[HUDI-92] Provide reasonable names for Spark DAG stages in Hudi.#1289
[HUDI-92] Provide reasonable names for Spark DAG stages in Hudi.#1289vinothchandar merged 1 commit intoapache:masterfrom
Conversation
|
@bvaradar @vinothchandar can you guys help review this ? |
|
@prashantwason I think you tried another approach using aspects to make the code look cleaner right ? Could you please briefly describe that approach here (pros and cons) here so reviewers are also aware of it ? |
|
A DAG stage name and description can be set using the JavaSparkContext.setJobDescription(...) method. The same name/description is used for all stages which use the same thread until the name/description is updated (another call to setJobDescription) or deleted (clearJobGroup). In this PR, I am using the ClassName as the stage name and a textual description derived from the method logic. HUDI classes have very descriptive names so this works well. There are two ways this may be done:
To use AOP approach, we can create a separate AspectJ file containing the Pointcuts (code locations to augment) and Advices (code to insert). There is a separate AspectJ compiler which at runtime can change the class bytecode to add the Advices. Pros of AOP approach:
Cons of AOP approach:
Since the code has a manageable number of places where DAG is created, I prefer the simpler manual approach. It also ends up documenting the code. |
|
@prashantwason this is a great contribution for anyone debugging hudi writing... Can you post some screenshots for how upsert/bulk_insert dags now show up on the UI? also @n3nash if you want to review this, feel free to grab this from me |
a4ecd36 to
5245677
Compare
|
Spark History Server Screenshots
|
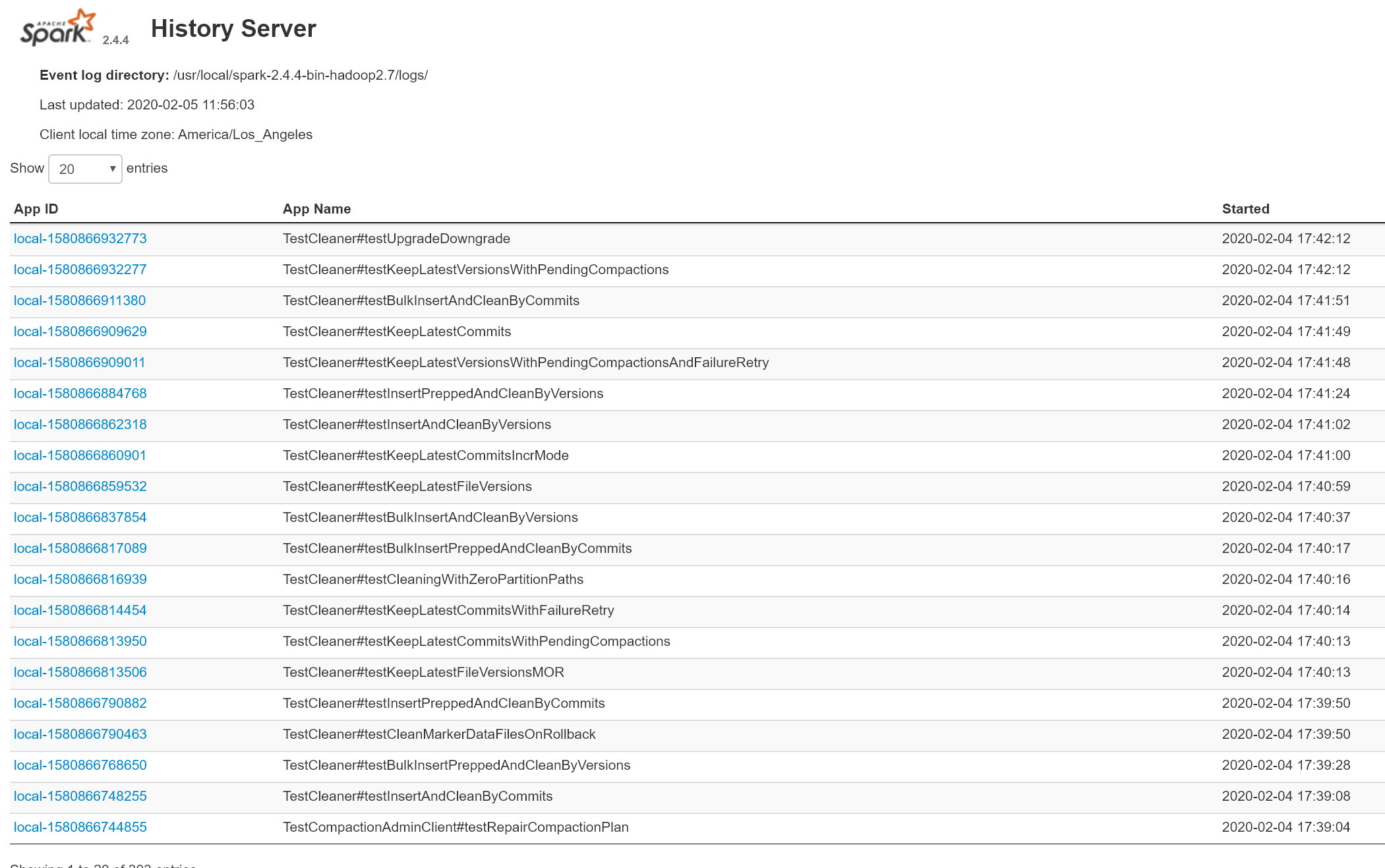
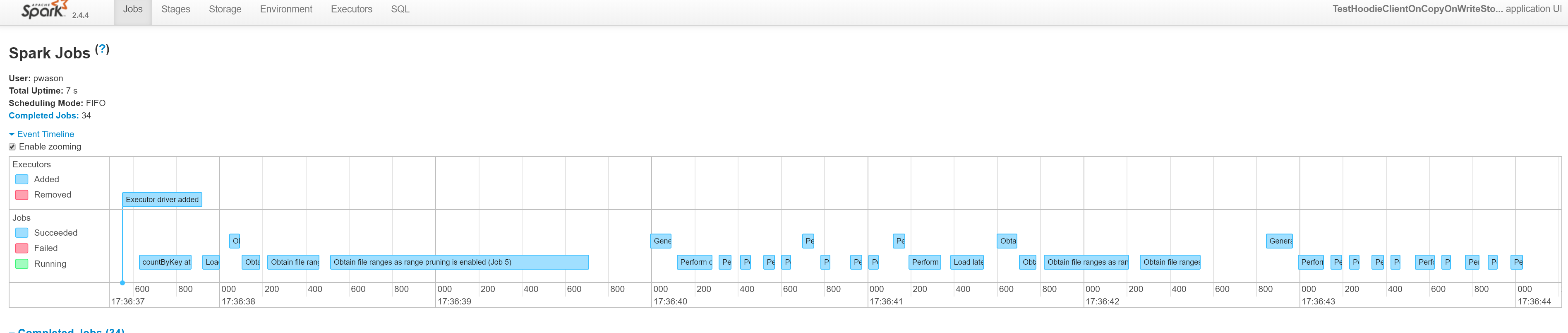
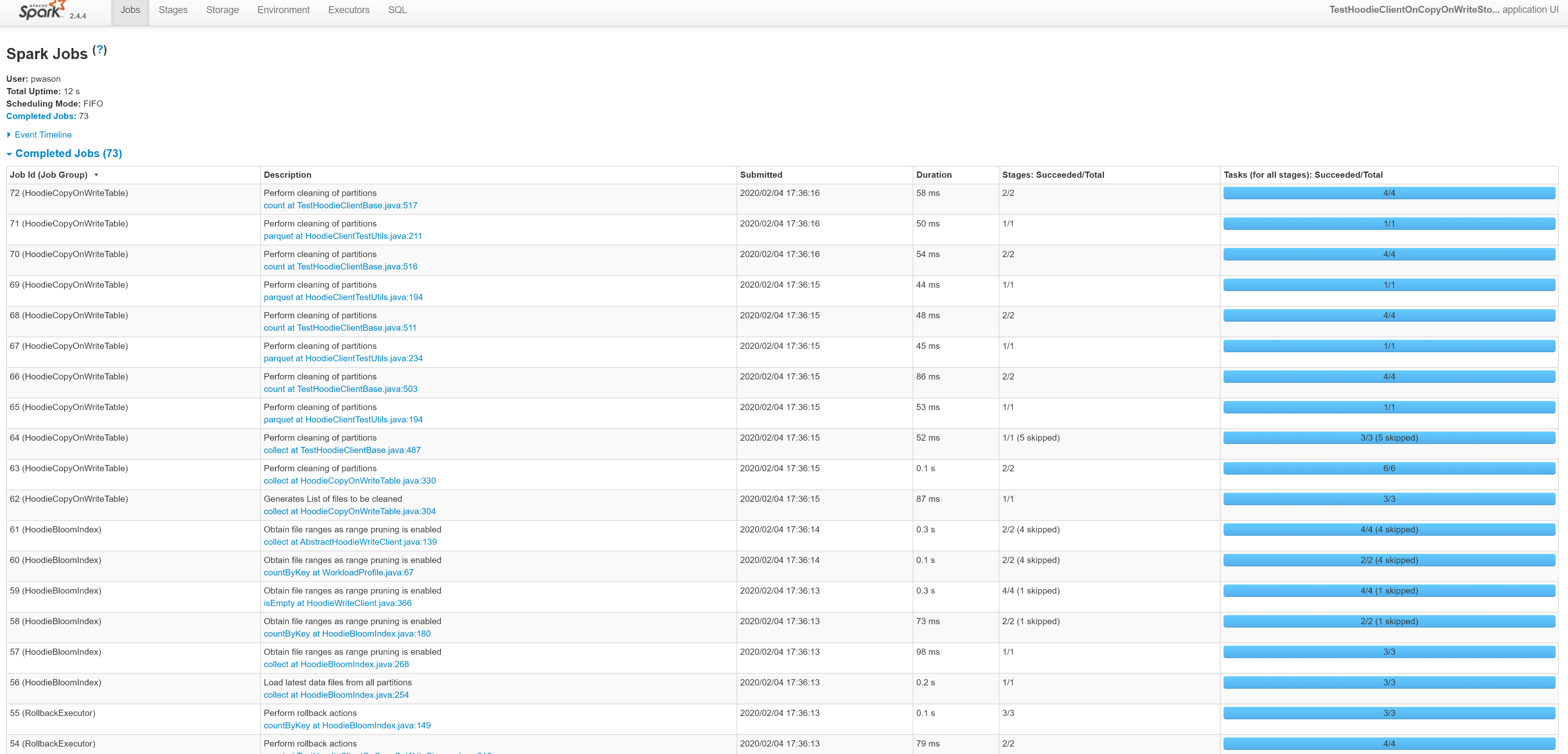
|
@prashantwason this is so awesome! Started reviewing this .. |
lets add this to the README, under a new section |
 vinothchandar
left a comment
vinothchandar
left a comment
There was a problem hiding this comment.
Made one pass and left some general comments to clarify the detail/description text..
Few high level questions
- It seems like you are only covering cases where an RDD is getting created? Is it possible to change the job group between stages? for e.g we have quite a few stages in HoodieBloomIndex and wondering if we can show them all https://cwiki.apache.org/confluence/display/HUDI/def~bloom-index
- Related to 1, if the answer is no, then how does an typical bulk_insert, upsert, insert dag look like? I am wondering if say the entire bloom index stages get named
Obtain file ranges as range pruning is enabled, since that was the last call we made to set the name...
hudi-client/src/main/java/org/apache/hudi/CompactionAdminClient.java
Outdated
Show resolved
Hide resolved
hudi-client/src/main/java/org/apache/hudi/CompactionAdminClient.java
Outdated
Show resolved
Hide resolved
hudi-client/src/main/java/org/apache/hudi/HoodieWriteClient.java
Outdated
Show resolved
Hide resolved
hudi-client/src/main/java/org/apache/hudi/index/bloom/HoodieBloomIndex.java
Outdated
Show resolved
Hide resolved
hudi-client/src/main/java/org/apache/hudi/io/compact/HoodieMergeOnReadTableCompactor.java
Outdated
Show resolved
Hide resolved
hudi-client/src/main/java/org/apache/hudi/table/HoodieCopyOnWriteTable.java
Outdated
Show resolved
Hide resolved
hudi-client/src/test/java/org/apache/hudi/HoodieClientTestHarness.java
Outdated
Show resolved
Hide resolved
The setJobGroup() description applies to the Thread and is used until either it is updated or removed. So we need to label each stage and they should show up correctly. We can label RDD creations as well as operations on them. |
if we could do that, and if you can post the |
|
@prashantwason Wondering if you have some screenshots for the upsert dag.. (I can try running tjhe PR locally if not) |
|
@prashantwason still driving this? Can I help get this moving along? |
|
@vinothchandar Yep, I would like this to move forward. Let me revive this as it seems there are merge conflicts now. We dont have this deployed yet so the only DAG screenshots I can provide are from unit tests. On you end, can you provide me some specific unit tests which are exercising the specific DAGs you are interested in? I can generate the screenshots from those. |
|
TestMergeOnReadTable or TestClientCopyOnWriteStorage etc that will do a full upsert dag for cow and mor are good starting points.. but really, we need to run an upsert with a real job to ensure these values also show up in real deployments |
|
@prashantwason this will be a good candidate to fast track into the next release. are you still working on this? |
|
@prashantwason : Once you update the PR, do let @lamber-ken know that its ready for review. |
f5220d9 to
ed384e6
Compare
|
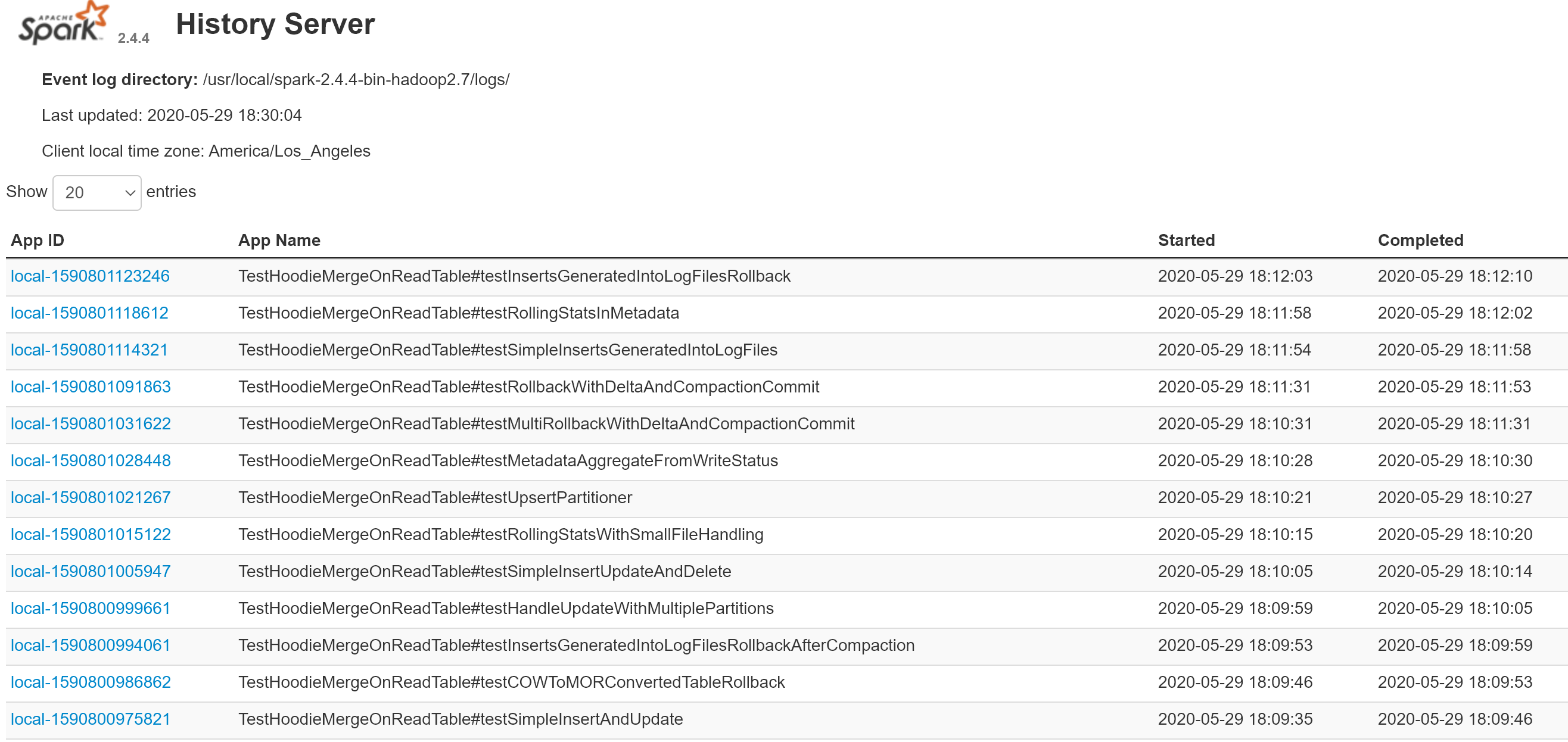
@lamber-ken I have updated the PR and added screenshots from the Spark History Server UI for some of the MOR table operations. Please have a look. |
|
List of executed tests - the name is made up of the test and the method Various DAGs |
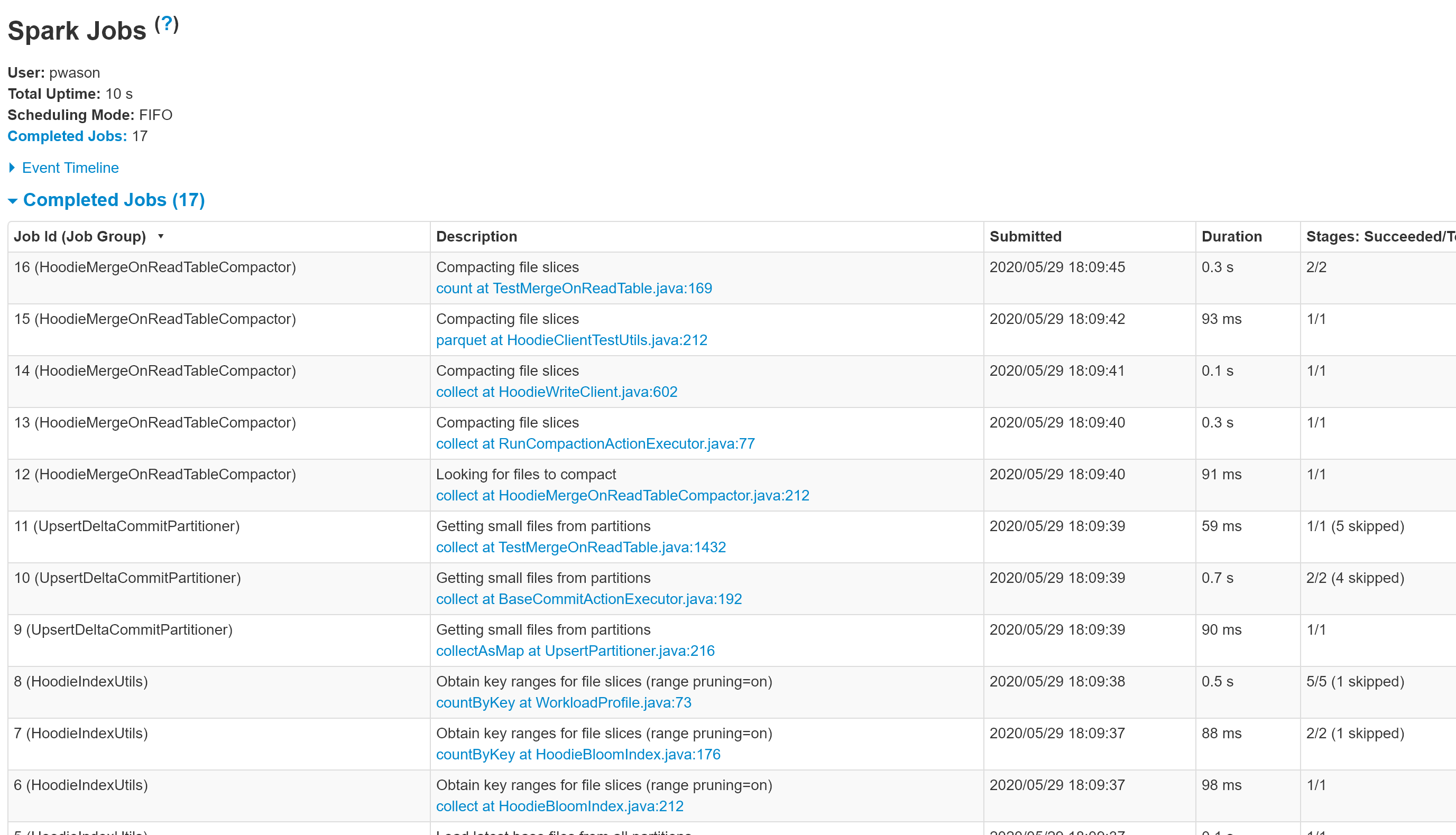
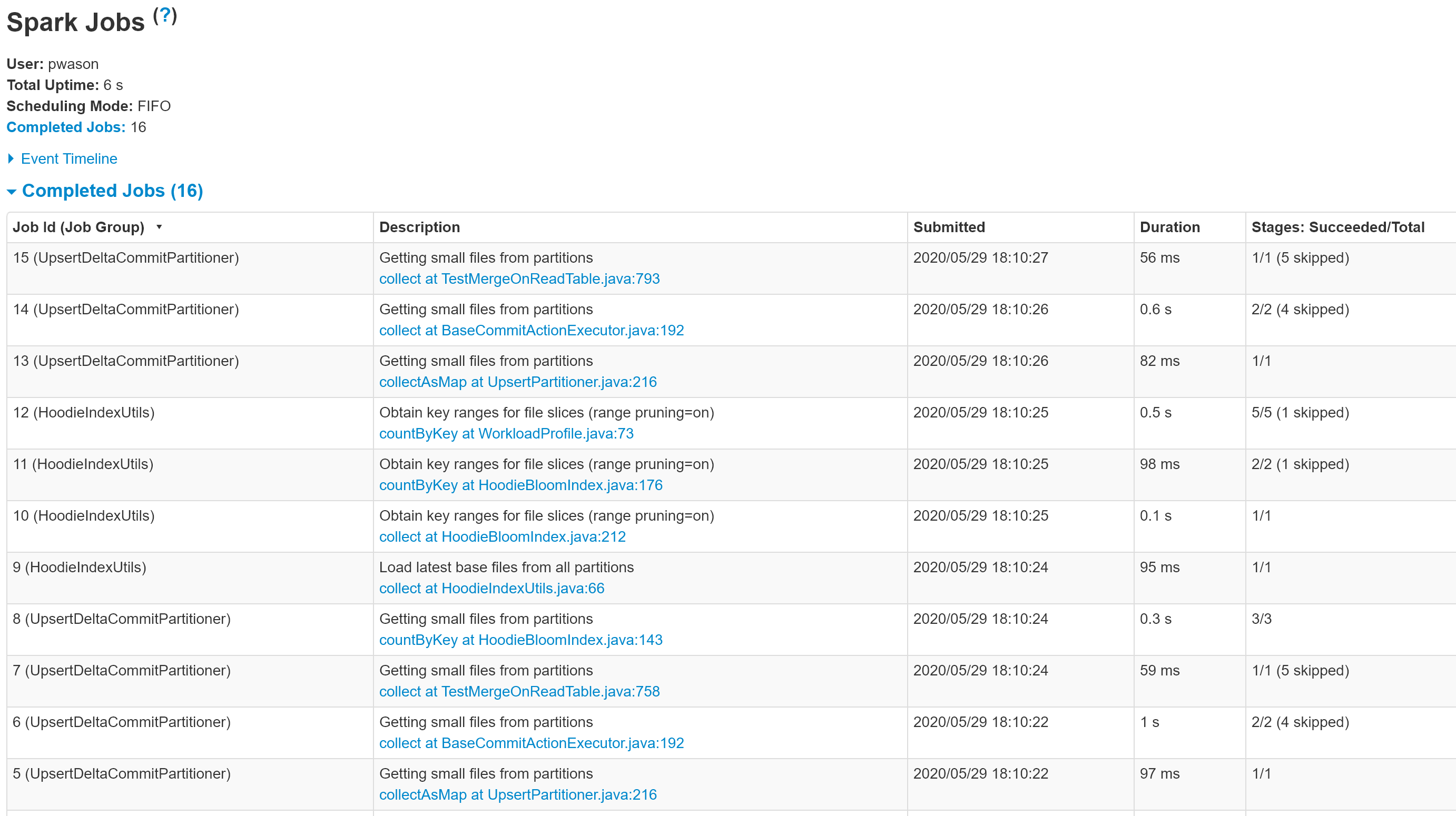
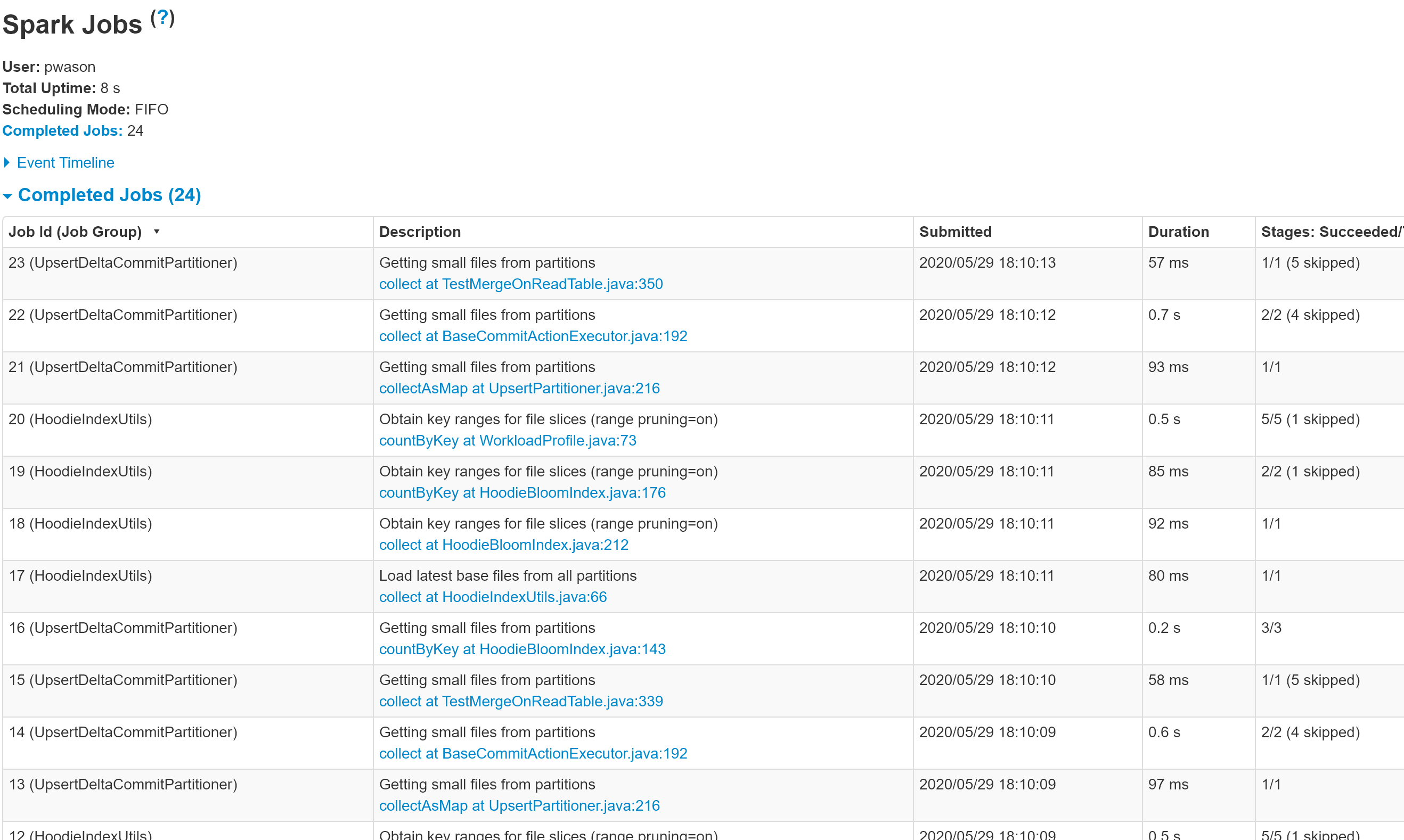
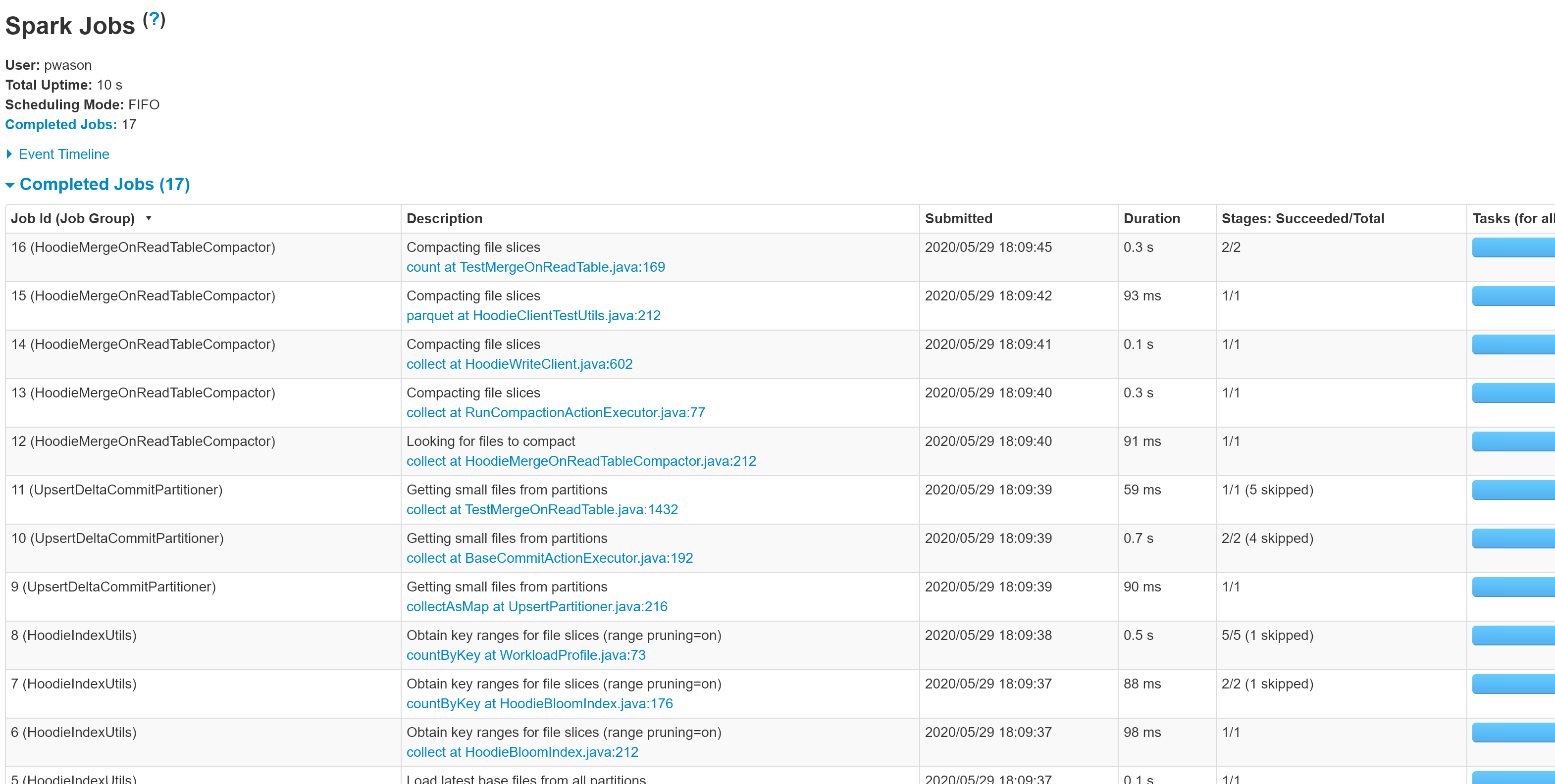
Codecov Report
@@ Coverage Diff @@
## master #1289 +/- ##
=========================================
Coverage 18.19% 18.19%
Complexity 856 856
=========================================
Files 348 348
Lines 15344 15359 +15
Branches 1523 1523
=========================================
+ Hits 2792 2795 +3
- Misses 12195 12207 +12
Partials 357 357
Continue to review full report at Codecov.
|

|
@vinothchandar could you take a look at the screenshots and see if that provides what you were looking for ? |
|
@n3nash this has been since reassigned.. feel free to grab this review, I have few others queued up before I can get to this. |
|
@prashantwason can you rebase and push please ? I can then merge this |
ed384e6 to
3d52657
Compare
|
@n3nash I have rebased the changes. Build is green. |
What is the purpose of the pull request
HUDI DAG stages do not have any names. The Spark History Server UI shows these stages with the HUDI JAVA filename and the line number.
This change provides descriptive names for the stages which makes it easier to visualize the HUDI DAG.
Brief change log
All code locations where JavaSparkContext.XXX (DAG creation methods like parallelize) are used have been updated with descriptive names for the job with the following API
jsc.setJobGroup(title, description);
Title is the class name so its easy to identify. Description is the activity for that stage.
Unit test code has been updates to enable the unit tests to write the Spark event logs so that even the unit tests can be visualized in a locally installed Spark History Server UI.
The unit tests need to be run as follows:
mvn test -DSPARK_EVLOG_DIR=/path/for/spark/event/log
Once the unit tests complete, the Spark History Server shows the application logs for all completed unit tests. The unit tests themselves can be identified by the test-class-name as the application name.
Verify this pull request
-- This pull request is already covered by existing tests, such as (please describe tests).
Committer checklist
Has a corresponding JIRA in PR title & commit
Commit message is descriptive of the change
CI is green
Necessary doc changes done or have another open PR
For large changes, please consider breaking it into sub-tasks under an umbrella JIRA.