[SUPPORT] INSERT operation performance vs UPSERT operation #8316
Description
Tips before filing an issue
-
Have you gone through our FAQs?
-
Join the mailing list to engage in conversations and get faster support at dev-subscribe@hudi.apache.org.
-
If you have triaged this as a bug, then file an issue directly.
Describe the problem you faced
INSERT operation works with almost the same performance as UPSERT operation.
There's no acceleration with using INSERT operation.
To Reproduce
We use non partitioned table with BUCKET CONSISTENT_HASHING index.
Here is config:
val hudiWriteConfigs = Map(
"hoodie.datasource.write.table.type" -> "MERGE_ON_READ",
"hoodie.write.markers.type" -> "direct",
"hoodie.metadata.enable" -> "true",
"hoodie.index.type" -> "BUCKET",
"hoodie.index.bucket.engine" -> "CONSISTENT_HASHING",
"hoodie.bucket.index.num.buckets" -> "10000",
"hoodie.storage.layout.partitioner.class" -> "org.apache.hudi.table.action.commit.SparkBucketIndexPartitioner",
"hoodie.compact.inline" -> "true",
"hoodie.compact.inline.max.delta.commits" -> "10",
"hoodie.compact.inline.max.delta.seconds" -> "3600",
"hoodie.compact.inline.trigger.strategy" -> "NUM_OR_TIME",
"hoodie.clean.async" -> "false",
"hoodie.clean.max.commits" -> "10",
"hoodie.cleaner.commits.retained" -> "10",
"hoodie.keep.min.commits" -> "20",
"hoodie.keep.max.commits" -> "30",
"hoodie.datasource.write.keygenerator.class" -> "org.apache.hudi.keygen.NonpartitionedKeyGenerator"
)
Steps to reproduce the behavior:
- Run UPSERT of batch of 3000 rows
df_u.write.format("hudi").options(hudiWriteConfigs).option("hoodie.datasource.write.recordkey.field", "_Fld19066_TYPE,_Fld19066_RTRef,_Fld19066_RRRef,_Fld19067RRef,_Fld19068RRef,_Fld19069,_Fld24101RRef").option("hoodie.datasource.write.precombine.field", "_ts_ms").option("hoodie.merge.allow.duplicate.on.inserts", "true").option("hoodie.datasource.write.operation", "upsert").mode("append").option("hoodie.table.name", "_InfoRg19065").save("/warehouse/debezium_hudi_test/data/_InfoRg19065") - Run INSERT of batch of 3000 rows
df_u.write.format("hudi").options(hudiWriteConfigs).option("hoodie.datasource.write.recordkey.field", "_Fld19066_TYPE,_Fld19066_RTRef,_Fld19066_RRRef,_Fld19067RRef,_Fld19068RRef,_Fld19069,_Fld24101RRef").option("hoodie.datasource.write.precombine.field", "_ts_ms").option("hoodie.merge.allow.duplicate.on.inserts", "true").option("hoodie.datasource.write.operation", "insert").mode("append").option("hoodie.table.name", "_InfoRg19065").save("/warehouse/debezium_hudi_test/data/_InfoRg19065") - View and compare jobs executed in Spark UI
UPSERT execution
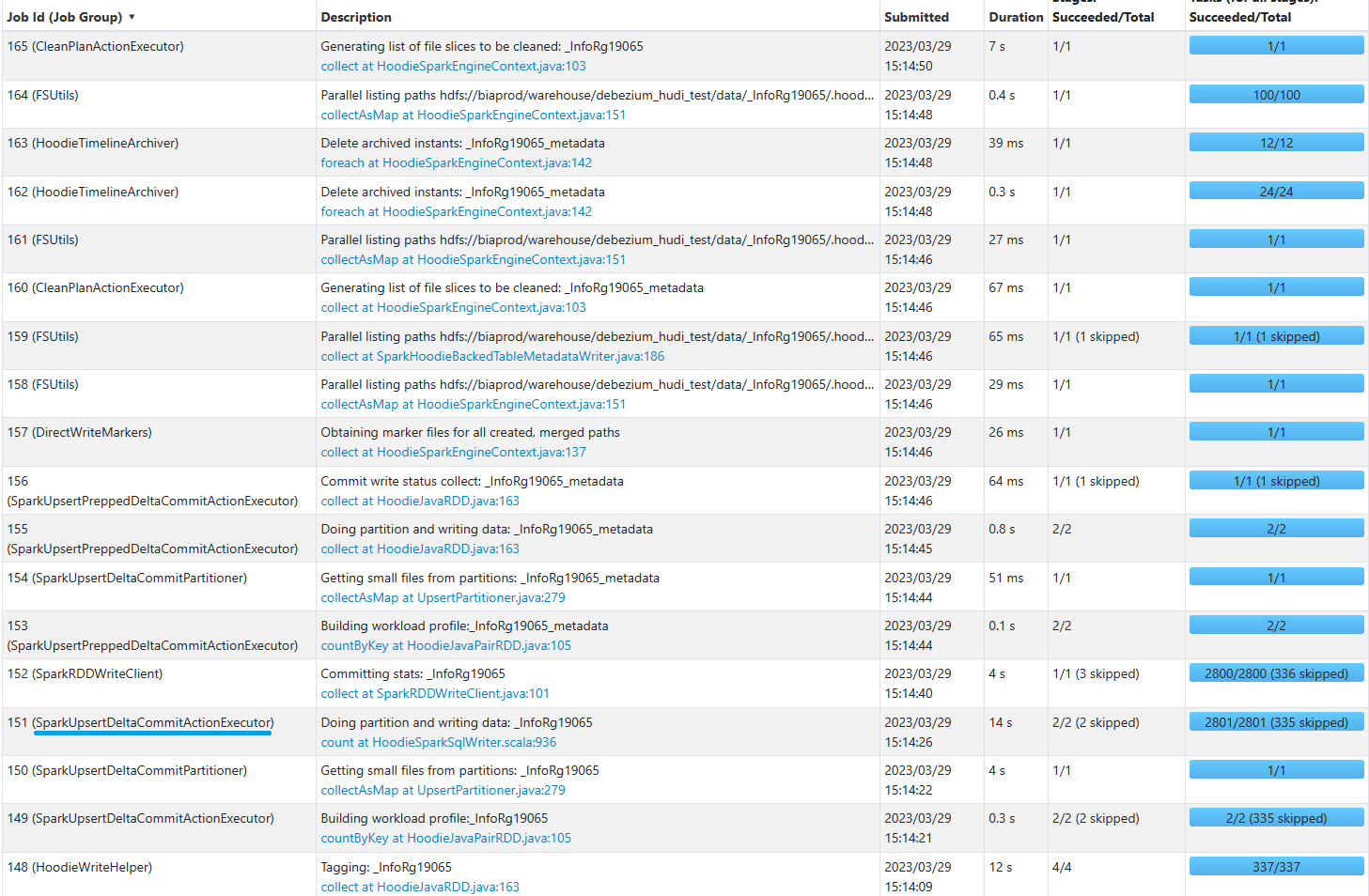
INSERT execution
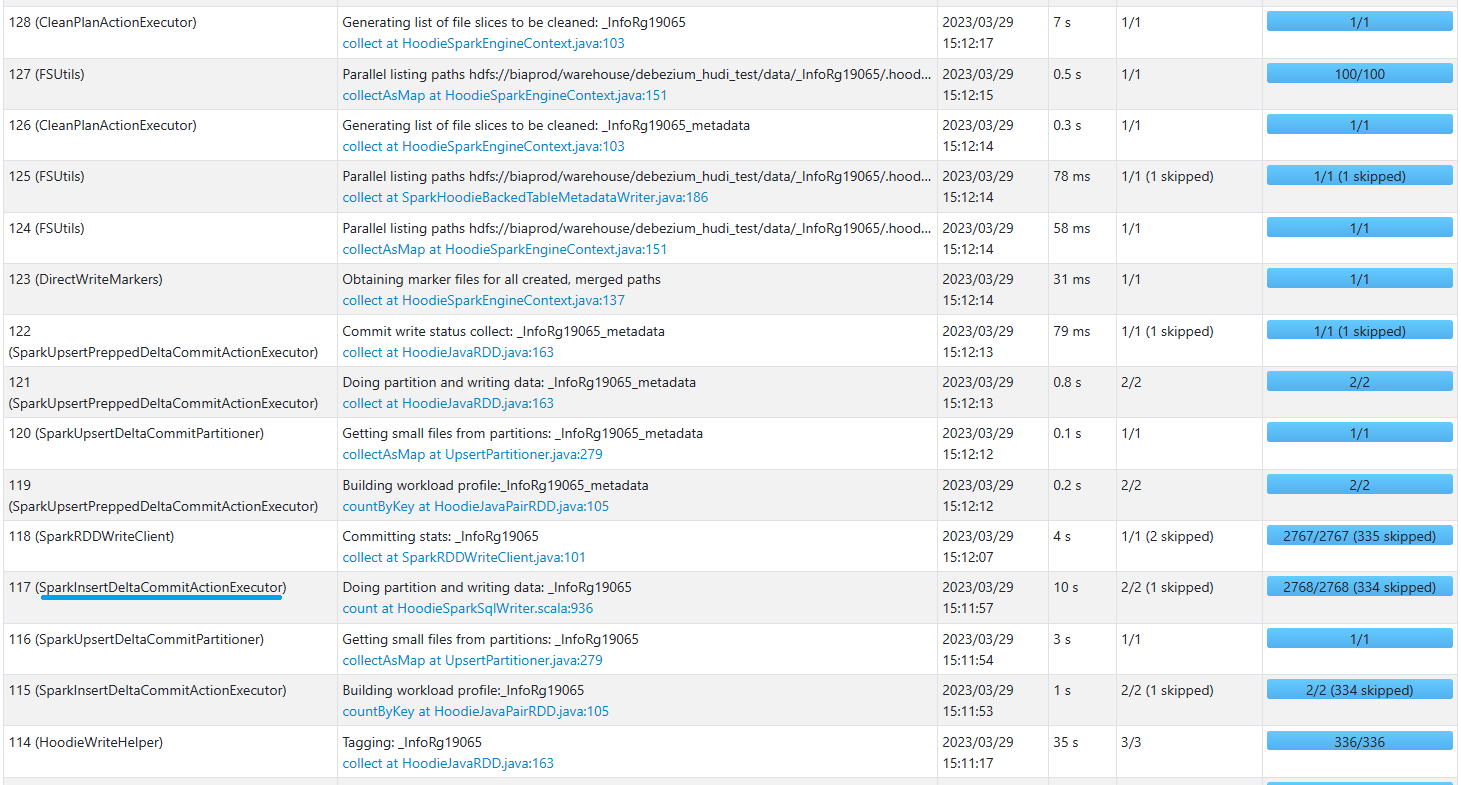
Expected behavior
Expected that performance of INSERT operation would be better than of UPSERT operation
Environment Description
-
Hudi version : 0.13.0
-
Spark version : 3.2.2
-
Hive version :
-
Hadoop version : 3.3.2
-
Storage (HDFS/S3/GCS..) : HDFS
-
Running on Docker? (yes/no) : no