Allow AutoMLSearch to handle Unknown type #2477
There are no files selected for viewing
| Original file line number | Diff line number | Diff line change |
|---|---|---|
|
|
@@ -262,7 +262,7 @@ def test_per_column_imputer_woodwork_custom_overrides_returned_by_components( | |
| override_types = [Integer, Double, Categorical, NaturalLanguage, Boolean] | ||
| for logical_type in override_types: | ||
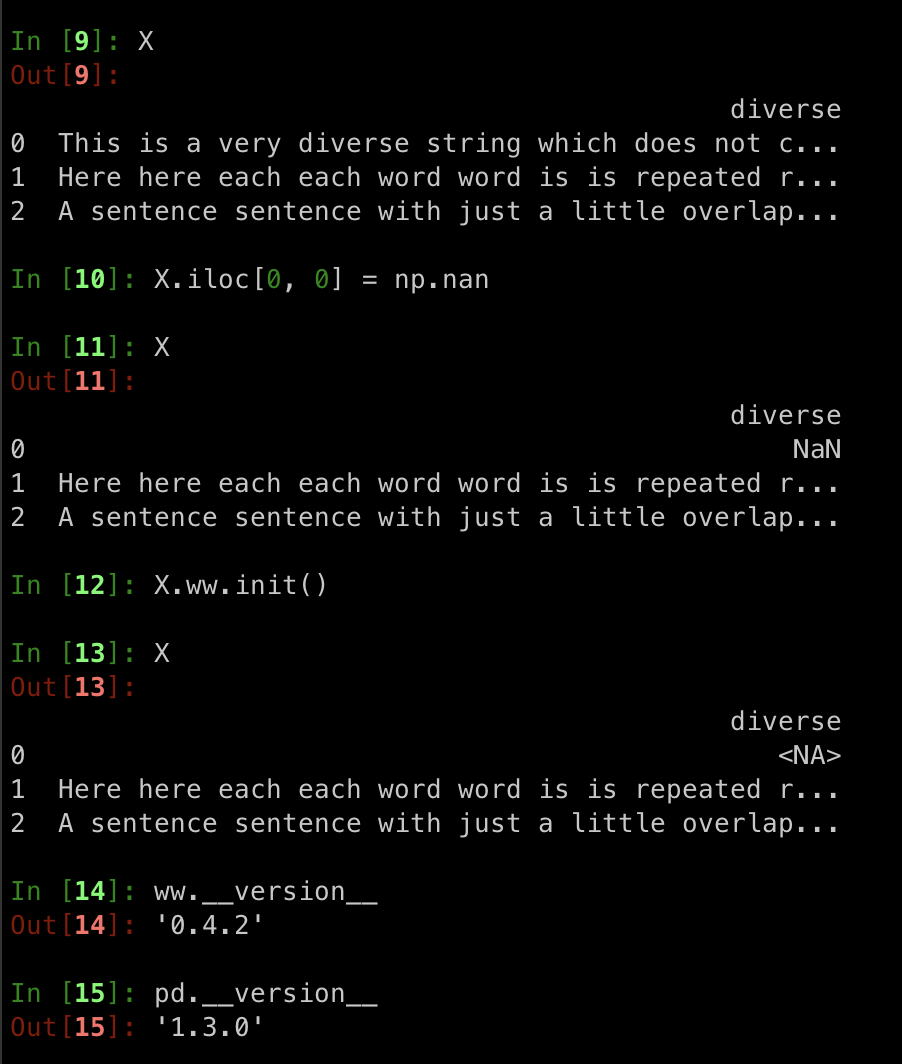
| # Column with Nans to boolean used to fail. Now it doesn't | ||
| if has_nan and logical_type in [Boolean, NaturalLanguage]: | ||
|
Contributor
Author
There was a problem hiding this comment. Leave out NaturalLanguage since casting this will result in
Contributor
There was a problem hiding this comment. But how come this wouldn't happen before? Woodwork doesn't convert
Contributor
Author
There was a problem hiding this comment. @freddyaboulton I believe it's due to the pandas upgrade!
Contributor
There was a problem hiding this comment. Thanks for looking into this @bchen1116 Let's list this as a breaking change for now. I imagine we might want to file an issue to discuss if there are any changes we need to make to the simpleimputer? If users run it on natural language after this pr they'll get a stacktrace they didn't get before.
Contributor
Author
There was a problem hiding this comment. @freddyaboulton updated the release notes with the breaking change and filed the issue here! |
||
| continue | ||
| try: | ||
| X = X_df.copy() | ||
|
|
||
Uh oh!
There was an error while loading. Please reload this page.