- Consistency: Every read receives the most recent write or an error
- Availability: Every request receives a (non-error) response – without guarantee that it contains the most recent write
- Partition tolerance: The system continues to operate despite an arbitrary number of messages being dropped (or delayed) by the network between nodes
-
The network is reliable
The first fallacy is an easy way to set yourself up for failure, as Murphy made sure there will always be things that go wrong with the network—whether it is power failure or a cut cable. However, Active Transactional Data Replication ensures that should a single server or an entire data center go offline, the information you need will still be available, as each data note is continuously synchronised without geographical constraints. -
Latency is zero
Latency is how much time it takes for data to move from one place to another (versus bandwidth, which is how much data can be transferred during that time). In the past, latency has deteriorated quickly when you move to WAN or internet scenarios. As more enterprises look to migrate operations to the cloud or move to a hybrid cloud structure, network latency can lead to an inability to back up data and restore it at speed in any given situation, including disaster recovery. Active Transactional Data Replication technology can now ensure transactional data can be moved to the cloud at petabyte scale with no downtime and no data loss, making it possible for on-premise and cloud environments to operate as one. -
Bandwidth is infinite
Bandwidth is the capacity of a network to transfer data. Even though network bandwidth capacity has been improving the amount of information we want to transfer, it is also increasing exponentially. But there are ways to increase bandwidth. Again data replication technology allows you to have multiple databases, meaning your system isn’t dependent on any one thing and you have more bandwidth at your disposal that can be controlled using network traffic shaping capabilities. This gives administrators the power to prioritize network traffic on the basis of source and target data centers and the ability to assign higher priority to specific files and directories during replication between data centers. -
The network is secure
The only completely secure system is one that is not connected to any network. Nevertheless, security is increasing all the time, as companies can deploy software solutions to ensure only external servers are exposed through the firewall, thereby reducing an organization’s vulnerability to hackers. -
Topology doesn’t change
Topology doesn’t change as long as it stays in the test lab. When applications are deployed into an organization, network topology can quickly become out of control with laptops coming and going, wireless ad hoc networks and new mobile devices. In fact, one of the biggest benefits for organizations moving to the cloud is the ability to change topology at will. As data can now be replicated across different environments with guaranteed consistency, issues around topology are no longer as relevant as they used to be. -
There is one administrator
While there is never just one administrator, given your applications are likely interacting with systems outside your administrative control, the impact of this is no longer as critical as it once was. The fact is you care about administrators only when things go awry and you need to pinpoint a problem and solve it. Even then with the same data available across multiple locations, organizations can now carry on with their work with no risk of downtime. -
Transport cost is zero
While nothing in life is free, the costs of setting and running a WAN network are considerably cheaper than they used to be. Cloud computing means you can purchase what you need per transaction, gigabyte or an hour. Active-active architecture means all servers and clusters are fully readable and writeable, always in sync and recover automatically from each other after planned or unplanned downtime. This means there are no passive read-only backup servers and clusters, so organizations can now use 100 percent of their hardware without wasting budget on idle servers. -
The network is homogenous
This fallacy was added to the original seven by Gosling, the creator of Java, in 1997. With the advent of mobile, no network today is homogenous, but an increasing number of tools are being built that do let you try out things across different networks and environments. The key point here is to ensure you have no vendor lock-in.
When a microservice architecture decomposes a monolithic system into self-encapsulated services, it can break transactions. This means a local transaction in the monolithic system is now distributed into multiple services that will be called in a sequence.
As its name hints, 2pc has two phases: A prepare phase and a commit phase. In the prepare phase, all microservices will be asked to prepare for some data change that could be done atomically. Once all microservices are prepared(validate if connection exist, if data valid, lock data), the commit phase will ask all the microservices to make the actual changes. Normally, there needs to be a global coordinator to maintain the lifecycle of the transaction, and the coordinator will need to call the microservices in the prepare and commit phases.
-
Benefits of using 2pc 2pc is a very strong consistency protocol. First, the prepare and commit phases guarantee that the transaction is atomic. The transaction will end with either all microservices returning successfully or all microservices have nothing changed. Secondly, 2pc allows read-write isolation. This means the changes on a field are not visible until the coordinator commits the changes.
-
Disadvantages of using 2pc While 2pc has solved the problem, it is not really recommended for many microservice-based systems because 2pc is synchronous (blocking). The protocol will need to lock the object that will be changed before the transaction completes. The lock could become a system performance bottleneck. Also, it is possible to have two transactions mutually lock each other (deadlock) when each transaction requests a lock on a resource the other requires.
The Saga pattern is another widely used pattern for distributed transactions. It is different from 2pc, which is synchronous. The Saga pattern is asynchronous and reactive. In a Saga pattern, the distributed transaction is fulfilled by asynchronous local transactions on all related microservices. The microservices communicate with each other through an event bus.
-
Advantages of the Saga pattern One big advantage of the Saga pattern is its support for long-lived transactions. Because each microservice focuses only on its own local atomic transaction, other microservices are not blocked if a microservice is running for a long time. This also allows transactions to continue waiting for user input. Also, because all local transactions are happening in parallel, there is no lock on any object.
-
Disadvantages of the Saga pattern The Saga pattern is difficult to debug, especially when many microservices are involved. Also, the event messages could become difficult to maintain if the system gets complex. Another disadvantage of the Saga pattern is it does not have read isolation. For example, the customer could see the order being created, but in the next second, the order is removed due to a compensation transaction.
Choreography - each local transaction publishes domain events that trigger local transactions in other services
 An e-commerce application that uses this approach would create an order using a choreography-based saga that consists of the following steps:
An e-commerce application that uses this approach would create an order using a choreography-based saga that consists of the following steps:
- The Order Service creates an Order in a pending state and publishes an OrderCreated event
- The Customer Service receives the event attempts to reserve credit for that Order. It publishes either a Credit Reserved event or a CreditLimitExceeded event.
- The Order Service receives the event and changes the state of the order to either approved or cancelled
Orchestration - an orchestrator (object) tells the participants what local transactions to execute
 An e-commerce application that uses this approach would create an order using an orchestration-based saga that consists of the following steps:
An e-commerce application that uses this approach would create an order using an orchestration-based saga that consists of the following steps:
- The Order Service creates an Order in a pending state and creates a CreateOrderSaga
- The CreateOrderSaga sends a ReserveCredit command to the Customer Service
- The Customer Service attempts to reserve credit for that Order and sends back a reply
- The CreateOrderSaga receives the reply and sends either an ApproveOrder or RejectOrder command to the Order Service
- The Order Service changes the state of the order to either approved or cancelled
Is an architectural style that structures an application as a collection of services.
- Start develop application with microservices architecture
S: Start app with monolithic architecture and then extract microservices - Don't care about database schemas, use one schema for several microservices.
S: Use independed microservices with they own database migrations, use one database per microservice if possible. - Don't use semantic versioning for (APIs, Messages, Libraries) S: Use API, Messages, Libraries versioning make deployment independed, it shouldn't crash full system.
- Don't mesure how much computer resources are you need to have stable sytem, don't recognize botlenecks
S: Use measurement tools, use Message queues to normilize load during critical load between microservices. - Hardcode IPs and ports in independent microservice
S: Use discovery services approach (Consul, etcd) it help you service to find correct url to dependent service and change them remotely.
S2: Use centralized router system (use domain instead of IPs) router system responsible for IPs dependencies. - Don't use health checks for microservices with retry S: Use helthcheck with retry to give depentent microservice time for self recovering.
- Don't think about global logging and debugging process, have logging per microservice only. S: Use ELK stack, mark operation with unique ID to make possible to investigate full flow of the operation.
- Don't think about way how to run microservice independent on developer environment. S: Use mocks to run microservice independent, mock should be provided by team who created dependent microservice.
- Flying Blind or don't use graphs and statics about your system status, don't use notifications about errors.
- Don't use same environment for each your microservice, use different deployment configurations for microservices
S: Choose one environment and deploy strategy, use it for all microservices for example kubernetes with docker. - Don't have enough automation for CI/CD S: Automate everything as possible.
- Don't have single storage for all microservices configurations. S: Store all configs in one place, make it possible to change concreate microservice configuration from one place.
- Don't have good documentation
Types of configuration
- Connection strings
- Endpoint URLs
- Queue names
- Bindings
- Contracts
- Authentication
- Namespaces
- Handlers
- Modules
- Assembly bindings
- Should be related to topology configuration and make possible to change configuration of each element in it. Store all settings in one place
- Separate config file
- Shared database for configurations
- Create service which will collect information about microservice (what version of messages it use, what APIs, what database connection),
- Should be related only to internal application configurations*
- Web.config file
- Save all configurations in one place foe example database.
- Keep records of version of component, machine, configs what use deployed component.
- Remotely scriptable
- Separate topological from internal settings
- Separate config file
- Shared configuration database
- Databases scheme
- Services/API
- Messages

- Message is persisted
- Message is not removed until processed
- Duplicate messages are recognized
- Save subscriptions, avoid duplicated subscriptions
- all services of the application must have Health check functionality (this can be use to be sure that related microservices are alive and operation will be success, if one of the depended service is down then work of the current service invalid)
- Use Automation API schemas builders for example Swagger.
- One microservice one database or independent database scheme.
- Use versioning for APIs, Messages, libraries.
- Write integration, Unit Tests.
- Use health checks for dependent services.
The system should respond in a timely manner. Responsive systems focus on providing rapid and consistent response times, so they deliver a consistent quality of service.
In case the system faces any failure, it should stay responsive. Resilience is achieved by replication, containment, isolation, and delegation. Failures are contained within each component, isolating components from each other, so when failure has occurred in a component, it will not affect the other components or the system as a whole. (Circuit bracker, Bulkahead)
Reactive systems can react to changes and stay responsive under varying workload. They achieve elasticity in a cost effective way on commodity hardware and software platforms. (sharding, replication, workload distribution)
Message driven: In order to establish the resilient principle, reactive systems need to establish a boundary between components by relying on asynchronous message passing. (Accepted status is asynchronus by default, callback mechanism to avoid waiting)
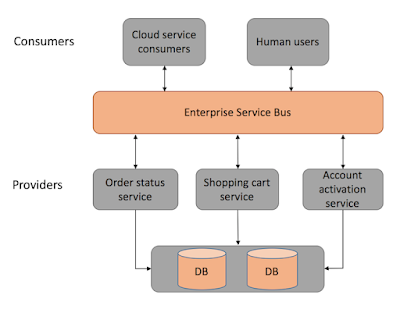
SOA typically tries to build business functionality using reusable components that communicate through a decoupled medium like a network or service bus.
 This service determines in an abstract way what is needed for that business to process the order. The enterprise service bus orchestrates the calls needed to the enterprise services. The enterprise services implement specific behavior defined by the business services. In this case, the service bus would call each enterprise service in the correct order to process the user’s order, and the enterprise services would do the actual work and manage the state. Enterprise services are designed to be reusable for any workflow; the application services, on the other hand, implement functionality that does not need to be reusable, like processing the order specific taxes that would be relevant just for the order workflow, for example. Infrastructure services implement cross-cutting functionality like logging or monitoring.
This service determines in an abstract way what is needed for that business to process the order. The enterprise service bus orchestrates the calls needed to the enterprise services. The enterprise services implement specific behavior defined by the business services. In this case, the service bus would call each enterprise service in the correct order to process the user’s order, and the enterprise services would do the actual work and manage the state. Enterprise services are designed to be reusable for any workflow; the application services, on the other hand, implement functionality that does not need to be reusable, like processing the order specific taxes that would be relevant just for the order workflow, for example. Infrastructure services implement cross-cutting functionality like logging or monitoring.
While SOA focuses on abstract, reusable functionality, microservice and event-driven architectures focus on organizing their components around domains.
Also, in SOA the service bus tends to become increasingly larger. Business logic tends to be added to the bus instead of the services. The bus also accounts for several responsibilities besides orchestration. The bus is usually the component that routes and knows to communicate with each service and often has logic to adapt and transform requests. The enterprise service bus tends to grow and become a monolith in its own right although the whole architecture is distributed, often having the worst of both worlds.
A Service Oriented Architecture is a software architecture pattern, which application components provide services to other components via a communications protocol over a network. The communication can involve either simple data passing or it could involve two or more services coordinating connecting services to each other. Services (such as RESTful Web services) carry out some small functions, such as validating an order, activating account, or providing shopping cart services.
There are 2 main roles in SOA, a service provider and a service consumer. A software agent may play both roles. The Consumer Layer is the point where consumers (human users, other services or third parties) interact with the SOA and Provider Layer consists of all the services defined within the SOA. The following figure shows a quick view of an SOA architecture.
Backup - cold recovery, has long downtime, has data loss Replication - data continuously copied to exist database, very fast recovery just switch traffic to new resource Write data to several database instances simulteniuosly, when one down redirect traffic to one instance
- Range base: when data splits to shards base on range for example year
- Hash base: when as a key used hash value to generate key and baesd on this key system design where to put data
- GEO base: split by location, for example contry, city
- Directory (lookup table): create a lookup table where define relation to what shard save the value
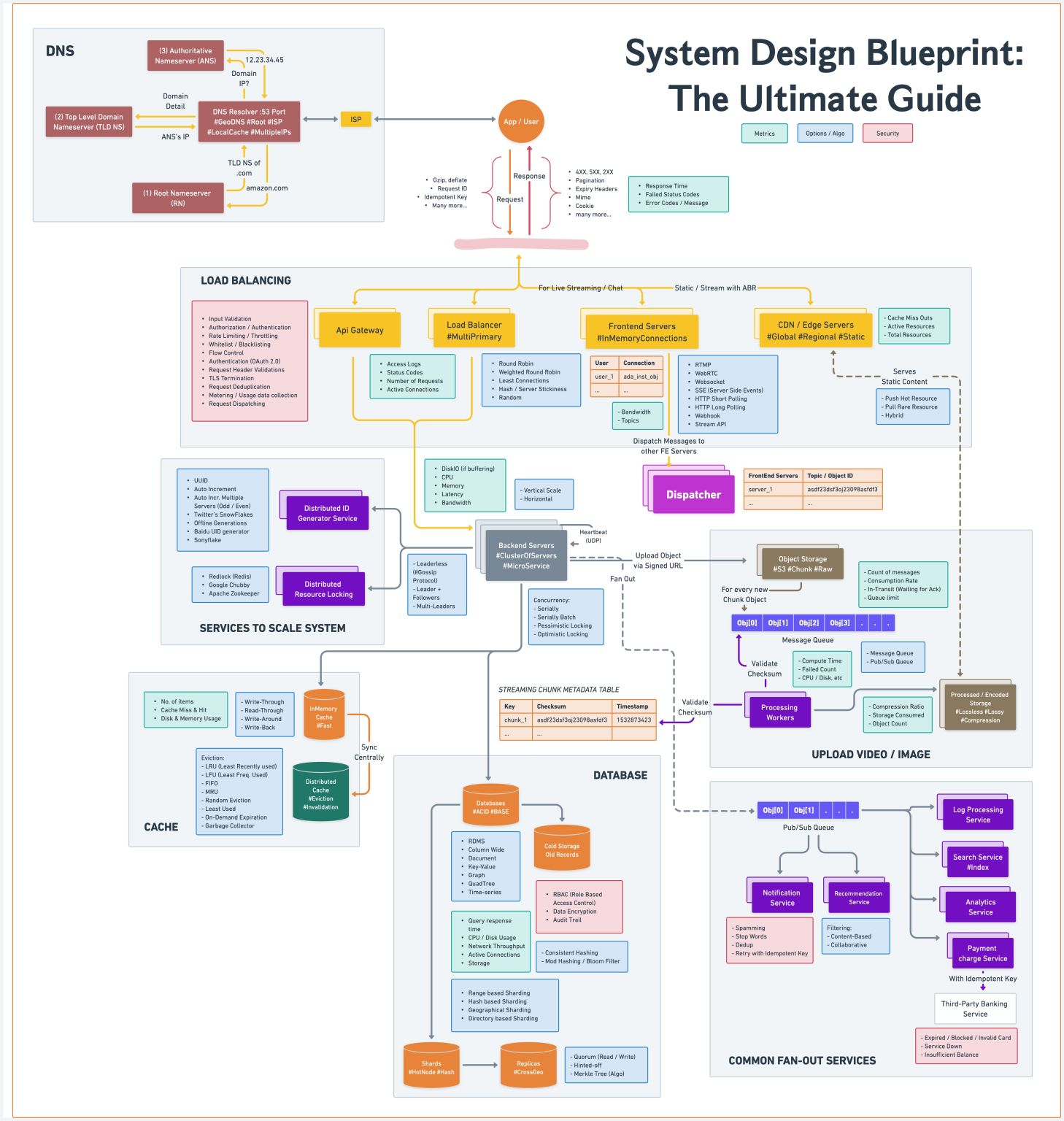
We've created a template to tackle various system design problems in interviews.
Hope this checklist is useful to guide your discussions during the interview process.
- Load Balancing
- API Gateway
- Communication Protocols
- Content Delivery Network (CDN)
- Database
- Cache
- Message Queue
- Unique ID Generation
- Scalability
- Availability
- Performance
- Security
- Fault Tolerance and Resilience