[SUPPORT] PartialUpdateAvroPayload and OverwriteNonDefaultsWithLatestAvroPayload Payload class configuration not working through DeltaStreamer #8637
Description
Hello !
I have built hudi 0.13 on emr-6.7.0 (home/hadoop/hudi) and tried changing payload class configuration for deltastreamer and it looks like PartialUpdateAvroPayload and OverwriteNonDefaultsWithLatestAvroPayload Payload class configuration not working through DeltaStreamer and it is working through pyspark scripts for ParquetDFSSource
Environment Description
-
Hudi version : 0.13 on emr-6.7.0
-
Spark version : Spark 3.2.1, Scala 0.12
-
Hive version : Hive 3.1.3
-
Hadoop version : Hadoop 3.2.1,
-
Storage (HDFS/S3/GCS..) : S3
-
Running on Docker? (yes/no) : No, EMR
To Reproduce
Steps to reproduce the behavior:
- Download full.parquet and cdc.parquet sample source file
https://transer-files.s3.amazonaws.com/full.parquet
https://transer-files.s3.amazonaws.com/cdc.parquet
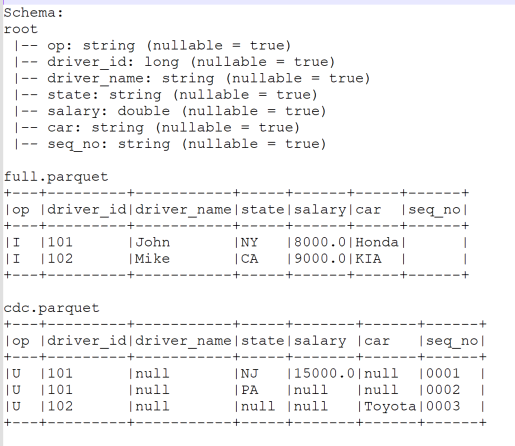
- Run DeltaStreamer Full and CDC run: Make sure to update Source and Target and jar location
Full DeltaStreamer
spark-submit --class org.apache.hudi.utilities.deltastreamer.HoodieDeltaStreamer
--conf spark.serializer=org.apache.spark.serializer.KryoSerializer
--conf spark.sql.hive.convertMetastoreParquet=false
--conf spark.sql.catalog.spark_catalog=org.apache.spark.sql.hudi.catalog.HoodieCatalog
--jars /home/hadoop/hudi/packaging/hudi-aws-bundle/target/hudi-aws-bundle-0.13.0.jar /home/hadoop/hudi/packaging/hudi-utilities-bundle/target/hudi-utilities-bundle_2.12-0.13.0.jar --table-type COPY_ON_WRITE
--op INSERT
--source-ordering-field seq_no
--hoodie-conf hoodie.datasource.write.recordkey.field=driver_id
--hoodie-conf hoodie.datasource.write.partitionpath.field=
--hoodie-conf hoodie.datasource.write.keygenerator.class=org.apache.hudi.keygen.NonpartitionedKeyGenerator
--hoodie-conf hoodie.datasource.write.payload.class=org.apache.hudi.common.model.OverwriteWithLatestAvroPayload
--transformer-class org.apache.hudi.utilities.transform.SqlQueryBasedTransformer
--hoodie-conf hoodie.deltastreamer.transformer.sql="select 1==2 AS _hoodie_is_deleted, * from "
--hoodie-conf hoodie.deltastreamer.source.dfs.root=s3://<BUCKET_NAME>/POC/LANDING/HUDI_PAYLOAD_TEST_FILES/FULL/
--source-class org.apache.hudi.utilities.sources.ParquetDFSSource
--target-base-path s3://<BUCKET_NAME>/POC/RAW/DELTASTREAMER/HUDI_PAYLOAD_TEST_DELTASTREAMER
--target-table HUDI_PAYLOAD_TEST_DELTASTREAMER
--hoodie-conf hoodie.metadata.enable=false
--hoodie-conf hoodie.datasource.read.file.index.listing.mode=eager
CDC DeltaStreamer:
spark-submit --class org.apache.hudi.utilities.deltastreamer.HoodieDeltaStreamer
--conf spark.serializer=org.apache.spark.serializer.KryoSerializer
--conf spark.sql.hive.convertMetastoreParquet=false
--conf spark.sql.catalog.spark_catalog=org.apache.spark.sql.hudi.catalog.HoodieCatalog
--jars /home/hadoop/hudi/packaging/hudi-aws-bundle/target/hudi-aws-bundle-0.13.0.jar /home/hadoop/hudi/packaging/hudi-utilities-bundle/target/hudi-utilities-bundle_2.12-0.13.0.jar --table-type COPY_ON_WRITE
--op UPSERT
--source-ordering-field seq_no
--hoodie-conf hoodie.datasource.write.recordkey.field=driver_id
--hoodie-conf hoodie.datasource.write.partitionpath.field=
--hoodie-conf hoodie.datasource.write.keygenerator.class=org.apache.hudi.keygen.NonpartitionedKeyGenerator
--hoodie-conf hoodie.datasource.write.payload.class=org.apache.hudi.common.model.OverwriteNonDefaultsWithLatestAvroPayload
--transformer-class org.apache.hudi.utilities.transform.SqlQueryBasedTransformer
--hoodie-conf hoodie.deltastreamer.transformer.sql="select CASE WHEN Op = 'D' THEN TRUE ELSE FALSE END AS _hoodie_is_deleted, * from "
--hoodie-conf hoodie.deltastreamer.source.dfs.root=s3://<BUCKET_NAME>/POC/LANDING/HUDI_PAYLOAD_TEST_FILES/CDC/
--source-class org.apache.hudi.utilities.sources.ParquetDFSSource
--target-base-path s3://<BUCKET_NAME>/POC/RAW/DELTASTREAMER/HUDI_PAYLOAD_TEST_DELTASTREAMER
--target-table HUDI_PAYLOAD_TEST_DELTASTREAMER
--hoodie-conf hoodie.metadata.enable=false
--hoodie-conf hoodie.datasource.read.file.index.listing.mode=eager
- Validate the output:
Expected Output: (OverwriteNonDefaultsWithLatestAvroPayload)
+---+---------+-----------+-----+------+------+------+
|op |driver_id|driver_name|state|salary|car |seq_no|
+---+---------+-----------+-----+------+------+------+
|U |101 |John |PA |8000.0|Honda |0002 |
|U |102 |Mike |CA |9000.0|Toyota|0003 |
+---+---------+-----------+-----+------+------+------+
DeltaStreamer Output: (OverwriteNonDefaultsWithLatestAvroPayload)
export PYSPARK_PYTHON=$(which python3)
pyspark
--packages org.apache.hudi:hudi-spark3.2-bundle_2.12:0.13.0
--conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer'
--conf 'spark.sql.catalog.spark_catalog=org.apache.spark.sql.hudi.catalog.HoodieCatalog'
--conf 'spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension'
SparkSession available as 'spark'.
df = spark.read.format('hudi').load('s3://<BUCKET_NAME>/POC/RAW/DELTASTREAMER/HUDI_PAYLOAD_TEST_DELTASTREAMER/')
df.show(3, False)
+-------------------+---------------------+------------------+----------------------+------------------------------------------------------------------------+------------------+---+---------+-----------+-----+------+------+------+
|_hoodie_commit_time|_hoodie_commit_seqno |_hoodie_record_key|_hoodie_partition_path|_hoodie_file_name |_hoodie_is_deleted|op |driver_id|driver_name|state|salary|car |seq_no|
+-------------------+---------------------+------------------+----------------------+------------------------------------------------------------------------+------------------+---+---------+-----------+-----+------+------+------+
|20230504162852461 |20230504162852461_0_0|101 | |27307880-acfb-46cb-bccf-33390b9e727f-0_0-23-17_20230504162852461.parquet|false |U |101 |null |PA |null |null |0002 |
|20230504162852461 |20230504162852461_0_1|102 | |27307880-acfb-46cb-bccf-33390b9e727f-0_0-23-17_20230504162852461.parquet|false |U |102 |null |null |null |Toyota|0003 |
+-------------------+---------------------+------------------+----------------------+------------------------------------------------------------------------+------------------+---+---------+-----------+-----+------+------+------+
- Looks like payload class configuration didn't apply and still using default payload class
- Run same source files with pyspark script (pyspark_hudi_payload_test.py)
import pyspark
import sys
from pyspark.sql import SparkSession, Row
from pyspark.sql.types import StructType,StructField, StringType, LongType, DoubleType
from pyspark.sql.functions import col,lit
spark = SparkSession.builder.appName('Hudi').getOrCreate()
TABLE_NAME = 'HUDI_PAYLOAD_TEST_PYSPARK'
TARGET_PATH = 's3://<BUCKET_NAME>/POC/RAW/' + TABLE_NAME
run_type = sys.argv[1]
if run_type.lower() == 'full':
hudi_options = {
'hoodie.table.name': TABLE_NAME,
'hoodie.datasource.write.recordkey.field': 'driver_id',
'hoodie.datasource.write.partitionpath.field': '',
'hoodie.datasource.write.keygenerator.class': 'org.apache.hudi.keygen.NonpartitionedKeyGenerator',
'hoodie.datasource.write.table.name': TABLE_NAME,
'hoodie.datasource.write.table.type' : 'COPY_ON_WRITE',
'hoodie.datasource.write.operation': 'insert',
'hoodie.datasource.write.precombine.field': 'seq_no',
'hoodie.upsert.shuffle.parallelism': 5,
'hoodie.insert.shuffle.parallelism': 5,
'hoodie.datasource.read.file.index.listing.mode' : 'eager',
'hoodie.metadata.enable' : 'false'
}
# Read the full load parquet file from s3
df = spark.read.parquet('s3://<BUCKET_NAME>/POC/LANDING/HUDI_PAYLOAD_TEST_FILES/FULL/*.parquet')
df.write.format('org.apache.hudi').options(**hudi_options).mode("overwrite").save(TARGET_PATH)
elif run_type.lower() == 'cdc':
hudi_options = {
'hoodie.table.name': TABLE_NAME,
'hoodie.datasource.write.recordkey.field': 'driver_id',
'hoodie.datasource.write.partitionpath.field': '',
'hoodie.datasource.write.keygenerator.class': 'org.apache.hudi.keygen.NonpartitionedKeyGenerator',
'hoodie.datasource.write.payload.class' : 'org.apache.hudi.common.model.OverwriteNonDefaultsWithLatestAvroPayload',
'hoodie.datasource.write.table.name': TABLE_NAME,
'hoodie.datasource.write.table.type' : 'COPY_ON_WRITE',
'hoodie.datasource.write.operation': 'upsert',
'hoodie.datasource.write.precombine.field': 'seq_no',
'hoodie.upsert.shuffle.parallelism': 5,
'hoodie.insert.shuffle.parallelism': 5,
'hoodie.datasource.read.file.index.listing.mode' : 'eager',
'hoodie.metadata.enable' : 'false'
}
cdcDf = spark.read.parquet('s3://<BUCKET_NAME>/POC/LANDING/HUDI_PAYLOAD_TEST_FILES/CDC/*.parquet')
cdcDf.write.format('org.apache.hudi').options(**hudi_options).mode("append").save(TARGET_PATH)
Run Full load - passing 'full' as an argument
spark-submit --conf spark.serializer=org.apache.spark.serializer.KryoSerializer \
--conf spark.sql.catalog.spark_catalog=org.apache.spark.sql.hudi.catalog.HoodieCatalog \
--conf spark.sql.hive.convertMetastoreParquet=false \
--jars /usr/lib/spark/external/lib/spark-avro.jar,/home/hadoop/hudi/packaging/hudi-aws-bundle/target/hudi-aws-bundle-0.13.0.jar,/home/hadoop/hudi/packaging/hudi-utilities-bundle/target/hudi-utilities-bundle_2.12-0.13.0.jar \
pyspark_hudi_payload_test.py 'full'
Run cdc load - passing 'cdc' as an argument
spark-submit --conf spark.serializer=org.apache.spark.serializer.KryoSerializer \
--conf spark.sql.catalog.spark_catalog=org.apache.spark.sql.hudi.catalog.HoodieCatalog \
--conf spark.sql.hive.convertMetastoreParquet=false \
--jars /usr/lib/spark/external/lib/spark-avro.jar,/home/hadoop/hudi/packaging/hudi-aws-bundle/target/hudi-aws-bundle-0.13.0.jar,/home/hadoop/hudi/packaging/hudi-utilities-bundle/target/hudi-utilities-bundle_2.12-0.13.0.jar \
pyspark_hudi_payload_test.py 'cdc'
- Validate pyspark output:
Expected Output:
+---+---------+-----------+-----+------+------+------+
|op |driver_id|driver_name|state|salary|car |seq_no|
+---+---------+-----------+-----+------+------+------+
|U |101 |John |PA |8000.0|Honda |0002 |
|U |102 |Mike |CA |9000.0|Toyota|0003 |
+---+---------+-----------+-----+------+------+------+
Pyspark script output:
SparkSession available as 'spark'.
df = spark.read.format('hudi').load('s3://<BUCKET_NAME>/POC/RAW/HUDI_PAYLOAD_TEST_PYSPARK/')
df.show(3, False)
+-------------------+---------------------+------------------+----------------------+------------------------------------------------------------------------+---+---------+-----------+-----+------+------+------+
|_hoodie_commit_time|_hoodie_commit_seqno |_hoodie_record_key|_hoodie_partition_path|_hoodie_file_name |op |driver_id|driver_name|state|salary|car |seq_no|
+-------------------+---------------------+------------------+----------------------+------------------------------------------------------------------------+---+---------+-----------+-----+------+------+------+
|20230504163428168 |20230504163428168_0_0|101 | |29497a97-69ab-419e-8e57-f56bfd2d00cb-0_0-21-15_20230504163428168.parquet|U |101 |John |PA |8000.0|Honda |0002 |
|20230504163428168 |20230504163428168_0_1|102 | |29497a97-69ab-419e-8e57-f56bfd2d00cb-0_0-21-15_20230504163428168.parquet|U |102 |Mike |CA |9000.0|Toyota|0003 |
+-------------------+---------------------+------------------+----------------------+------------------------------------------------------------------------+---+---------+-----------+-----+------+------+------+
Pyspark script output is matching with expected output - I've also tried "PartialUpdateAvroPayload " and getting similar behavior.
So Could you please look at it and let me know if I'm missing any configuration in delta streamer ?
Thanks,
Nikul