[SUPPORT] When I used 100,000 data to update 100 million data, The program is stuck #2676
Description
Environment Description
-
Hudi version : 0.7.0/0.6.0
-
Spark version : 2.4.4
-
Hive version :2.3.1
-
Hadoop version : 2.7.5
-
Storage (HDFS/S3/GCS..) : HDFS
-
Running on Docker? (yes/no) : no
When I used 100,000 data to update 100 million data, the program was stuck and could not execute further. The table type used was MOR. The program execution diagram is as follows:
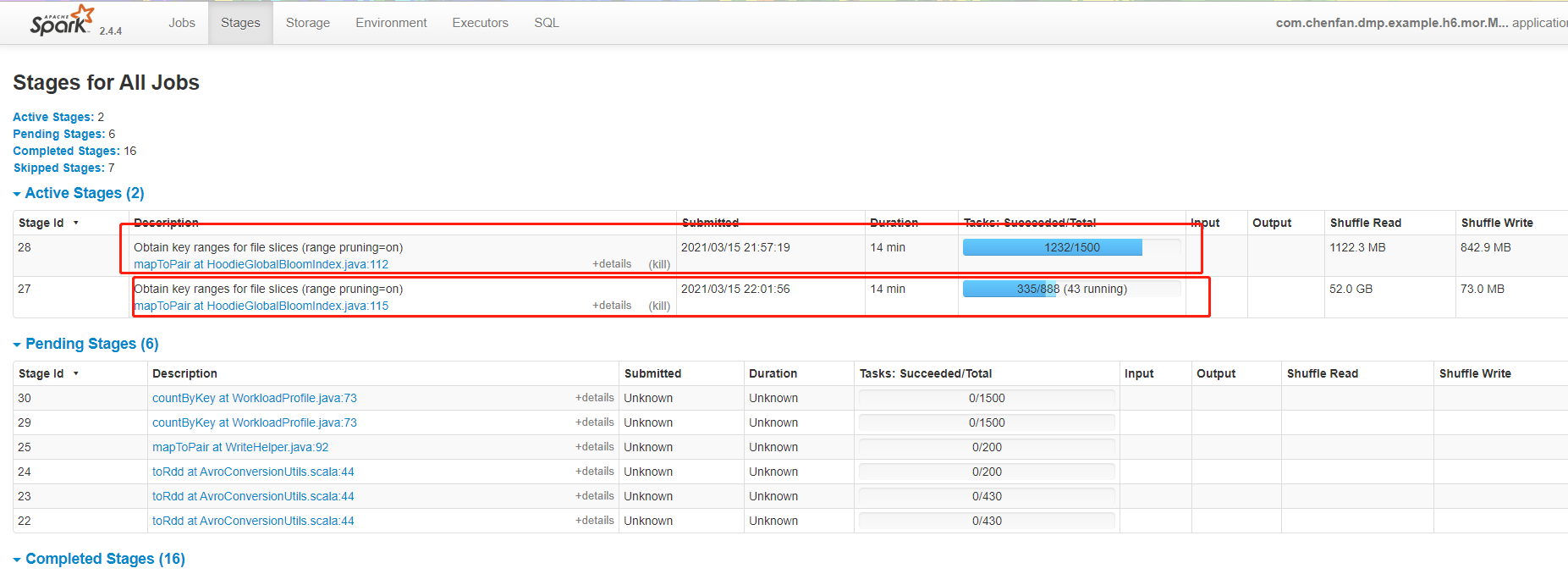
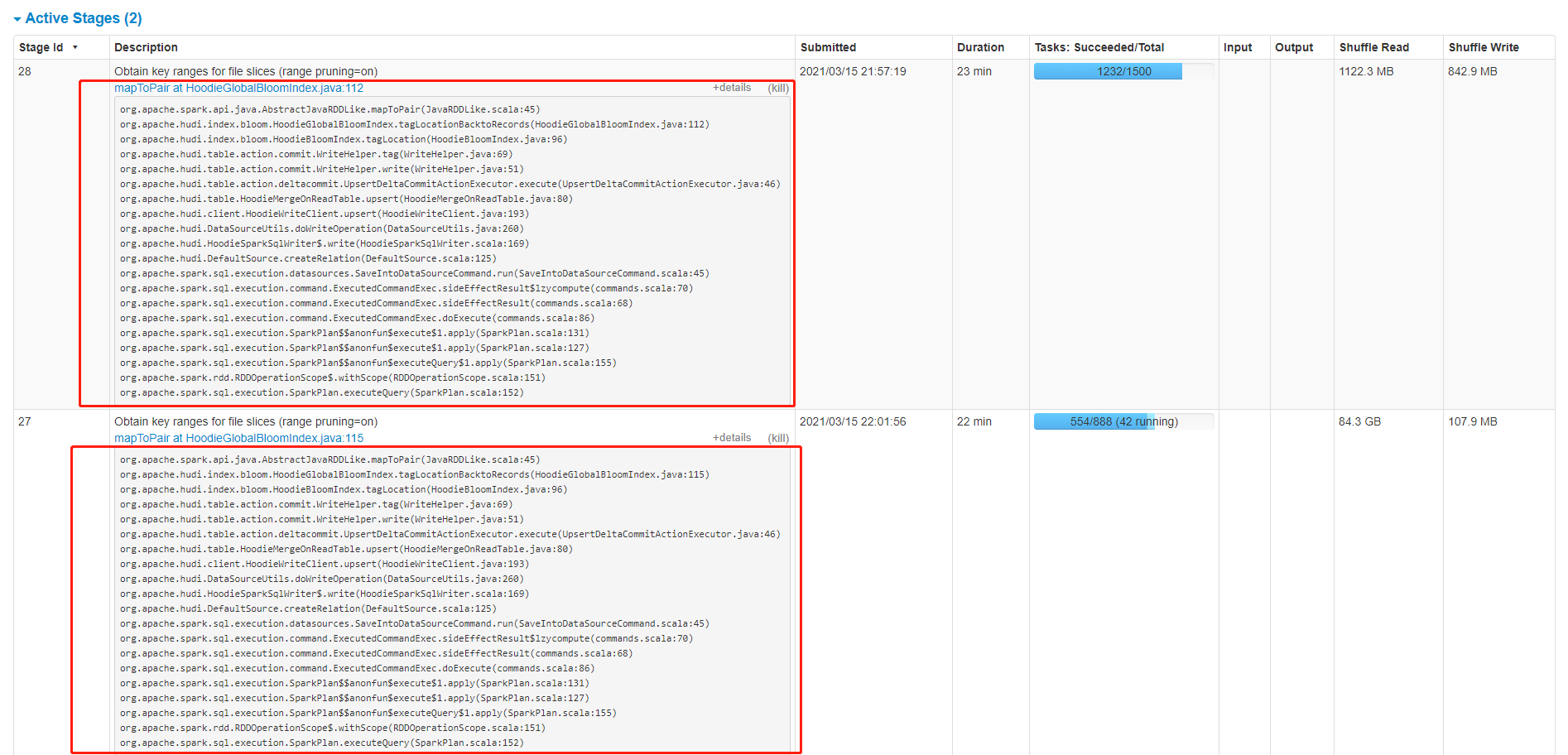
hudi parameters as follow:
TABLE_TYPE_OPT_KEY -> MOR_TABLE_TYPE_OPT_VAL,
// OPERATION_OPT_KEY -> WriteOperationType.UPSERT.value,
OPERATION_OPT_KEY -> "upsert",
RECORDKEY_FIELD_OPT_KEY -> pkCol,
PRECOMBINE_FIELD_OPT_KEY -> preCombineCol,
"hoodie.embed.timeline.server" -> "false",
"hoodie.cleaner.commits.retained" -> "1",
"hoodie.cleaner.fileversions.retained" -> "1",
"hoodie.cleaner.policy" -> HoodieCleaningPolicy.KEEP_LATEST_FILE_VERSIONS.name(),
"hoodie.keep.min.commits" -> "3",
"hoodie.keep.max.commits" -> "4",
"hoodie.compact.inline" -> "true",
"hoodie.compact.inline.max.delta.commits" -> "1",
// "hoodie.copyonwrite.record.size.estimate" -> String.valueOf(500),
PARTITIONPATH_FIELD_OPT_KEY -> "dt",
HIVE_PARTITION_FIELDS_OPT_KEY -> "dt",
HIVE_URL_OPT_KEY -> "jdbc:hive2:/0.0.0.0:10000",
HIVE_USER_OPT_KEY -> "",
HIVE_PASS_OPT_KEY -> "",
HIVE_DATABASE_OPT_KEY -> hiveDatabaseName,
HIVE_TABLE_OPT_KEY -> hiveTableName,
HIVE_SYNC_ENABLED_OPT_KEY -> "true",
HoodieIndexConfig.BLOOM_INDEX_UPDATE_PARTITION_PATH -> "true",
HoodieWriteConfig.TABLE_NAME -> hiveTableName,
HIVE_PARTITION_EXTRACTOR_CLASS_OPT_KEY -> classOf[MultiPartKeysValueExtractor].getName,
HoodieIndexConfig.INDEX_TYPE_PROP -> HoodieIndex.IndexType.GLOBAL_BLOOM.name(),
"hoodie.insert.shuffle.parallelism" -> parallelism,
"hoodie.upsert.shuffle.parallelism" -> parallelism