[SUPPORT] Skew partition on simple count in a Hudi Table #3143
Description
Hello Guys,
I'm trying to run a simples spark query on a Hudi dataset but took a long to finished and I realized that exist very skew partitions, but I didnt understand why.
The table has 50gb
Spark 3.0.1
Emr 6.1
Hudi 0.8
Cluster
16 r4.xlarge machines
query:
import pyspark.sql.functions as F
spark_filtered.where(F.col("location_id") == -1).count()
Hudi options to create the table
'hoodie.table.name': self.table_name,
'hoodie.datasource.write.recordkey.field': "request_id,poc_id",
'hoodie.datasource.write.table.name': self.table_name,
'hoodie.datasource.write.operation': 'bulk_insert',
'hoodie.bulkinsert.shuffle.parallelism': self.bulk_insert_shuffle_parallelism,
'hoodie.datasource.hive_sync.enable': self.hive_sync_enabled,
'hoodie.datasource.hive_sync.database': self.hive_database_name,
'hoodie.datasource.hive_sync.jdbcurl': f'jdbc:hive2://{self.hive_jdbc_url}:10000',
'hoodie.datasource.hive_sync.table': self.table_name,
'hoodie.datasource.hive_sync.partition_extractor_class': 'org.apache.hudi.hive.NonPartitionedExtractor',
'hoodie.datasource.hive_sync.support_timestamp': 'true',
'hoodie.datasource.write.keygenerator.class': 'org.apache.hudi.keygen.NonpartitionedKeyGenerator',
'hoodie.datasource.write.row.writer.enable': 'false',
'hoodie.parquet.small.file.limit': 536870912,
'hoodie.parquet.max.file.size': 1073741824,
'hoodie.parquet.block.size': 536870912
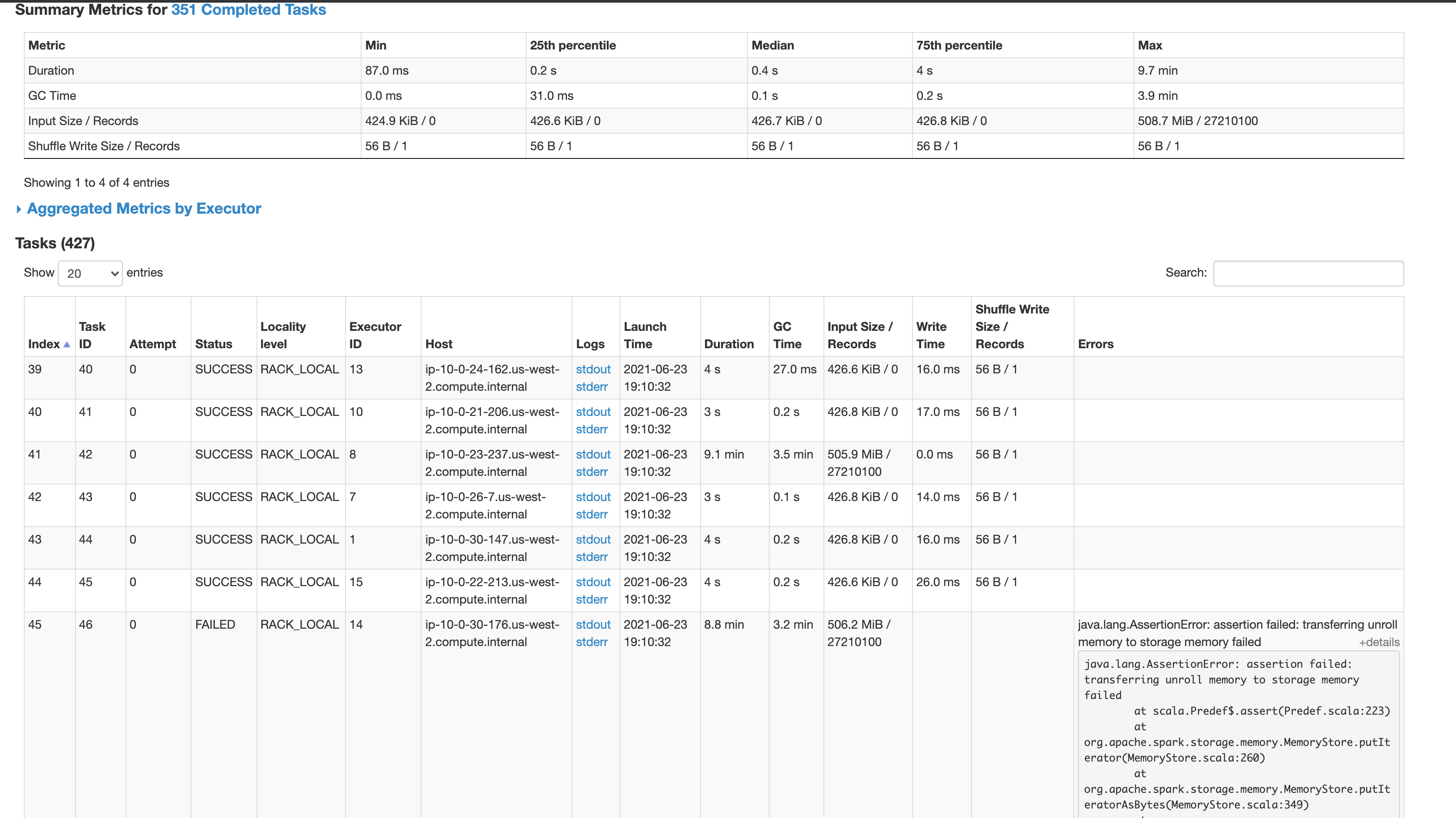
Could you help me? thank you