[SUPPORT] ExecutorLostFailure - Try Processing 1TB Of Data #2464
Description
Hello,
I am making some tests with Hudi, now I tried to process a 1TB parquet dataset.
18 Nodes
R5.4xlarge
128Gb - 16 cores
My spark Submit
spark-submit --deploy-mode cluster --conf spark.executor.cores=5 --conf spark.executor.memoryOverhead=3000 --conf spark.executor.memory=33g --packages org.apache.hudi:hudi-spark-bundle_2.11:0.6.0,org.apache.spark:spark-avro_2.11:2.4.4 --conf spark.serializer=org.apache.spark.serializer.KryoSerializer s3://data-lake/temp/apache_hudi.py
Hudi Options:
hudi_options = {
'hoodie.table.name': tableName,
'hoodie.datasource.write.recordkey.field': 'id',
'hoodie.datasource.write.table.name': tableName,
'hoodie.datasource.write.operation': 'bulk_insert',
'hoodie.datasource.write.precombine.field': 'LineCreatedTimestamp',
'hoodie.bulkinsert.shuffle.parallelism': 4000,
'hoodie.parquet.small.file.limit': 536870912,
'hoodie.parquet.max.file.size': 1073741824,
'hoodie.parquet.block.size': 536870912,
'hoodie.copyonwrite.record.size.estimate':1024,
'hoodie.datasource.write.hive_style_partitioning': 'true',
'hoodie.datasource.hive_sync.enable': 'true',
'hoodie.datasource.hive_sync.database': 'true',
'hoodie.datasource.hive_sync.table': 'stockout_test',
'hoodie.datasource.hive_sync.database': 'raw_courier_api',
'hoodie.datasource.write.partitionpath.field': 'created_date_brt',
'hoodie.datasource.hive_sync.partition_fields': 'created_date_brt',
'hoodie.datasource.hive_sync.partition_extractor_class': 'org.apache.hudi.hive.MultiPartKeysValueExtractor',
'hoodie.datasource.hive_sync.jdbcurl': 'jdbc:hive2://emr:10000'
}
Error:
ExecutorLostFailure (executor 53 exited caused by one of the running tasks) Reason: Container killed by YARN for exceeding memory limits. 36.4 GB of 35.9 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead or disabling yarn.nodemanager.vmem-check-enabled because of YARN-4714.
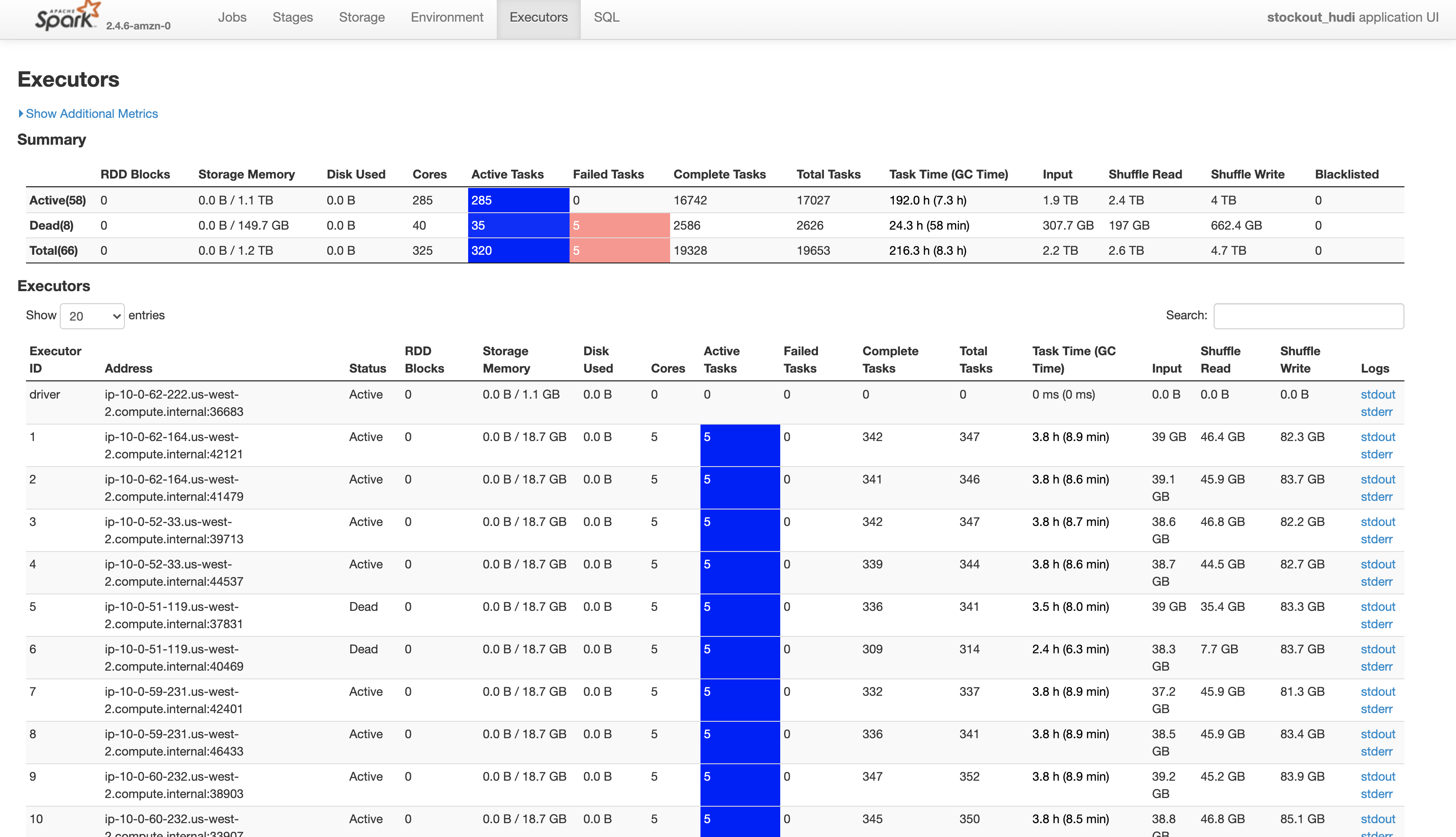
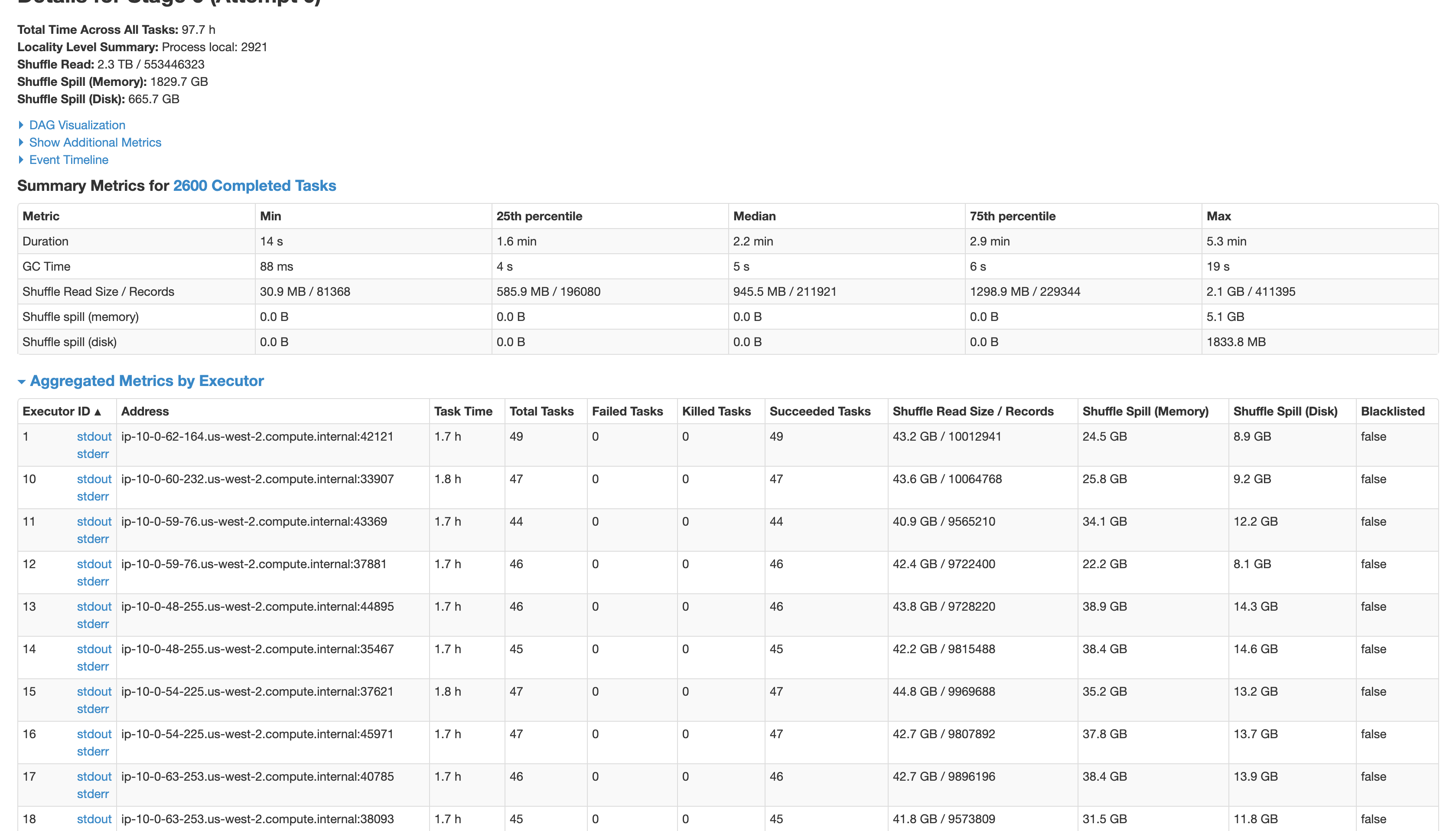
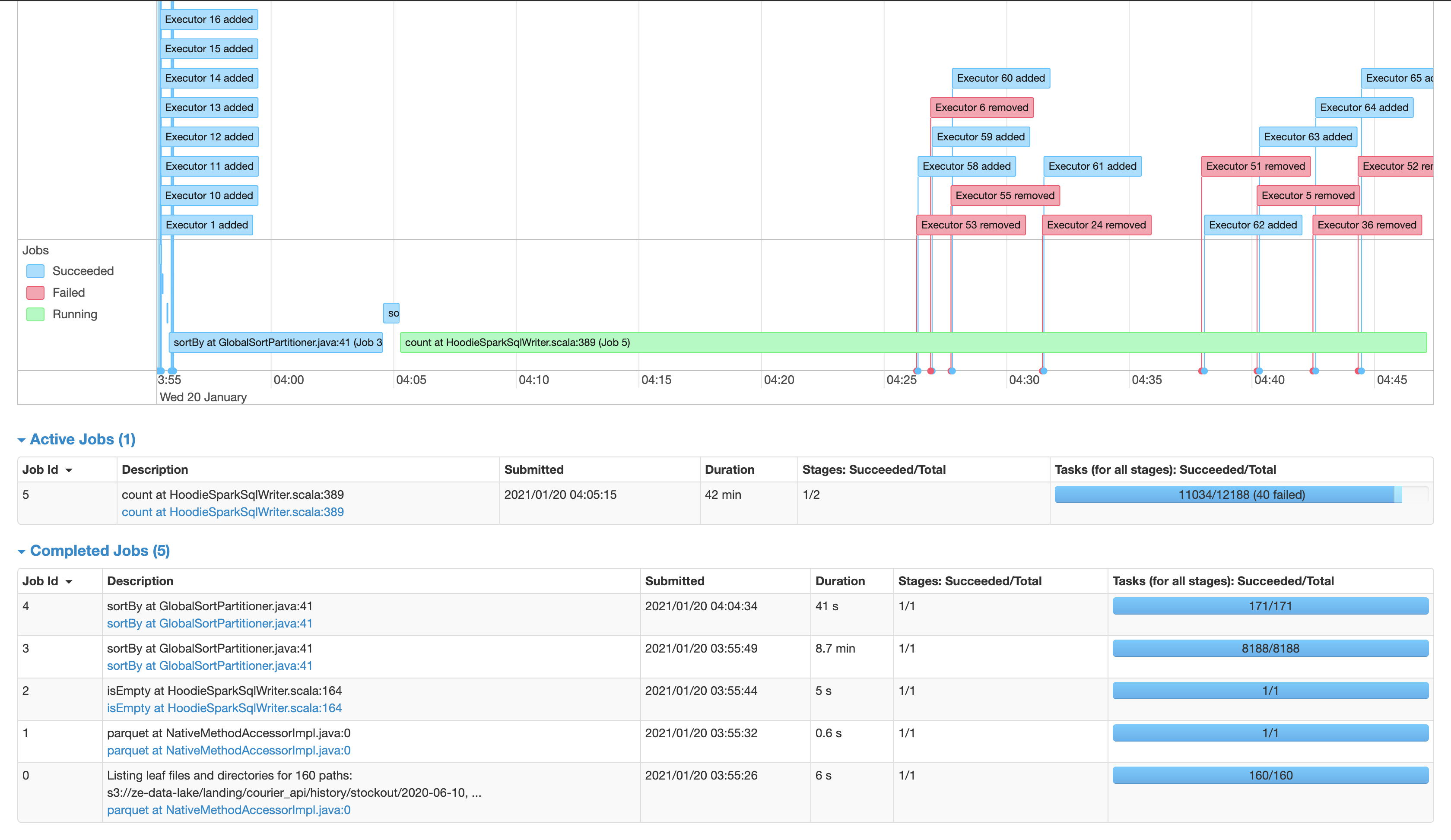
Could you help to process this dataset?