大量请求被堵住,进到服务时已经超时 #887
Description
对我们的服务进行压测发现一个现象:
qps 达到 2000 多的时候,cpu 利用率只有 50%,不会再升高了。此时从客户端看,有大量超时,超时时间是 70ms。
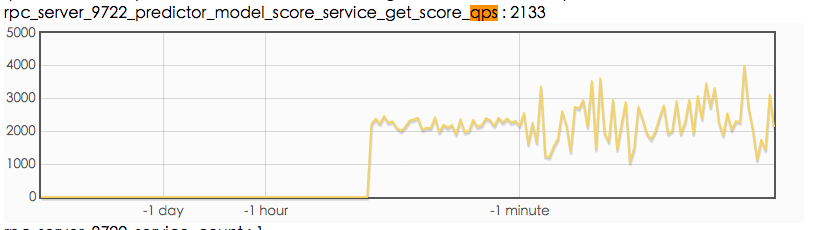
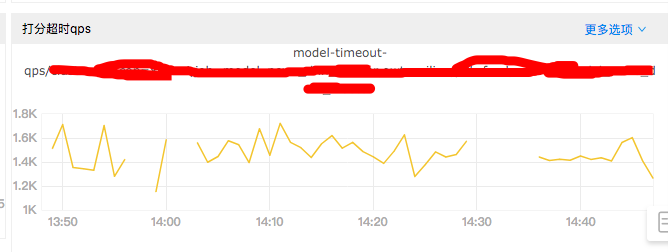
从上图可以看到,有超过一半的请求都超时了。
首先排查系统资源问题,感觉并不存在 io-bound 问题:

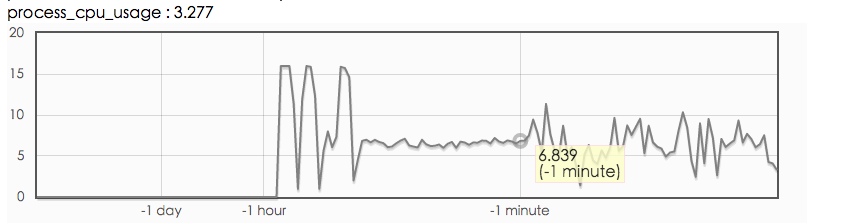
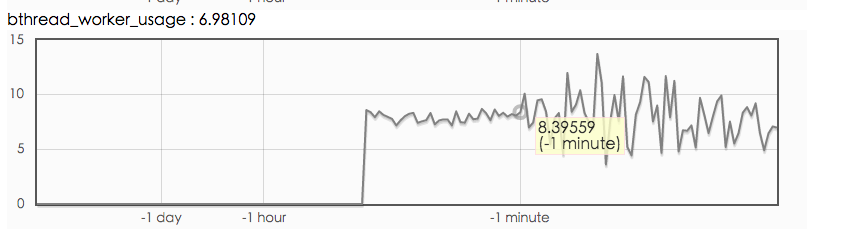
然后查看 rpcz:

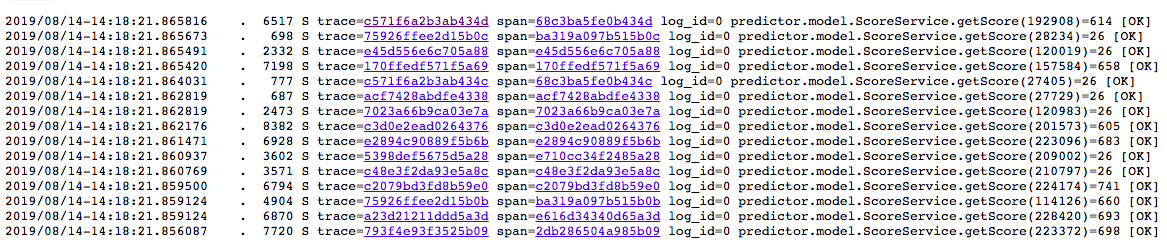
从上图可以看出,服务端的实际处理时间很短,感觉请求都堵在了网络上,所以怀疑网络带宽不足,接下来测试网络带宽。
网络带宽测试
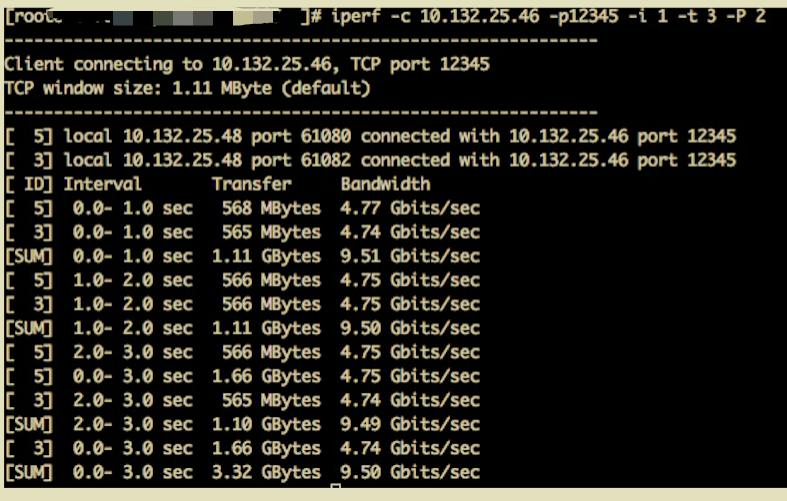
可以看到万兆网卡的带宽也没有问题。
contention profiling

又做了一下 contention profiling ,也没感觉有啥问题。
思路到这里卡住了,现在看到的现象是:从客户端发起请求,到 brpc Received request 这段时间比较长,各位神牛帮忙看看?
=================================================
2019.08.16 补充:
根据大佬的意见检查了一下客户端,下面补充一些客户端的数据,以及服务端 latency:
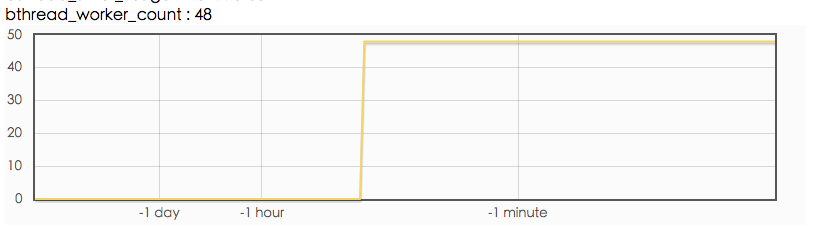
客户端 bthread_worker_count, bthread_worker_usage, process_cpu_usage

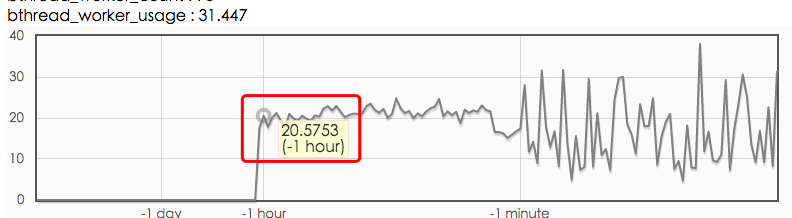
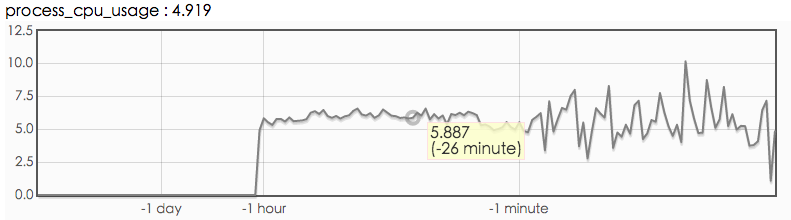
从上图看,client端 bthread 线程数是够用的, 但是 process_cpu_usage 比 bthread_worker_usage 低很多的原因应该是:调用下游服务阻塞导致的。
client 端调用函数 latency
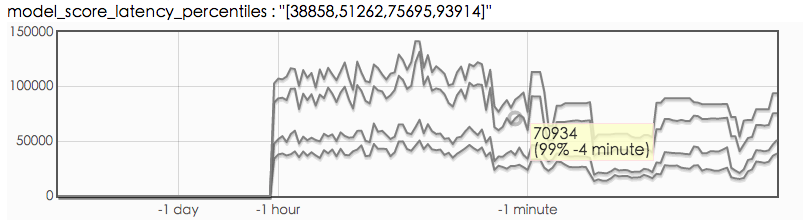
参考如下代码对 rpc 调用函数做了监控,得到的 client 端 latency 图如上所示。
#include <butil/time.h>
#include <bvar/bvar.h>
bvar::LatencyRecorder g_foobar_latency("foobar");
...
void search() {
...
butil::Timer tm;
tm.start();
foobar();
tm.stop();
g_foobar_latency << tm.u_elapsed();
...
}
服务端处理 latency
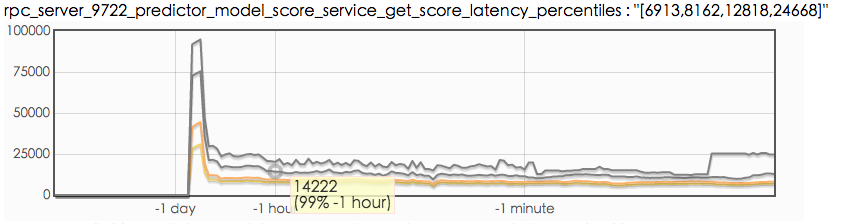
客户端资源是够用的,contention profiling 也没发现问题, 但是客户端统计的 latency (p99 70ms)和服务端的 latency(p99 15ms) 差距巨大, 看起来就像是堵在了网络上, 有什么办法分析一下网络传输过程中的耗时吗?