Add InputStats to track bytes processed by a task#13520
Add InputStats to track bytes processed by a task#13520kfaraz merged 17 commits intoapache:masterfrom
Conversation
| default void incrementProcessedBytes(long incrementByValue) | ||
| { | ||
|
|
||
| } | ||
|
|
||
| default long getProcessedBytes() | ||
| { | ||
| return 0; | ||
| } |
There was a problem hiding this comment.
why are default methods needed here?
There was a problem hiding this comment.
RowIngestionMeters is marked as an extension point, which is where this is used. I can move the default impls there.
There was a problem hiding this comment.
I am not sure if anyone uses their own impl of RowIngestionMeters. I would have preferred not having these default impls altogether.
There was a problem hiding this comment.
Moved to RowIngestionMeters for now.
| public interface InputSourceReader | ||
| { | ||
| CloseableIterator<InputRow> read() throws IOException; | ||
| default CloseableIterator<InputRow> read() throws IOException |
There was a problem hiding this comment.
This method can now be removed as it is now only used in tests.
|
|
||
| @Override | ||
| public CloseableIterator<InputRow> read() throws IOException | ||
| public CloseableIterator<InputRow> read(InputStats inputStats) throws IOException |
There was a problem hiding this comment.
Maybe throw UnsupportedOpException here?
 AmatyaAvadhanula
left a comment
AmatyaAvadhanula
left a comment
There was a problem hiding this comment.
Thank you @kfaraz! LGTM, +1 after builds pass
|
Thanks a lot for the review, @AmatyaAvadhanula ! |
Follow up to #13520 Bytes processed are currently tracked for intermediate stages in MSQ ingestion. This patch adds the capability to track the bytes processed by an MSQ controller task while reading from an external input source or a segment source. Changes: - Track `processedBytes` for every `InputSource` read in `ExternalInputSliceReader` - Update `ChannelCounters` with the above obtained `processedBytes` when incrementing the input file count. - Update task report structure in docs The total input processed bytes can be obtained by summing the `processedBytes` as follows: totalBytes = 0 for every root stage (i.e. a stage which does not have another stage as an input): for every worker in that stage: for every input channel: (i.e. channels with prefix "input", e.g. "input0", "input1", etc.) totalBytes += processedBytes
This is based on #12750 and #10407
Description
FirehoseToInputSourceReaderAdaptorprocessedBytesmeasure the uncompressed input bytes. e.g. in case of the sample "wikipedia" datasource, it measures the total size of the unzippedwikipedia.jsonfile (and not thewikipedia.json.gz)unparseable,thrownAwayorprocessedWithErrorsalso count towardsprocessedBytesImplementation
InputStatsto track processed bytesInputSourceReader.read(InputStats)to read input rows while counting bytes.InputSourceReader.read(inputStats)inAbstractBatchIndexTaskprocessedBytesinStreamChunkParser. This does not use the newInputSourceReader.read(inputStats)method.InputStatswithRowIngestionMetersso that bytes can be exposed in task reportsTests and refactors
processedBytesHdfsInputSourceTestS3InputSourceTestGCSInputSourceTestOssInputSourceTestSqlInputSourceTestDruidSegmentReaderTestKinesisIndexTaskTestKafkaIndexTaskTestMutableRowIngestionMeterstoSimpleRowIngestionMetersand remove duplicate classCacheTestSegmentCacheManagerwithNoopSegmentCacheManagerKafkaIndexTaskTestandKinesisIndexTaskTestPending items
Further work
Release note
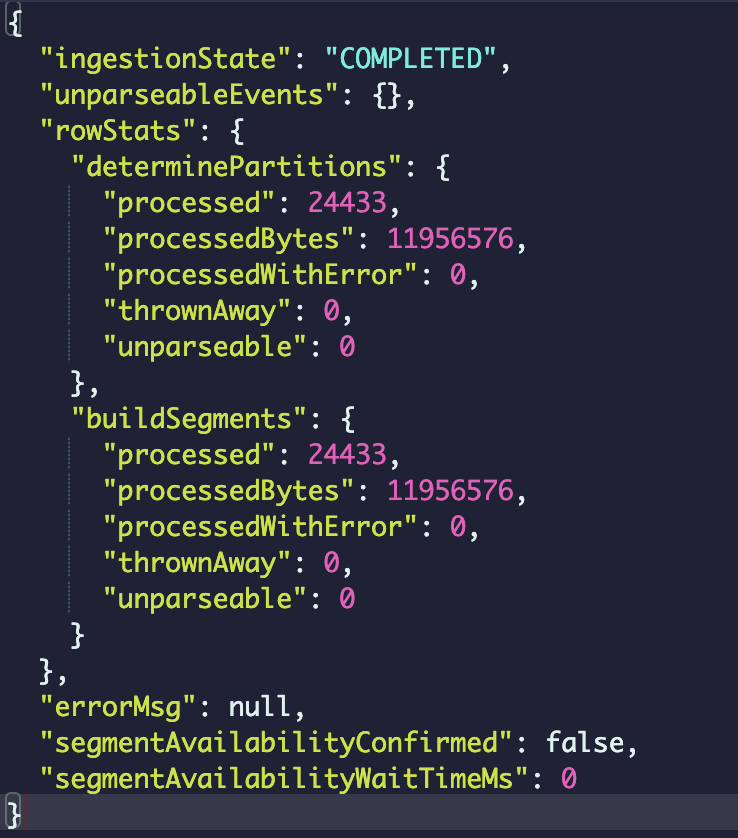
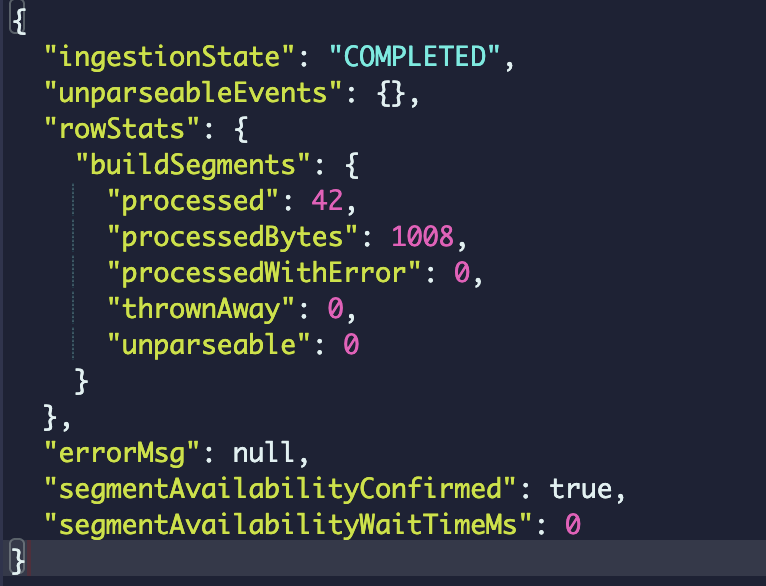
Track bytes processed by a task and publish them in the task report along with the row stats.
Sample row stats in a task report:
Screenshots
Batch ingestion
Streaming ingestion
This PR has: