[SUPPORT] Spark Fails to Process 300Gb Of Data #2003
Description
Hi Guys,
I'm trying to migrate my biggest dataset to Hudi and I'm facing some errors.
Data Size: 350Gb
Spark Master: 4 Cpus, 16 Gb Ram
Cores Nodes: 8 R5.4xLarge = 16 cpus, 122 Gb ram EACH
MY spark Submit:
spark-submit --deploy-mode cluster --conf "spark.executor.extraJavaOptions -XX:NewSize=1g -XX:SurvivorRatio=2 -XX:+UseCompressedOops -XX:+UseConcMarkSweepGC -XX:+UseParNewGC -XX:CMSInitiatingOccupancyFraction=70 -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -XX:+PrintGCApplicationStoppedTime -XX:+PrintGCApplicationConcurrentTime -XX:+PrintTenuringDistribution -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/tmp/hoodie-heapdump.hprof" --conf spark.executor.cores=5 --conf spark.executor.memory=33g --conf spark.executor.memoryOverhead=2048 --conf spark.serializer=org.apache.spark.serializer.KryoSerializer --conf spark.sql.hive.convertMetastoreParquet=false --packages org.apache.hudi:hudi-spark-bundle_2.11:0.5.3,org.apache.spark:spark-avro_2.11:2.4.4
My hudi Options:
{
"hoodie.datasource.write.recordkey.field":"id",
"hoodie.table.name":"stockout",
"hoodie.datasource.write.table.name":"stockout",
"hoodie.datasource.write.operation":"bulk_insert",
"hoodie.datasource.write.partitionpath.field":"created_date_brt",
"hoodie.datasource.write.hive_style_partitioning":"true",
"hoodie.combine.before.insert":"true",
"hoodie.combine.before.upsert":"false",
"hoodie.datasource.write.precombine.field":"LineCreatedTimestamp",
"hoodie.datasource.write.keygenerator.class":"org.apache.hudi.keygen.SimpleKeyGenerator",
"hoodie.parquet.small.file.limit":996147200,
"hoodie.parquet.max.file.size":1073741824,
"hoodie.parquet.block.size":1073741824,
"hoodie.copyonwrite.record.size.estimate":512,
"hoodie.cleaner.commits.retained":10,
"hoodie.datasource.hive_sync.enable":"true",
"hoodie.datasource.hive_sync.database":"datalake_raw",
"hoodie.datasource.hive_sync.table":"stockout",
"hoodie.datasource.hive_sync.partition_fields":"created_date_brt",
"hoodie.datasource.hive_sync.partition_extractor_class":"org.apache.hudi.hive.MultiPartKeysValueExtractor",
"hoodie.datasource.hive_sync.jdbcurl":"jdbc:hive2://ip-10-0-21-127.us-west-2.compute.internal:10000",
"hoodie.insert.shuffle.parallelism":1500,
"hoodie.bulkinsert.shuffle.parallelism":700,
"hoodie.upsert.shuffle.parallelism":1500
}
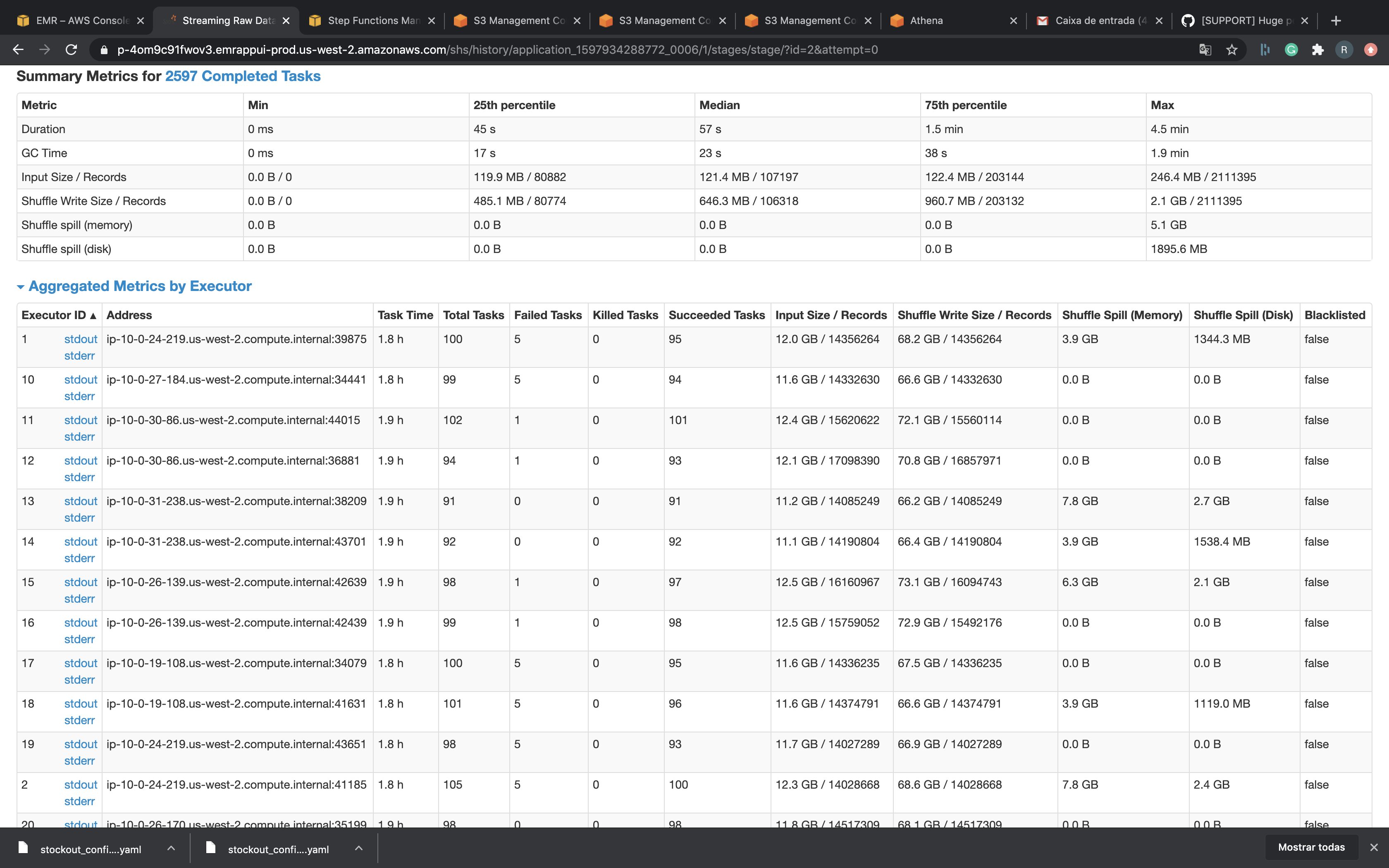
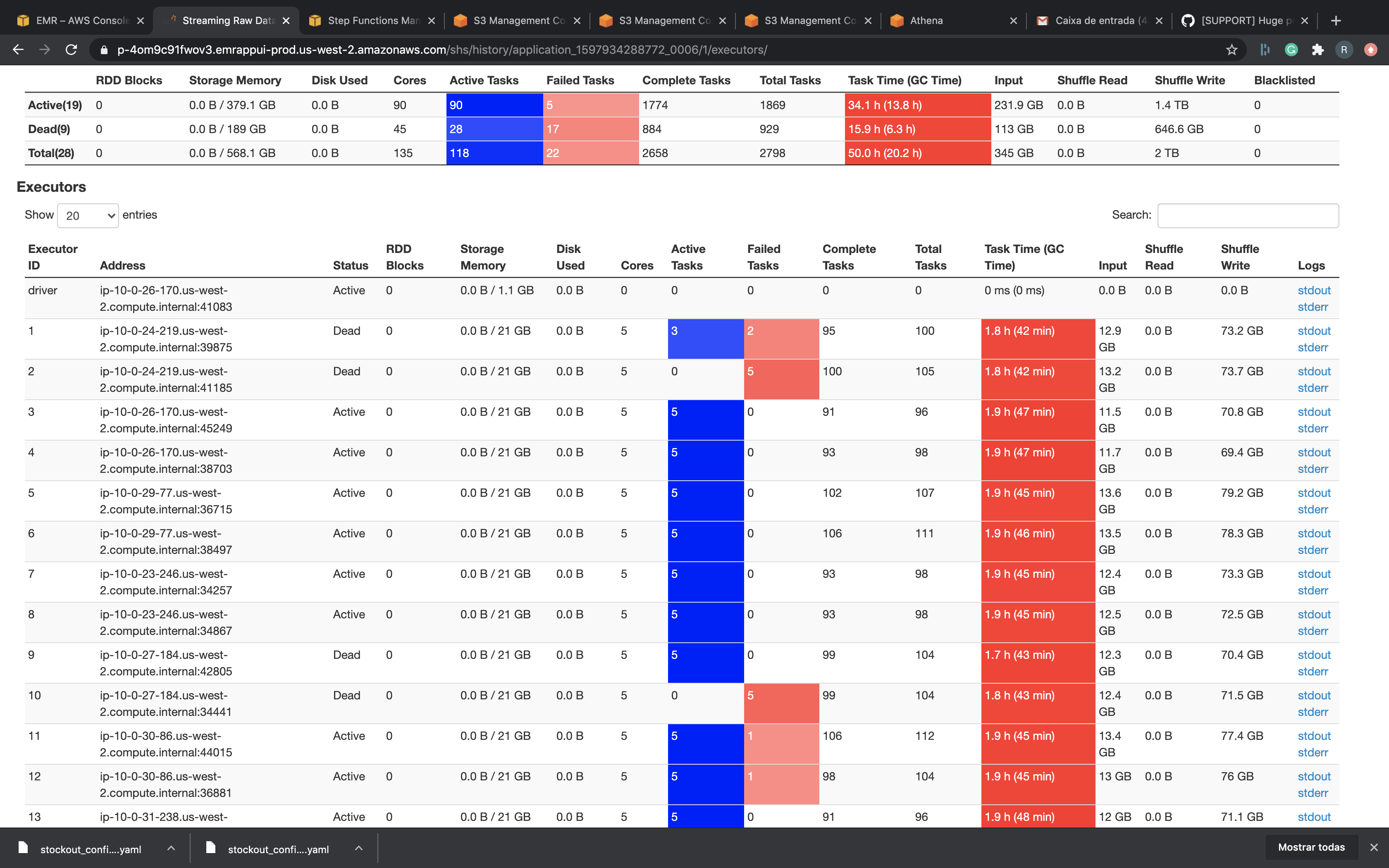
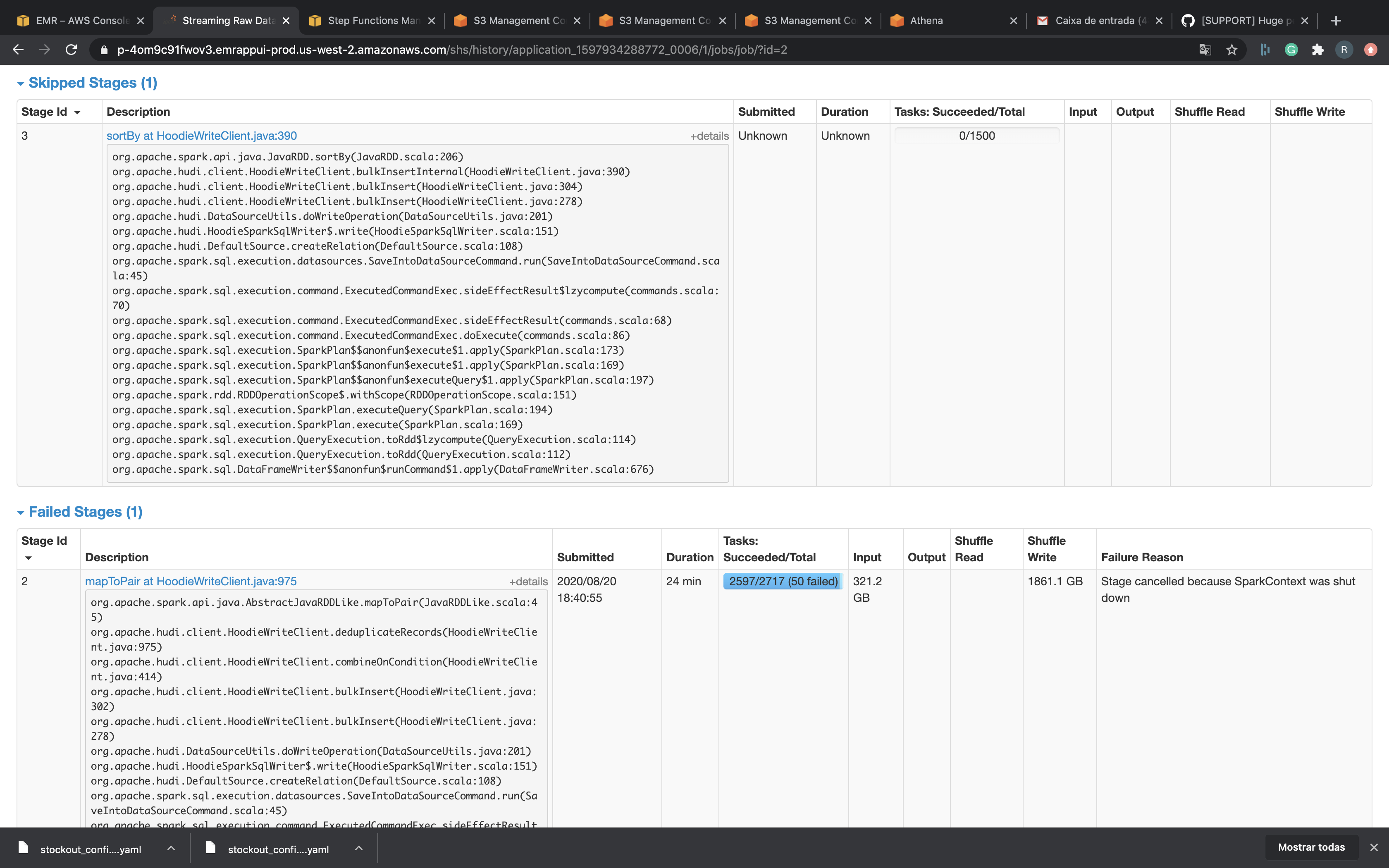
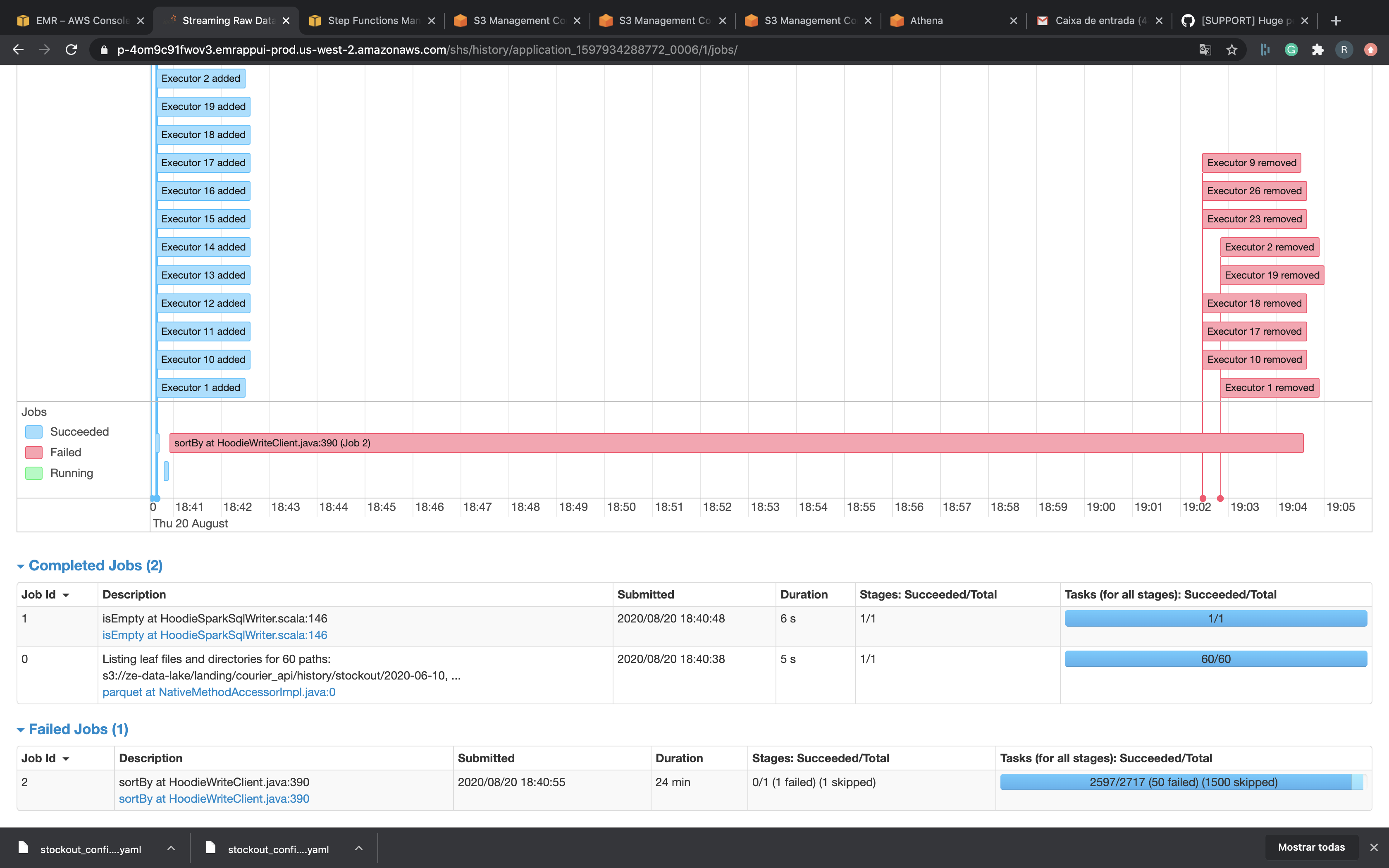
I tried use bulk_insert paralelism with 4000 but didn't work. I really don't know what to do...
Thank you.