Canyu Zhao1, Hao Chen1, Yunze Tong1, Yu Qiao2, Jiacheng Li2, Chunhua Shen1,3,✉
1Zhejiang University 2Hithink 3Zhejiang University of Technology
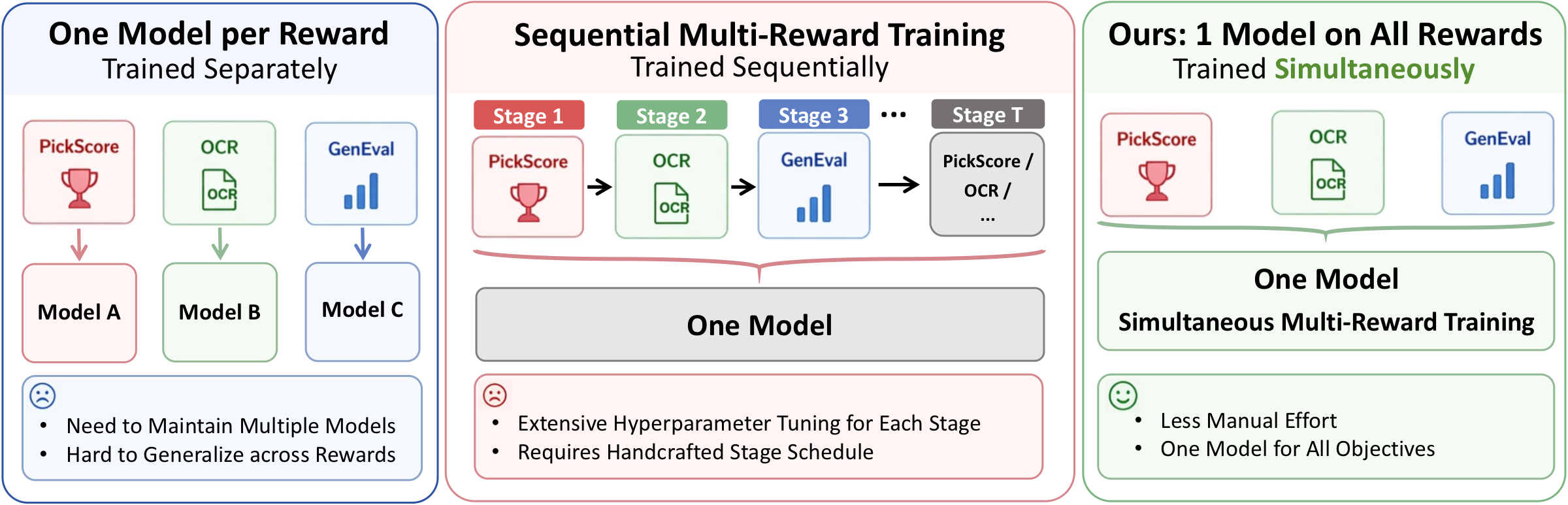
MARBLE is a multi-reward RL fine-tuning framework for diffusion models that preserves per-reward gradient information end-to-end and combines them in gradient space. Built on DiffusionNFT, MARBLE simultaneously improves different dimensions within a single model, without sequential training.
Why scalar reward aggregation fails. Specialist rollouts — prompts that only carry signal for a subset of rewards (a "cat on sofa" image carries no OCR signal) — get their reward-specific advantage diluted by averaging. Weighted-sum and sequential fine-tuning systematically trade specialist rewards for general ones. MARBLE solves this in gradient space, not by reward engineering.
🚧 Code release in progress. Inference + checkpoints first, training code later. ⭐ the repo to get notified.
- Inference + 🤗 LoRA checkpoints
- Training code, configs, multi-node scripts
- MARBLE for Video Model
| 🎯 One model, all rewards at once. | No sequential fine-tuning — joint training across all reward dimensions. |
| 🧩 Specialist rewards survive. | OCR / GenEval no longer collapse under joint training. |
| ⚡ ~1× single-reward cost. | Amortized MGDA + EMA-smoothed |
| 📈 Composite +1.12. | Best on every reward axis vs. all baselines (Table 1). |
See the project page for the full results table, training-dynamics curves, EMA-decay
If you find MARBLE useful, please cite:
@article{zhao2026marblemultiaspectrewardbalance,
title={MARBLE: Multi-Aspect Reward Balance for Diffusion RL},
author={Canyu Zhao and Hao Chen and Yunze Tong and Yu Qiao and Jiacheng Li and Chunhua Shen},
year={2026},
eprint={2605.06507},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2605.06507},
}MARBLE builds on DiffusionNFT. We thank the authors for their excellent open-source releases.