[HUDI-5289] Avoiding repeated trigger of clustering dag#8275
Merged
nsivabalan merged 2 commits intoapache:masterfrom Mar 24, 2023
Merged
[HUDI-5289] Avoiding repeated trigger of clustering dag#8275nsivabalan merged 2 commits intoapache:masterfrom
nsivabalan merged 2 commits intoapache:masterfrom
Conversation
nsivabalan
commented
Mar 23, 2023
| * We leverage spark event listener to validate it. | ||
| */ | ||
| @Test | ||
| def testValidateClusteringForRepeatedDag(): Unit = { |
Contributor
Author
There was a problem hiding this comment.
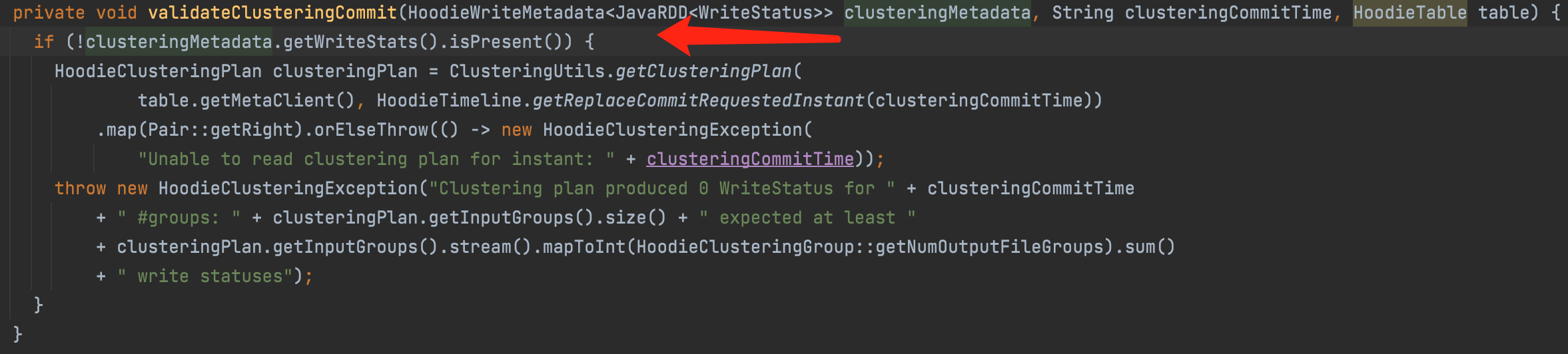
Note to Reviewer: this test fails w/o the fix in this patch. w/ the fix, it succeeds.
ede3616 to
00f671c
Compare
00f671c to
8b4506e
Compare
Collaborator
codope
approved these changes
Mar 24, 2023
...lient-common/src/main/java/org/apache/hudi/table/action/commit/BaseCommitActionExecutor.java
Show resolved
Hide resolved
KnightChess
reviewed
Mar 24, 2023
Contributor
 KnightChess
left a comment
KnightChess
left a comment
There was a problem hiding this comment.
have a doubt, why not use writeStats to jude is empty, cache writeStatuses also can cause a part of partitions recomputing if some error cause executor be removed.
Contributor
Author
|
hey @KnightChess : |
Contributor
|
@nsivabalan use |
nsivabalan
added a commit
to nsivabalan/hudi
that referenced
this pull request
Mar 25, 2023
- Avoiding repeated trigger of clustering dag
nsivabalan
added a commit
to nsivabalan/hudi
that referenced
this pull request
Mar 31, 2023
- Avoiding repeated trigger of clustering dag
fengjian428
pushed a commit
to fengjian428/hudi
that referenced
this pull request
Apr 5, 2023
- Avoiding repeated trigger of clustering dag
stayrascal
pushed a commit
to stayrascal/hudi
that referenced
this pull request
Apr 20, 2023
- Avoiding repeated trigger of clustering dag
KnightChess
pushed a commit
to KnightChess/hudi
that referenced
this pull request
Jan 2, 2024
- Avoiding repeated trigger of clustering dag
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
5 participants
Add this suggestion to a batch that can be applied as a single commit.This suggestion is invalid because no changes were made to the code.Suggestions cannot be applied while the pull request is closed.Suggestions cannot be applied while viewing a subset of changes.Only one suggestion per line can be applied in a batch.Add this suggestion to a batch that can be applied as a single commit.Applying suggestions on deleted lines is not supported.You must change the existing code in this line in order to create a valid suggestion.Outdated suggestions cannot be applied.This suggestion has been applied or marked resolved.Suggestions cannot be applied from pending reviews.Suggestions cannot be applied on multi-line comments.Suggestions cannot be applied while the pull request is queued to merge.Suggestion cannot be applied right now. Please check back later.
Change Logs
Looks like clustering dag is triggered twice even in happy path. This patch attempts at fixing the issue. This follows similar approach as compactor, where before triggering the dag for the first time, we persist the rdd. And then once the CommitMetadata is returned from table to the client, client clones the commitMetadata and any further execution will not trigger the dag again.
Impact
Clustering will by robust and will not result in spurious data files (which might eventually cleaned up anyways).
Risk level (write none, low medium or high below)
low.
Documentation Update
N/A
Contributor's checklist