Pytorch implementation of a Generative Adversarial Network (GAN) for the purpose of digit generation, clothing article generation, and generation of human faces, using the MNIST, FashionMNIST, and CelebFaces datasets. The original paper can be found here.
In a GAN, there are two models which train each other through a minimax game – a generative model tries to create realistic data instances and a discriminative model classifies data as real or generated by the generative model. The generator is trained to fool the discriminator by making the generated data close to the original data distribution while the discriminator is trained to correctly differentiate between the generator’s output and the original data.
The MNIST dataset consists of 70k (60k train, 10k test) handwritten images of the digits 0 − 9. The FashionMNIST dataset is a dataset of 70k (60k train, 10k test)
images of articles of clothing taken from Zalando, an European fashion website. The CelebFaces dataset is a large-scale, unlabeled face attributes dataset with over 200,000 celebrity images. We split the train data into batches of size 64.
The following 3 model architectures are implemented:
- (
Vanilla-GAN-Generate-MNIST.ipynb) Consists of a generator & discriminator implemented with feed-forward layers. This was used for digit generation using theMNISTandFashionMNISTdatasets. - Experiment 1: (
CNN-GAN.ipynb) GAN using convolutional layers, and tested on all 3 datasets mentioned above. - Experiment 2: (
Wasserstein-GAN-Generate-MNIST-ipynb) Variant GAN known as a Wasserstein GAN (outlined here) was implemented, and its performance was compared to the original GAN model.
Vanilla GAN results on MNIST (0, 2, 5, 30 epochs)

Convolutional network results on FashionMNIST, MNIST, & CelebFaces. Pictured after 2-3 epochs

Wasserstein GAN results on MNIST (10 epochs)

Overall, the convolutional architecture produced the most clear results and did so much more quickly, taking only a few epochs.
- Mode Collapse: Occurs when the generator begins to create the exact same set of outputs continuously. As a result, the discriminator ends up learning to reject this specific set of outputs while the generator never leaves this set of outputs, because it is optimizing against the current discriminator. An example of this is pictured below, and this is the main issue that Wasserstein GANs aim to combat:

We noticed that for the convolutional architecture in particular, normalizing input channels helped to avoid large variance in pixel values, ultimately helping the network avoid mode collapse and loss of information.
- Vanishing Gradients: In the first few epochs of the Vanilla GAN, the discriminator loss sharply decreases as the discriminator gets better at determining which images are real or fake. The generator loss sharply increases at first and continues to slowly increase. However, the losses never converge, and are generally unstable even after many epochs of training. This is due to the discriminator becoming too good, which can lead to vanishing gradients. This is shown in the plot below.
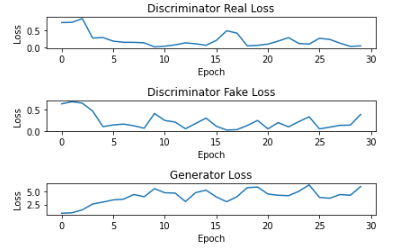
Loss plot of multilayer perceptron GAN on MNIST between 0-30 epochs