[SUPPORT] Bulk insert slow on MOR #1786
Description
Hi,
I am trying to run a simple insert test with ~9.7GB of data. It’s a bulk insert. I used the NYC taxi data set and enhanced it with a monotonically increasing primary key(trip_id) and drop_date column. Total 4 years of data.
Given I am partitioning on drop_date, the number of target Hudi dataset partitions are ~1500. Source data is not partitioned and is arranged in 70 files of ~150MB parquet.
I am not able to get good first time insert performance. I tested this with below config and it still took 26 minutes to do the first write. With below config, I was expecting much lesser time to do first time ingest. I tried it with HDFS write also, but it hardly reduced 1-2 minutes. So potentially s3 is not the bottleneck I think.
EMR 5.30.1
Hudi 0.5.3
Spark 2.4.5
1 master node (4 core. 16GB)
Core 2x (16 core/64GB)
Task 1x (32core/64GB)
MOR data set
S3 target.
Executor count – 15
Executor size – 2 core/ 8GB
spark-shell --conf spark.serializer=org.apache.spark.serializer.KryoSerializer --conf spark.kryoserializer.buffer.max=512m --conf spark.rdd.compress=true -- conf spark.sql.hive.convertMetastoreParquet=false --packages org.apache.hudi:hudi-spark-bundle_2.11:0.5.3,org.apache.spark:spark-avro_2.11:2.4.5 --jars s3://xxxxx/hudi-spark-bundle_2.11-0.5.3.jar,/usr/lib/spark/external/lib/spark-avro.jar --executor-cores 2 --executor-memory 8g --driver-memory 8g --driver-cores 2
Command:
val inputDataPath = "s3://xxx/xxxx/*.parquet"
val hudiTableName = "table_nm"
val hudiTablePath = "s3://xxx/hudi/" + hudiTableName
val hudiOptions = Map[String, String](
DataSourceWriteOptions.RECORDKEY_FIELD_OPT_KEY -> "trip_id",
HoodieWriteConfig.TABLE_NAME -> hudiTableName,
DataSourceWriteOptions.OPERATION_OPT_KEY -> DataSourceWriteOptions.BULK_INSERT_OPERATION_OPT_VAL,
DataSourceWriteOptions.PARTITIONPATH_FIELD_OPT_KEY -> "drop_date",
DataSourceWriteOptions.PRECOMBINE_FIELD_OPT_KEY -> "tpep_dropoff_datetime",
DataSourceWriteOptions.TABLE_TYPE_OPT_KEY -> "MERGE_ON_READ",
HoodieStorageConfig.PARQUET_COMPRESSION_CODEC -> "snappy",
"hoodie.consistency.check.enabled" -> "true",
"hoodie.compaction.lazy.block.read" -> "false"
)
val inputDF = spark.read.format("parquet").load(inputDataPath)
inputDF.write.format("org.apache.hudi").options(hudiOptions).mode(SaveMode.Overwrite).save(hudiTablePath)
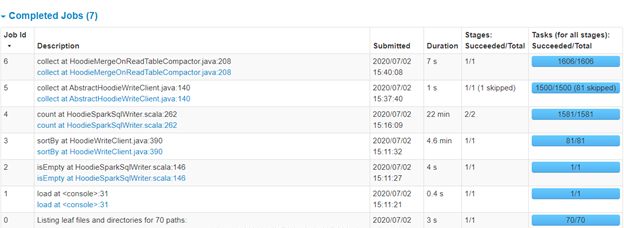
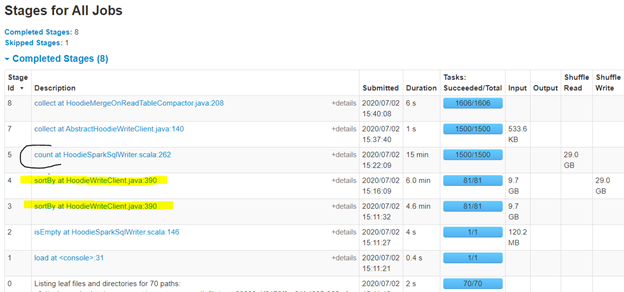
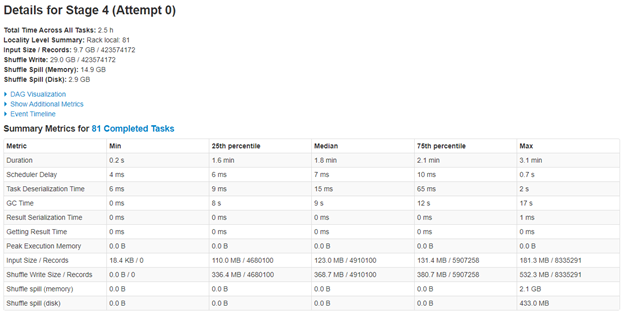
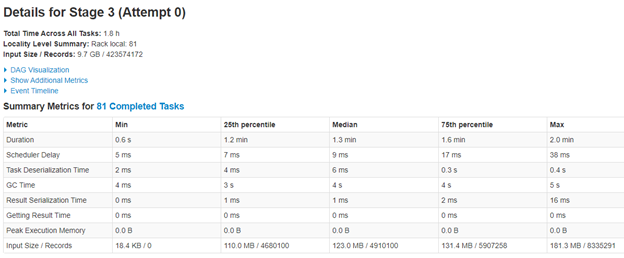
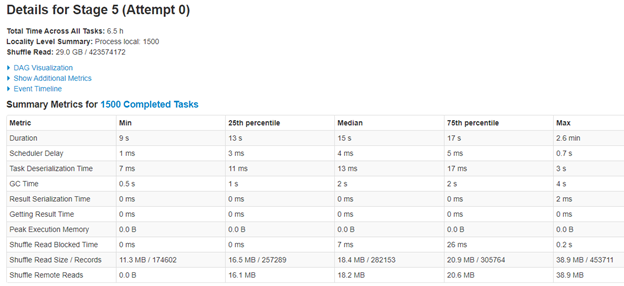
I have tried with shuffle parallelism of default, 500 and also 64. 64 becomes too slow. Since my data per partition is very less in target Hudi dataset (9.7 GB distributed in 1500 partitions), I even tried making the max file size limit to 20 MB, hoping it might reduce some shuffling, but did not make any difference to overall time.
GC time seem to be ok. I have tried with 2048 set for executor and driver overhead, but does not make any difference.
I am falling a bit short on ideas. Would be really helpful if you can provide some inputs. I just think it is shuffling a lot, but not sure how to control it. I was earlier using smaller instances, but switched to bigger and lesser instances hoping to reduce network chatter.
Thanks!