[SUPPORT] Large latencies in hudi writes using upsert mode. #3077
Description
Describe the problem you faced
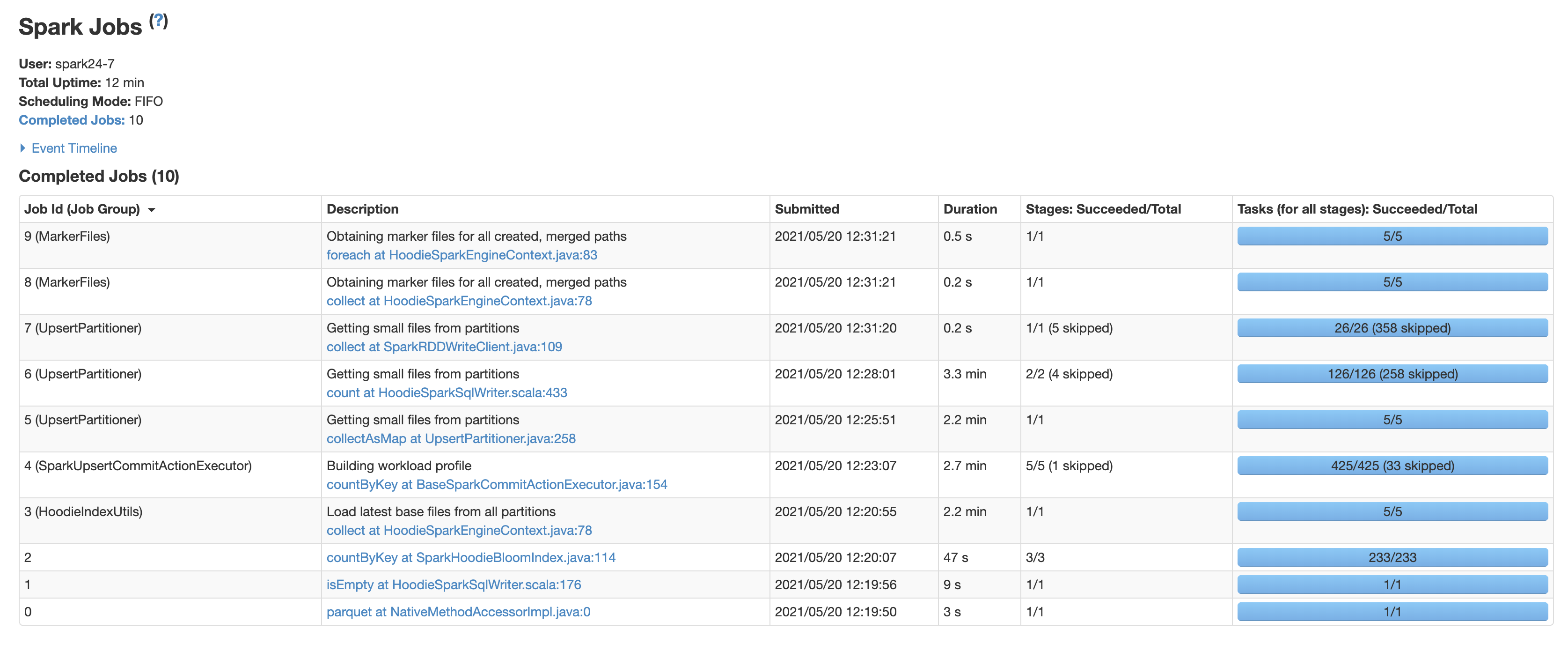
I am currently working on a POC to integrate Hudi with our existing Data lake. I am seeing large latencies in hudi writes. It is almost 7x compared to the partitioned parquet writes we perform now.
I am writing around 2.5 million rows (3.9 GB) in two batches with upsert mode. The first write gets completed in 2-3 mins. For the second batch, the latency is around 12-14 mins while writing with our existing system takes around 1.6-2 mins. The data contains negligible updates (99> % inserts and <1% updates). However in the rare case of duplicated trips we want to override the old data points with the new one. In our write use-case, most of the data will impact the recent partitions. Currently, for testing I am creating and writing to 5 partitions according to the probability distribution [10, 10, 10, 10, 60]
Pyspark configs:
conf = conf.set(“spark.driver.memory”, ‘6g’)
conf = conf.set(“spark.executor.instances”, 8)
conf = conf.set(“spark.executor.memory”, ‘4g’)
conf = conf.set(“spark.executor.cores”, 4)
Hudi options:
hudi_options = {
'hoodie.table.name': table_name,
'hoodie.datasource.write.recordkey.field': 'applicationId,userId,driverId,timestamp',
'hoodie.datasource.write.partitionpath.field': 'packet_date',
'hoodie.datasource.write.keygenerator.class': 'org.apache.hudi.keygen.ComplexKeyGenerator',
'hoodie.datasource.write.hive_style_partitioning': 'true',
'hoodie.datasource.write.table.name': table_name,
'hoodie.datasource.write.operation': 'upsert',
'hoodie.datasource.write.precombine.field': 'created_at_date',
'hoodie.upsert.shuffle.parallelism': 200,
'hoodie.insert.shuffle.parallelism': 200,
'hoodie.bloom.index.prune.by.ranges': 'false',
'hoodie.bloom.index.filter.type': 'DYNAMIC_V0',
'hoodie.index.bloom.num_entries': 30000,
'hoodie.bloom.index.filter.dynamic.max.entries': 120000,
}
Environment Description
-
Hudi version : 0.7.0
-
Spark version : 2.4.7
-
Storage (HDFS/S3/GCS..) : S3
-
Running on Docker? (yes/no) : no
Additional context
In addition I have experimented with the following
- Tried decreasing the file sizes
- Increasing 'hoodie.bloom.index.parallelism'
- Setting 'hoodie.metadata.enable' true.
You can see the jobs taking the most time from the screen shot attached