[SUPPORT] Upsert operation duplicating records in a partition #1910
Description
Describe the problem you faced
Upsert operation duplicates records in a partition.
We use EMR 6.0.0 (Hudi 0.5.0)
To Reproduce
Steps to reproduce the behavior:
- Create a pyspark dataframe. Let's say it looks like the following (We try this on pyspark shell on EMR cluster)
[
Row(id=1, issue_type='SUBSCRIPTION', partition_test='2020/08/01', updated_at=datetime(2020, 1, 1)),
Row(id=2, issue_type='SUBSCRIPTION', partition_test='2020/08/01', updated_at=datetime(2020, 1, 2)),
Row(id=3, issue_type='SUBSCRIPTION', partition_test='2020/08/01', updated_at=datetime(2020, 1, 3)),
Row(id=4, issue_type='SUBSCRIPTION', partition_test='2020/08/01', updated_at=datetime(2020, 1, 4)),
Row(id=5, issue_type='SUBSCRIPTION', partition_test='2020/08/01', updated_at=datetime(2020, 1, 5)),
Row(id=6, issue_type='SUBSCRIPTION', partition_test='2020/08/01', updated_at=datetime(2020, 1, 6)),
Row(id=7, issue_type='SUBSCRIPTION', partition_test='2020/08/01', updated_at=datetime(2020, 1, 7)),
Row(id=8, issue_type='SUBSCRIPTION', partition_test='2020/08/01', updated_at=datetime(2020, 1, 8)),
Row(id=9, issue_type='SUBSCRIPTION', partition_test='2020/08/01', updated_at=datetime(2020, 1, 9)),
Row(id=10, issue_type='SUBSCRIPTION', partition_test='2020/08/01', updated_at=datetime(2020, 1, 10)),
]
- Use following codes to
overwriteto initiate the table on S3 (Glue)
hudi_options = {
'hoodie.table.name': tableName,
'hoodie.datasource.write.recordkey.field': 'id',
'hoodie.index.type': 'BLOOM',
'hoodie.datasource.write.partitionpath.field': 'partition_test',
'hoodie.datasource.write.table.name': tableName,
'hoodie.datasource.write.operation': 'upsert',
'hoodie.datasource.write.precombine.field': 'updated_at',
'hoodie.upsert.shuffle.parallelism': 2,
'hoodie.insert.shuffle.parallelism': 2,
'hoodie.bulkinsert.shuffle.parallelism': 10,
'hoodie.datasource.hive_sync.database': databaseName,
'hoodie.datasource.hive_sync.table': tableName,
'hoodie.datasource.hive_sync.enable': 'true',
'hoodie.datasource.hive_sync.assume_date_partitioning': 'true',
'hoodie.datasource.hive_sync.partition_fields': 'partition_test',
'hoodie.consistency.check.enabled': 'true',
}
df.write.format("org.apache.hudi"). \
options(**hudi_options). \
mode("overwrite"). \
save(basePath) # some s3 path
- Check on Athena/Redshift to see if the table has been written successfully. (We use Glue as our metastore)
- Upsert the following data on same partition ('2020/08/01'). See that
issue_typehas been changed toblah.
Seeupdated_atis now 2020/1/2. In my understanding, the previous record with id=1 in partition 2020/08/01 should be deleted and change to this new record as the new one has biggerupdated_at
[
Row(id=1, issue_type='blah', partition_test='2020/08/01', updated_at=datetime(2020, 1, 2)),
]
- Use the exact same hudi options from above, and use below to "append".
upsert_df.write.format("org.apache.hudi"). \
options(**hudi_options). \
mode("append"). \
save(basePath) # same s3 path
- Below is what I see after the above operation.
[
Row(id=1, issue_type='SUBSCRIPTION', partition_test='2020/08/01', updated_at=datetime(2020, 1, 1)),
Row(id=1, issue_type='blah', partition_test='2020/08/01', updated_at=datetime(2020, 1, 2)),
Row(id=2, issue_type='SUBSCRIPTION', partition_test='2020/08/01', updated_at=datetime(2020, 1, 2)),
Row(id=2, issue_type='SUBSCRIPTION', partition_test='2020/08/01', updated_at=datetime(2020, 1, 2)),
Row(id=3, issue_type='SUBSCRIPTION', partition_test='2020/08/01', updated_at=datetime(2020, 1, 3)),
Row(id=3, issue_type='SUBSCRIPTION', partition_test='2020/08/01', updated_at=datetime(2020, 1, 3)),
Row(id=4, issue_type='SUBSCRIPTION', partition_test='2020/08/01', updated_at=datetime(2020, 1, 4)),
Row(id=4, issue_type='SUBSCRIPTION', partition_test='2020/08/01', updated_at=datetime(2020, 1, 4)),
Row(id=5, issue_type='SUBSCRIPTION', partition_test='2020/08/01', updated_at=datetime(2020, 1, 5)),
Row(id=5, issue_type='SUBSCRIPTION', partition_test='2020/08/01', updated_at=datetime(2020, 1, 5)),
Row(id=6, issue_type='SUBSCRIPTION', partition_test='2020/08/01', updated_at=datetime(2020, 1, 6)),
Row(id=6, issue_type='SUBSCRIPTION', partition_test='2020/08/01', updated_at=datetime(2020, 1, 6)),
Row(id=7, issue_type='SUBSCRIPTION', partition_test='2020/08/01', updated_at=datetime(2020, 1, 7)),
Row(id=7, issue_type='SUBSCRIPTION', partition_test='2020/08/01', updated_at=datetime(2020, 1, 7)),
Row(id=8, issue_type='SUBSCRIPTION', partition_test='2020/08/01', updated_at=datetime(2020, 1, 8)),
Row(id=8, issue_type='SUBSCRIPTION', partition_test='2020/08/01', updated_at=datetime(2020, 1, 8)),
Row(id=9, issue_type='SUBSCRIPTION', partition_test='2020/08/01', updated_at=datetime(2020, 1, 9)),
Row(id=9, issue_type='SUBSCRIPTION', partition_test='2020/08/01', updated_at=datetime(2020, 1, 9)),
Row(id=10, issue_type='SUBSCRIPTION', partition_test='2020/08/01', updated_at=datetime(2020, 1, 10)),
Row(id=10, issue_type='SUBSCRIPTION', partition_test='2020/08/01', updated_at=datetime(2020, 1, 10)),
]
I checked the _hoodie_file_name and all of the records have same file names
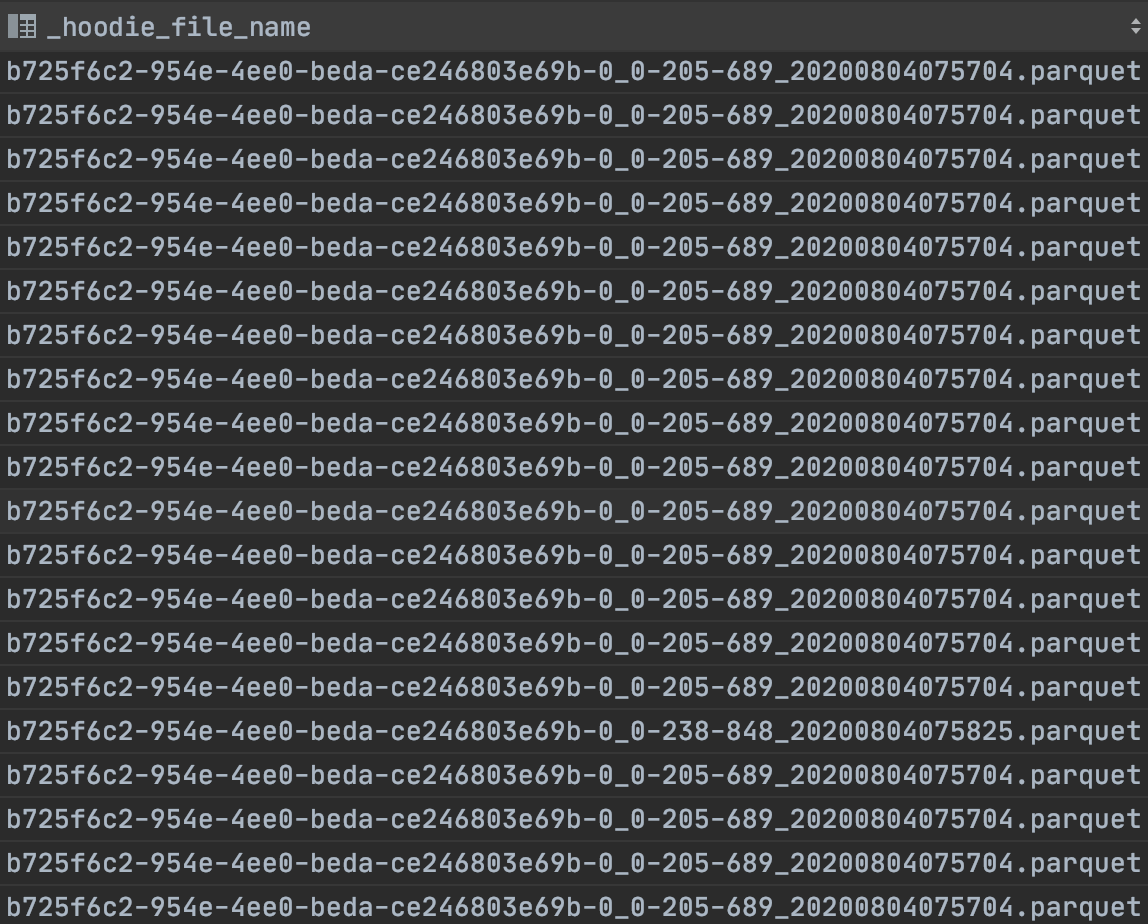
Here's the screenshot of our S3 bucket.
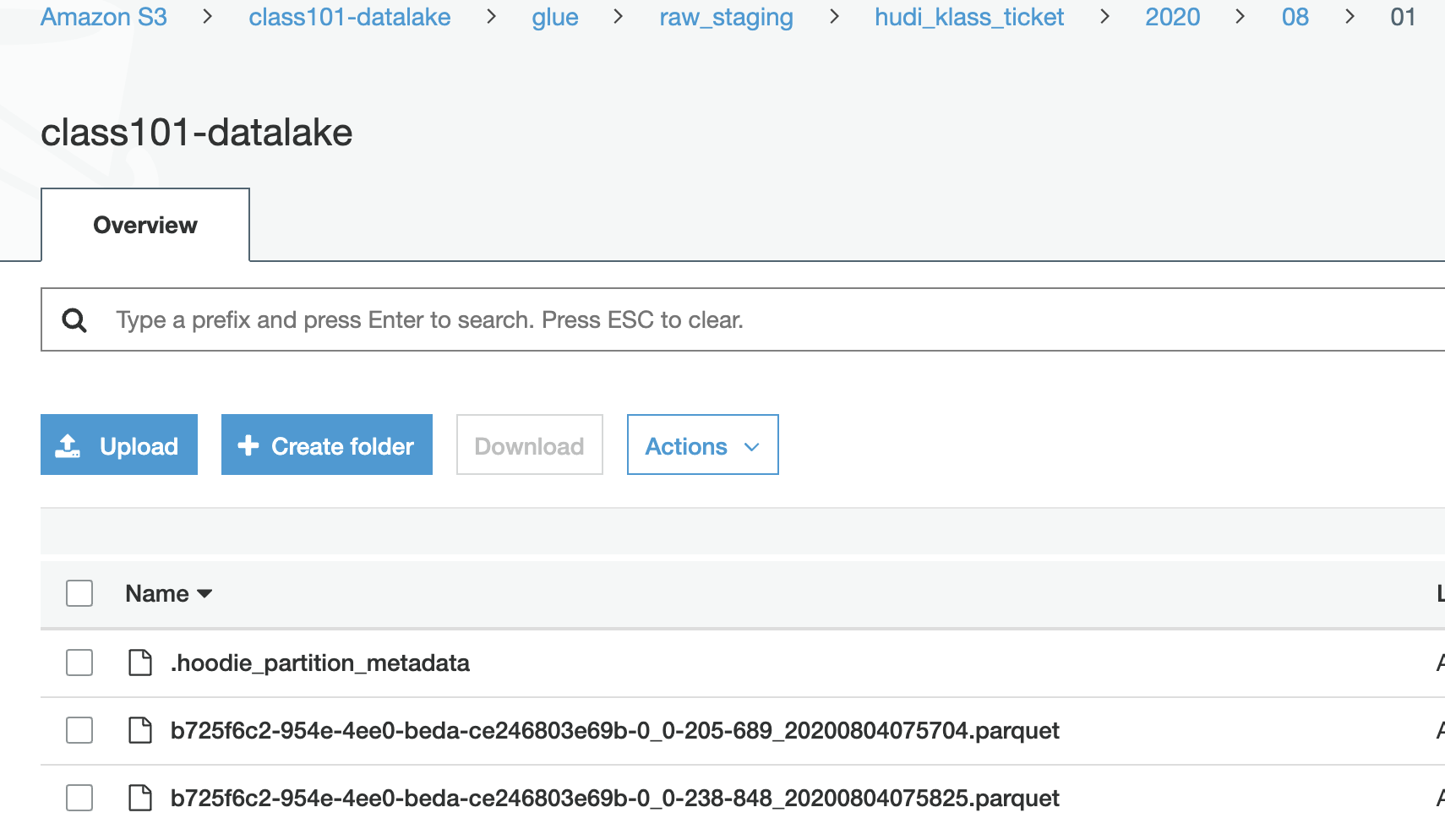
It looks like the parquet file has been duplicated.
Expected behavior
I explained altogether above.
Environment Description
-
Hudi version : 0.5.0 (EMR 6.0.0)
-
Spark version : 2.4.4
-
Hive version : 3.1.2 (We use Glue as metastore)
-
Hadoop version : 3.2.1-amzn-0
-
Storage (HDFS/S3/GCS..) : S3
-
Running on Docker? (yes/no) : no (EMR)
Additional context
using the following jars
hudi-spark-bundle-0.5.0-incubating-amzn-1.jar
hudi-hive-bundle-0.5.0-incubating-amzn-1.jar
hudi-hadoop-mr-bundle-0.5.0-incubating-amzn-1.jar
spark-avro_2.12-2.4.4.jar
installed on EMR 6.0.0
Stacktrace
All the operations I ran above didn't error.