three families of features:
- Layer-wise entropy (
H_i) — uncertainty of the next-token distribution at each transformer layer - Image attention (
IA_i) — how strongly the last token attends to visual tokens at each layer - Text attention (
TA_i) — how strongly the last token attends to non-visual (text) tokens at each layer - Overthinking score — a composite metric combining mean entropy and prediction diversity across layers
These features are used to train a binary classifier (Logistic Regression, Gradient Boosting, or MLP) to distinguish grounded tokens (label 0) from hallucinated tokens (label 1).
.
├── feature_extract.py # Feature extraction pipeline (LLaVA, Qwen3, Gemma3)
├── train_evaluate.py # Classifier training & evaluation (LR, GB, MLP)
├── Dockerfile # Docker environment (NVIDIA PyTorch 23.12 base)
├── docker_run.sh # Launch script with GPU support + Jupyter
├── requirements.txt # Python dependencies
└── data/
├── LLaVA-1.5/
│ ├── llava_train.jsonl
│ └── llava_test.jsonl
├── Qwen3/
│ ├── qwen_train.jsonl
│ └── qwen_test.jsonl
└── gemma/
├── gemma_train.jsonl
└── gemma_test.jsonl
Two Dockerfiles are provided depending on the target model:
| Dockerfile | Models | Base Image |
|---|---|---|
Dockerfile |
LLaVA-1.5 | nvcr.io/nvidia/pytorch:23.12-py3 |
Dockerfile_new_transformer |
Qwen3-VL, Gemma3 | nvcr.io/nvidia/pytorch:23.12-py3 + PyTorch 2.6, Transformers 4.57 |
Qwen3-VL and Gemma3 require a newer transformers library (4.57) and updated PyTorch (2.6.0), which are installed in Dockerfile_new_transformer.
# For LLaVA-1.5
docker build -f Dockerfile -t detect .
# For Qwen3-VL or Gemma3
docker build -f Dockerfile_new_transformer -t detect_new .bash docker_run.shThe script starts a container with full GPU access, mounts your data at /workspace/data and your code at /workspace/code, and launches a Jupyter Notebook server on port 8788.
Each .jsonl file contains one JSON object per line with the following fields:
| Field | Type | Description |
|---|---|---|
image_id |
str | Unique identifier for the image |
image |
str | Filename of the image (relative to image_dir) |
description |
str | Caption/description generated by the VLM |
grounded_tokens |
list[str] | Tokens that are visually grounded |
hallucinated_tokens |
list[str] | Tokens that are hallucinated |
annotations |
any | Ground-truth annotations |
captions |
any | Reference captions |
Images are expected in a directory such as /workspace/data/COCODataset/val2014/val2014.
Extract internal model features for each token in the dataset:
python feature_extract.py \
--input_data_path ./data/LLaVA-1.5/llava_train.jsonl \
--output_data_path ./data/LLaVA-1.5/train_features.csv \
--image_dir /path/to/COCO/val2014 \
--model_path /path/to/llava-v1.5-7bFor Qwen3-VL:
python feature_extract.py \
--input_data_path ./data/Qwen3/qwen_train.jsonl \
--output_data_path ./data/Qwen3/train_features.csv \
--image_dir /path/to/COCO/val2014 \
--model_path /path/to/Qwen3-VLFor Gemma3:
python feature_extract.py \
--input_data_path ./data/gemma/gemma_train.jsonl \
--output_data_path ./data/gemma/train_features.csv \
--image_dir /path/to/COCO/val2014 \
--model_path /path/to/gemma3Arguments:
| Argument | Default | Description |
|---|---|---|
--input_data_path |
./data/LLaVA-1.5/train_migrate_2.jsonl |
Path to input JSONL file |
--output_data_path |
./data/LLaVA-1.5/train_features.csv |
Path to save extracted features (CSV) |
--image_dir |
/workspace/data/COCODataset/val2014/val2014 |
Directory containing COCO images |
--model_path |
/workspace/data/pretrained/llava-v1.5-7b |
Path to pre-trained VLM checkpoint |
Train a hallucination detector on the extracted features:
python train_evaluate.py \
--train_path ./data/LLaVA-1.5/train_features.csv \
--test_path ./data/LLaVA-1.5/test_features.csv \
--model_type LR \
--output_csv ./results/metrics.csv \
--model_save_dir ./saved_modelsArguments:
| Argument | Default | Description |
|---|---|---|
--train_path |
./data/LLaVA-1.5/train.csv |
Path to training features CSV |
--test_path |
./data/LLaVA-1.5/test.csv |
Path to test features CSV |
--model_type |
LR |
Classifier type: LR, GB, or MLP |
--output_csv |
./results/metrics.csv |
Where to append test metrics |
--model_save_dir |
./saved_models |
Directory to save the best model |
Supported classifiers:
LR— Logistic RegressionGB— Gradient BoostingMLP— Multi-Layer Perceptron
All classifiers are validated on a held-out 10% split of the training data. The best model and threshold are saved to model_save_dir.
- Feature CSV — one row per (image, token, position) triple, with entropy, overthinking score, attention, and top-k token columns
./results/metrics.csv— appended with test-set metrics (accuracy, macro F1, AUC, AP, per-class precision/recall/F1) and best hyperparameters for each run./saved_models/best_<MODEL>.pkl— serialised best classifier (and threshold for GB)
| Model | Identifier (in path) | Notes |
|---|---|---|
| LLaVA-1.5 | llava |
Requires ./models/LLaVA submodule |
| Qwen3-VL | qwen |
Requires transformers >= 4.x with Qwen3VLForConditionalGeneration |
| Gemma3 | gemma |
Requires transformers >= 4.x with Gemma3ForConditionalGeneration |
The model type is inferred automatically from the model path.
If you find this work useful, please cite our paper:
@inproceedings{overthinking2026cvpr,
title = {Overthinking Causes Hallucination: Tracing Confounder Propagation in Vision Language Models},
booktitle = {Findings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2026},
}This project is released for research purposes. Please refer to the respective model licenses (LLaVA, Qwen3, Gemma3) and the COCO dataset license for usage restrictions.