Mitigate controller leadership switch latency - improve leader -> standby#662
Mitigate controller leadership switch latency - improve leader -> standby#662i3wangyi wants to merge 3 commits intoapache:masterfrom
Conversation
|
Current Leader -> Standby diagram: |
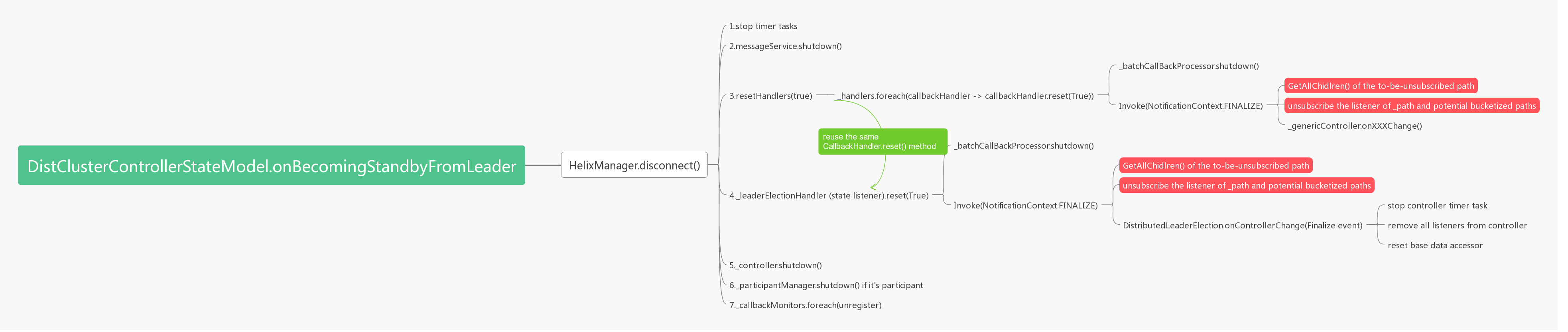
|
After applying the changes |

|
Logically, it sounds good to me. But I think this is not the majority contribution in LeaderSwitch when controller is trying acquiring leadership, right? How much it reduces the overhead? |
No, the optimization is only for leader -> standby, one data point shows a 10X latency improvement (from 1700ms -> 170ms); For optimizing the other part of the story: standby -> leader, there're different options, I will explore them later in different PRs. |
helix-core/src/main/java/org/apache/helix/manager/zk/CallbackHandler.java
Outdated
Show resolved
Hide resolved
helix-core/src/main/java/org/apache/helix/manager/zk/ZKHelixManager.java
Show resolved
Hide resolved
helix-core/src/main/java/org/apache/helix/manager/zk/CallbackHandler.java
Show resolved
Hide resolved
helix-core/src/main/java/org/apache/helix/manager/zk/CallbackHandler.java
Show resolved
Hide resolved
| if (_eventTypes.contains(EventType.NodeDataChanged) | ||
| || _eventTypes.contains(EventType.NodeCreated) | ||
| || _eventTypes.contains(EventType.NodeDeleted)) { | ||
| logger.info("Subscribing data change listener to path: " + path); |
There was a problem hiding this comment.
Why removing these logs? While debugging, how do we know if this listener is configured with what kind of _eventTypes list? Since there are still some concerns or bug reports regarding callbacks, we'd better keep the detail logs.
There was a problem hiding this comment.
These logs are actually redundant. The private subscribeForChanges() will eventually call other private methods
private void subscribeChildChange(String path, NotificationContext.Type callbackType) {
if (callbackType == NotificationContext.Type.INIT
|| callbackType == NotificationContext.Type.CALLBACK) {
if (logger.isDebugEnabled()) {
logger.debug(_manager.getInstanceName() + " subscribes child-change. path: " + path
+ ", listener: " + _listener);
}
_zkClient.subscribeChildChanges(path, this);
} else if (callbackType == NotificationContext.Type.FINALIZE) {
logger.info(_manager.getInstanceName() + " unsubscribe child-change. path: " + path
+ ", listener: " + _listener);
_zkClient.unsubscribeChildChanges(path, this);
}
}
private void subscribeDataChange(String path, NotificationContext.Type callbackType) {
if (callbackType == NotificationContext.Type.INIT
|| callbackType == NotificationContext.Type.CALLBACK) {
if (logger.isDebugEnabled()) {
logger.debug(_manager.getInstanceName() + " subscribe data-change. path: " + path
+ ", listener: " + _listener);
}
_zkClient.subscribeDataChanges(path, this);
} else if (callbackType == NotificationContext.Type.FINALIZE) {
logger.info(_manager.getInstanceName() + " unsubscribe data-change. path: " + path
+ ", listener: " + _listener);
_zkClient.unsubscribeDataChanges(path, this);
}
}
To perform the actual listener subscription. I think keeping the verbose log in the last step is sufficient enough and you know helix.log is flooded with all listeners logs
| // TODO reset user defined handlers only | ||
| // TODO Fix the issue that when connection disconnected, reset handlers will be blocked. -- JJ | ||
| // This is because reset logic contains ZK operations. | ||
| resetHandlers(true); |
There was a problem hiding this comment.
So we are not sending FINALIZE events on the reset anymore? I think this is problematic.
There was a problem hiding this comment.
Yeah. That's the design of using unsubscribeAll. Because the current callback handler's FINALIZE method is pretty expensive (involving read all children node under currentstates then remove them one by one).
I could perform tests that prove without the FINALIZE event, HelixManager could clean up all information when disconnect(). And the single callback handler could still use the FINALIZE event to un-register itself.
There was a problem hiding this comment.
The thing is that our customers also depend on the FINALIZE event to do the cleanup. I believe with this change disconnect will clean up all the listeners. But you break the agreement.
There was a problem hiding this comment.
@jiajunwang I understand your concern. With the current helix structure & library dependency, many times there's really no easy way to satisfy everything while still keeping the code clean & short IMO, even we overall agree with the overall design here. Let's take it offline.
I will try to resolve rest concerns as much as I could and propose a new draft code structure
There was a problem hiding this comment.
Sure, feel free to call for a short meeting with more people. My point is that we shall never trade-off correctness or functionality for performance.
- boost performance on leader -> standby latency (disconnect() method performs much faster) - one sample result shows leader -> standby latency reduces from 1432ms to 176ms
TODO: add tests when session expiry
| logger.info("Subscribing changes listener to path: " + path + ", type: " + callbackType | ||
| + ", listener: " + _listener); | ||
| logger.info( | ||
| "START:INVOKE subscribing changes listener on path: {}, callbackType: {}, listener: {}, isWatchChild: {}", |
There was a problem hiding this comment.
START:INVOKE/END:INVOKE are for the callbacks. Please don't use it here. It will be confusing to whoever debug later.
| * *Caution*: currently it's only used during disconnecting from ZK and the | ||
| * listeners unsubscription will be taken care by zkClient directly | ||
| */ | ||
| void closeBatchCallbackProcessor() { |
There was a problem hiding this comment.
Besides my concern of not sending FINALIZE, this method is a subset of void reset(boolean isShutdown); I think you can avoid duplicate code.
Of course, please address my concern about not having the FINALIZE first. Then we can revisit this one.
Issues
#661
Description
Here are some details about my PR, including screenshots of any UI changes:
The code change will skip the getChildren() request on listener's removal, and the zkClient's unsubscribeAll will be used instead of unsubscribing a single path;
It also includes some log optimization works.
Tests
(List the names of added unit/integration tests)
testControllerConnectThenSessionExpireinTestControllerLeaderhshipChange(Copy & paste the result of "mvn test")
[ERROR] Tests run: 890, Failures: 3, Errors: 0, Skipped: 0, Time elapsed: 3,909.929 s <<< FAILURE! - in TestSuite
[ERROR] testDeleteStoppingStuckWorkflowForcefully(org.apache.helix.integration.task.TestForceDeleteWorkflow) Time elapsed: 60.645 s <<< FAILURE!
java.lang.AssertionError: expected: but was:
at org.apache.helix.integration.task.TestForceDeleteWorkflow.testDeleteStoppingStuckWorkflowForcefully(TestForceDeleteWorkflow.java:279)
[ERROR] testForceDeleteJobFromJobQueue(org.apache.helix.integration.task.TestDeleteJobFromJobQueue) Time elapsed: 0.498 s <<< FAILURE!
org.apache.helix.HelixException: Failed to delete job: testForceDeleteJobFromJobQueue_job2 from queue: testForceDeleteJobFromJobQueue
at org.apache.helix.integration.task.TestDeleteJobFromJobQueue.testForceDeleteJobFromJobQueue(TestDeleteJobFromJobQueue.java:75)
[ERROR] testStateTransitionTimeoutByClusterLevel(org.apache.helix.integration.paticipant.TestStateTransitionTimeoutWithResource) Time elapsed: 38.119 s <<< FAILURE!
java.lang.AssertionError: expected: but was:
at org.apache.helix.integration.paticipant.TestStateTransitionTimeoutWithResource.testStateTransitionTimeoutByClusterLevel(TestStateTransitionTimeoutWithResource.java:196)
[INFO]
[INFO] Results:
[INFO]
[ERROR] Failures:
[ERROR] TestStateTransitionTimeoutWithResource.testStateTransitionTimeoutByClusterLevel:196 expected: but was:
[ERROR] TestDeleteJobFromJobQueue.testForceDeleteJobFromJobQueue:75 » Helix Failed to ...
[ERROR] TestForceDeleteWorkflow.testDeleteStoppingStuckWorkflowForcefully:279 expected: but was:
[INFO]
[ERROR] Tests run: 890, Failures: 3, Errors: 0, Skipped: 0
Failed tests get passed running individually in IDE
Commits
Documentation
(Link the GitHub wiki you added)
Code Quality