[BEAM-6027] Fix slow downloads when reading from GCS #8553
Conversation
…owse/BEAM-6027 Signed-off-by: fabito <fuechi@ciandt.com>
Signed-off-by: fabito <fuechi@ciandt.com>
 udim
left a comment
udim
left a comment
There was a problem hiding this comment.
Thank you for your contribution!
Very cool
|
cc: @chamikaramj |
Signed-off-by: fabito <fuechi@ciandt.com>
Signed-off-by: fabito <fuechi@ciandt.com>
Signed-off-by: fabito <fuechi@ciandt.com>
Signed-off-by: fabito <fuechi@ciandt.com>
|
Hi @udim , Using this snippet: import tempfile
import timeit
from apache_beam.io.filesystems import FileSystems
from apache_beam.io.gcp import gcsio
from apache_beam.io.filesystemio import DownloaderStream
# https://issues.apache.org/jira/browse/BEAM-6027
def downloader_stream_readall(self):
res = []
while True:
data = self.read(gcsio.DEFAULT_READ_BUFFER_SIZE)
if not data:
break
res.append(data)
return b''.join(res)
original_read_all = DownloaderStream.readall
if __name__ == '__main__':
test_file = 'gs://cloud-samples-tests/vision/saigon.mp4'
num_executions = 1
def test_original():
DownloaderStream.readall = original_read_all
with FileSystems.open(test_file) as audio_file:
with tempfile.NamedTemporaryFile(mode='w+b') as temp:
temp.write(audio_file.read())
def test_refactored():
DownloaderStream.readall = downloader_stream_readall
with FileSystems.open(test_file) as audio_file:
with tempfile.NamedTemporaryFile(mode='w+b') as temp:
temp.write(audio_file.read())
print(timeit.timeit("test_original()", setup="from __main__ import test_original", number=num_executions))
print(timeit.timeit("test_refactored()", setup="from __main__ import test_refactored", number=num_executions))I got the following output: Hope that helps |
|
Thanks for the update. This looks great. Seems like the file you used for your microbenchmark is about 4MB which will be within the first chunk for the new buffer size. Can you try running a Beam pipeline with a larger input (say 10GB) with Dataflow to confirm that there's no regression at large scale ? |
|
Yes I can. Any advice on how this pipeline would be and how can we measure the reading performance? with beam.Pipeline(options=pipeline_options) as pipeline:
_ = (
pipeline
| 'Read 10Gb file' >> beam.io.ReadAllFromText('gs://bucket/10Gb.txt')
| 'Write file' >> beam.io.WriteToText('gs://bucket/10Gb_copy*.txt')
) |
|
Yeah, that pipeline looks good. End-to-end execution time and Total vCPU time show in Dataflow console should be good metrics to compare. |
|
I ran the same pipeline, first with the original code and after with the new implementation of Before the change:
After the change:
|
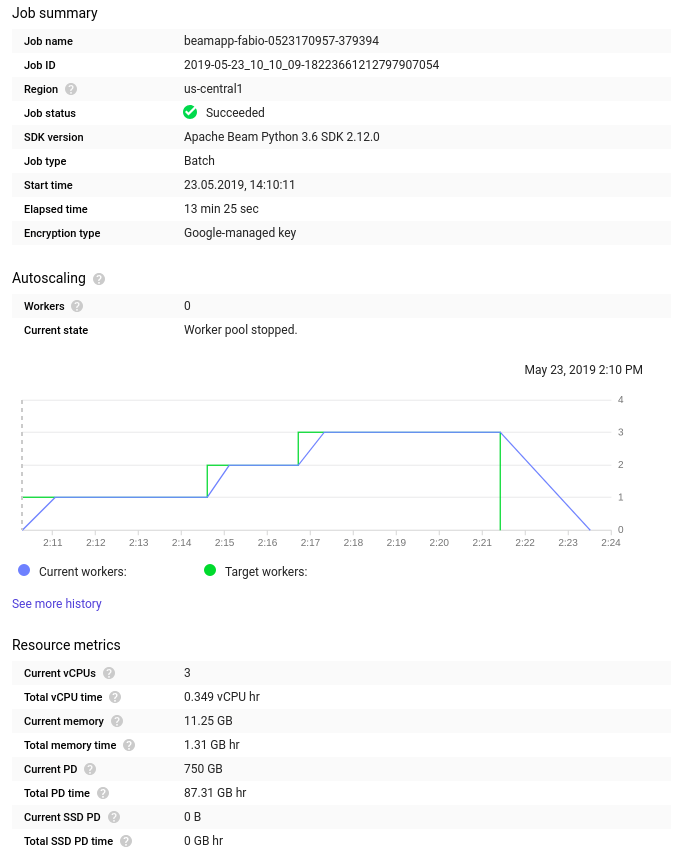
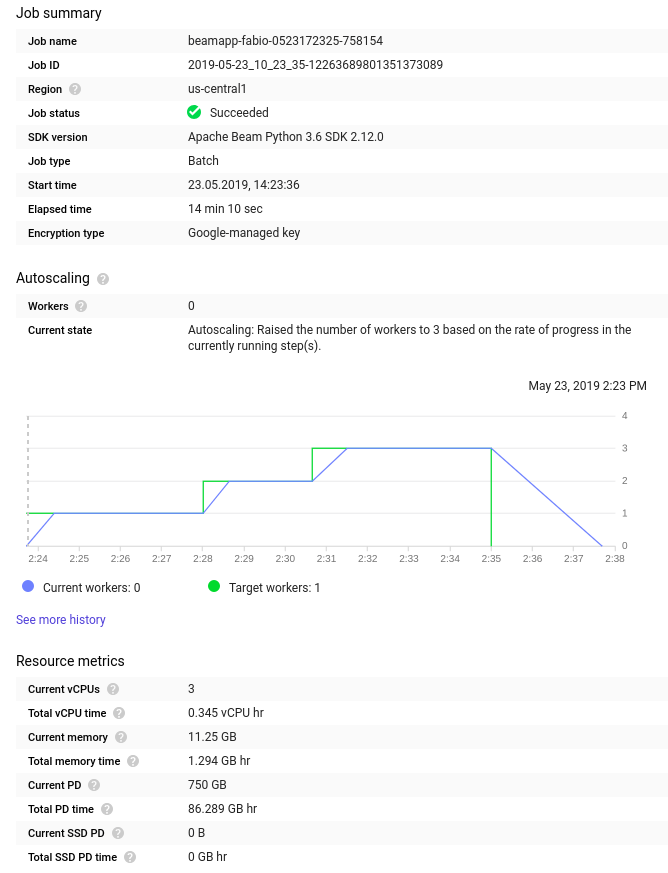
 chamikaramj
left a comment
chamikaramj
left a comment
There was a problem hiding this comment.
Thanks. LGTM.
Thanks for fixing this.
Added one comment. Also please fixup your commits into a single commit for merging.
| def readall(self): | ||
| """Read until EOF, using multiple read() call.""" | ||
| res = [] | ||
| while True: |
There was a problem hiding this comment.
Where is this function used ?
Prob. remove if unused.
There was a problem hiding this comment.
Ah actually seems like you are overriding the function here: https://docs.python.org/3/library/io.html#io.IOBase
There was a problem hiding this comment.
Sorry, still have a question.
Does Beam call readlll() function anywhere ? I couldn't find a usage. Beam textio for example, invokes read() not readall().
https://github.com/apache/beam/blob/master/sdks/python/apache_beam/io/textio.py#L272
If it does, I'm not sure what will prevent us from reading a huge amount of data into memory and running into OOMs.
There was a problem hiding this comment.
I only found this usage in ReadableFile (relatively new) where we don't specify the size:
beam/sdks/python/apache_beam/io/fileio.py
Lines 150 to 154 in 1382505
There was a problem hiding this comment.
That makes sense. I think ReadableFile is intended for small files. But probably we should add a readall() method there as well and update read() to take a buffer (not in this PR).
cc: @pabloem
|
Thanks. I'll squash and merge. |
|
Adding note to not forget to "run python postcommit" before merging |
Overrides
io.RawIOBase.readallinfilesystemio.DownloaderStreamas proposed in BEAM-6027.It improves download time in ~40x.