add output field name rfc #422
Conversation
 alamb
left a comment
alamb
left a comment
There was a problem hiding this comment.
Thanks @houqp looks great to me
For anyone else following along here is a google doc link to drafts of this content.
https://docs.google.com/document/d/1uviWavwEGD3qxwMk2AGkOgp6ENrvKGiMWQhHNbqPwhg/edit
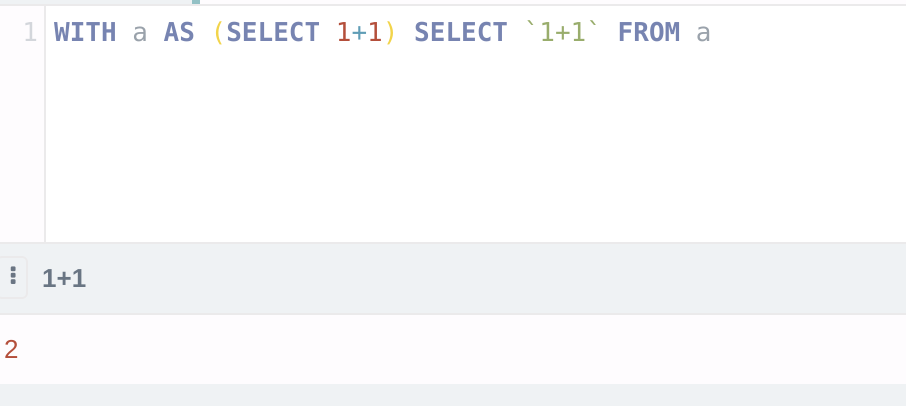
| * Literal string MUST not be wrapped with quotes or double quotes. | ||
| * `SELECT 'foo'` SHOULD result in field name: `foo` | ||
| * Operator expressions MUST be wrapped with parentheses. | ||
| * `SELECT -2` SHOULD result in field name: `(- 2)` |
There was a problem hiding this comment.
Should there really be a space between - and 2?
| * `SELECT -2` SHOULD result in field name: `(- 2)` | |
| * `SELECT -2` SHOULD result in field name: `(-2)` |
There was a problem hiding this comment.
This came from the rule below: Operator and operand MUST be separated by spaces.. I don't have a strong opinion on this. Picked this because this is what spark does today. We can also change the rule below to require no spaces between operator and operands. Which one do you prefer?
|
So, a question that I would like to bring before committing to RFCs. I see two ways of approaching this:
Both have benefits and downsides. My opinion is that we should not use the RFC approach, and instead work under the "specification" model. The reason is that, in my opinion, RFCs are hard to follow because they were made in a specific moment in time and no longer updated. If updated, there is a new RFC that does that, which requires some form of consolidation (e.g. RFCs have the term "amends", "superseded by", "revoked", PEP also). My opinion is that, with PRs, git history and git blame, there is no need to store the "deltas" (RFCs) in the repository itself, and we should instead offer the consolidated, up-to-date picture of the specification. This was the rational of the original issue, at least. TL;DR: an RFC is a "delta", the specification is the "state". An RFC/PR brings the state from the previous state to a new state. IMO we should have the specification on the repo and use PRs to track deltas (as opposed to having the deltas themselves in the repo) |
| * All field names MUST not contain relation qualifier. | ||
| * Both `SELECT t1.id` and `SELECT id` SHOULD result in field name: `id` | ||
| * Function names MUST be converted to lowercase. | ||
| * `SELECT AVG(c1)` SHOULD result in field name: `avg(c1)` |
There was a problem hiding this comment.
One concern I had when implementing something very similar to this RFC here https://github.com/apache/arrow-datafusion/pull/280 is that introducing an alias makes the column available under that name in the whole query. IMO that can be confusing if you do use this implicit convention. Any idea what other engines / databases are doing here?
There was a problem hiding this comment.
(So it looks like this is a common practice). Confusing - yes - but maybe not a hige concern, as users might not often rely on this as it is quite unconventional.
There was a problem hiding this comment.
@Dandandan I documented a survey of behavior from mysql/sqlite/postgres/spark in this doc as well, for example: https://github.com/houqp/arrow-datafusion/blob/qp_rfc/docs/rfcs/output-field-name-semantic.md#function-with-operators. Basically mysql and sqlite use the raw user query as the column name, postgres throws in the towel and just use ?column? for everything while spark SQL constructs the column name based on the expression.
I picked Spark's behavior because it's the one that is the closest to what we had at the time. But since you already implemented mysql and sqlite's behavior since then, i am happy to update the doc to account for that. In this case, we need two sets of rules, one for SQL queries, which is to just reuse what's provided in the query. The other one for dataframe queries, which is what I outlined in this doc.
UPDATE: after taking a second look at #280, turns out the PR is closed due to the issue you mentioned above. I am now leaning back towards not preserving user provided names from query to keep things simple. It's one less thing to worry about and keeps the rules simple so we can apply the same set of rules for outputs produced from both SQL queries and dataframe queries. Let me know if you have a strong opinion on this though.
| in many cases, which makes output less readable than other designs. | ||
|
|
||
| MySQL and SQLite preserve user query input as the field name. This adds extra | ||
| implementation and runtime overhead with little gain for end uers. |
There was a problem hiding this comment.
What is the extra implementation / runtime overhead? I would say just printing the original (representation) of expressions should be less work than getting rid of qualified names? Preserving casing is currently not something done by the parser - but qualified names are maintained.
There was a problem hiding this comment.
When I wrote this, I was mostly thinking about attaching the extra alias expression node and having to traverse this node multiple times during plan optimization. But honestly, I don't think this overhead matters in practice. It's just one more thing we need to do compared to not preserving the raw query input.
Getting rid of the qualifier during physical planning is just one line change in the function that returns physical field name for a logical column.
 jorgecarleitao
left a comment
jorgecarleitao
left a comment
There was a problem hiding this comment.
The field semantic makes sense to me, and formalizes something that we already do today.
I would just try to write it in a way that does not feel like a proposal, but rather as something that "is", i.e. that users can expect when using DataFusion.
|
@jorgecarleitao I agree with you, I also don't want this thing to get too formal and create unnecessary frictions whenever we need to update it. My original intent was a hybrid model of RFCs and Specs. Where we allow minor and backwards compatible changes to RFC directly (tracked through git), but require new RFCs for bigger changes. I will convert it to specs so people can walk in with the right expectation. We can come back to the RFC models in the future if we want to get serious about proposing changes. |
|
Thanks @houqp ! I am 100% with you here. Wrt to the content itself, I am a big +1 here. We could discuss the finer print but my approval reads as: this is a fantastic first start; we may need some more iterations here; I would like to avoid committing to the exact wording at this point and instead allow further iterations on the existing text (i.e. without requiring another proposal / RFC, long text, and/or a way to consolidate texts. |
|
Looks like we just need a RAT (apache copyright statement) to get a clean CI run and merge it. Perhaps we can add some section to the developer's guide once implemented with the "here is how output names are created" with a link to this RFC for the rationale |
1 similar comment
|
Looks like we just need a RAT (apache copyright statement) to get a clean CI run and merge it. Perhaps we can add some section to the developer's guide once implemented with the "here is how output names are created" with a link to this RFC for the rationale |
|
@alamb @jorgecarleitao @Dandandan I reorganized everything to better align with the specification model. Could you take another look to see if there is anything you would like me to change? |
jorgecarleitao
left a comment
There was a problem hiding this comment.
Beautiful. Thank you so much for your patience and work here. 💯
|
|
||
| Here is the list current active specifications: | ||
|
|
||
| * [Output field name semantic](docs/specification/output-field-name-semantic.md) |
Codecov Report
@@ Coverage Diff @@
## master #422 +/- ##
=======================================
Coverage 75.27% 75.27%
=======================================
Files 147 147
Lines 24834 24834
=======================================
Hits 18694 18694
Misses 6140 6140 Continue to review full report at Codecov.
|
|
windows test failure is unrelated |
* docs: add guide to adding a new expression * docs: revise with presentation info * docs: fix warning * docs: fix header level * docs: better info about handling datafusion udfs * docs: grammar/typos/etc * docs: clarify datafusion/datafusion comet path * docs: clarify language about `isSpark32` * docs: fix error
Which issue does this PR close?
Keeping the process light since the project is still in a rapid development phase.
Closes #302.
Relates to #55.
Once this is reviewed and accepted, I will send the update invariant doc in a follow up PR.
Rationale for this change
Unblock PR #55.
What changes are included in this PR?
First RFC for field name semantic and RFC process.