NIFI-5826 Fix back-slash escaping at Lexers#3200
NIFI-5826 Fix back-slash escaping at Lexers#3200ijokarumawak wants to merge 2 commits intoapache:masterfrom
Conversation
|
There should be new tests that go along with this |
 bdesert
left a comment
bdesert
left a comment
There was a problem hiding this comment.
@ijokarumawak
I agree with @ottobackwards regarding adding test cases.
Other than that it looks fine and works as expected.
Initially I also had changed Lexer. While reviewing your solution and trying to understand why the same didn't work for me, I finally found another bug that prevented me to get proper results.
I opened JIRA for that bug, if you wish to take a look.
For this fix i've tested:
regression in EL for various backslash sequence combination in regex and in NON-regex EL functions.
I've also tested RecordPath based functions and found that this PR fixes one more defect - how backslash sequences being handled in non-regex based functions (all string literals that are processed by ANTLR).
|
@bdesert @ottobackwards Thanks for reviewing. I've added unit tests. As a reference, I run the added tests with Lexer before this PR. Following tests failed with current Lexer, but passes with the updated Lexer: This test failed with original Lexer because This test failed with original Lexer because Both tests failed with the same cause, and fixed by this PR. |
|
+1 LGTM, ran unit tests, tested fix and ran regression tests on live instance with this fix. All works as expected. Thanks for the fix! Merged to master |
Summary
Current Lexers convert a back-slash plus another character sequence (e.g.
\[) to double back-slash plus the next character (e.g.\\[).But from detailed analysis (see below), it seems the conversion is wrong and it should leave such characters as it is.
Details
I debugged how Lexer works, and found that:
ESCfragment handles an escaped special character in String representation. I.e. String\twill be converted to actual tab character.RecordPath.compilemethod as it is. E.g. the input stringreplaceRegex(/name, '\[', '')is passed to as is, then the single back-slash is converted to double back-slash by the ESC fragment line 155.Here is the Lexer code for reference:
NiFi template for test
Here is a NiFi flow template to test how before/after this change.
https://gist.github.com/ijokarumawak/b6bdca8074a4457bc4a425b90a6b17f0
In order to try the template, you need to build this PR as NiFi 1.9.0-SNAPSHOT, then download following 1.8.0 nars in your SNAPSHOT's lib dir, so that both versions can be used in the flow.
Test result
UpdateAttribute test for backward compatibility
GenerateFlowFile generates FlowFiles with attribute
awhose value is:Result

1.8.0
1.9.0-SNAPSHOT

UpdateRecord test illustrating the NIFI-5826 issue is addressed
GenerateFlowFile generates content:
Result
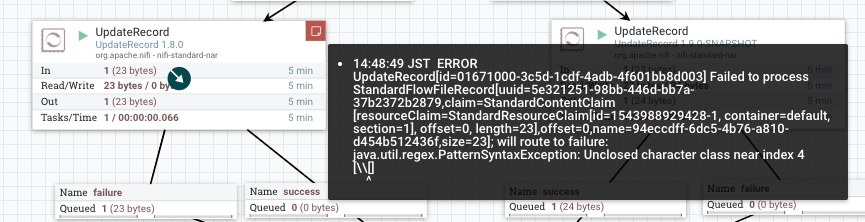
1.8.0
Regex compilation error as reported
1.9.0-SNAPSHOT
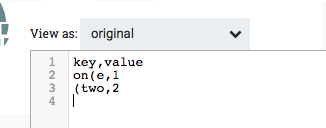
The square brackets are converted successfully
Thank you for submitting a contribution to Apache NiFi.
In order to streamline the review of the contribution we ask you
to ensure the following steps have been taken:
For all changes:
Is there a JIRA ticket associated with this PR? Is it referenced
in the commit message?
Does your PR title start with NIFI-XXXX where XXXX is the JIRA number you are trying to resolve? Pay particular attention to the hyphen "-" character.
Has your PR been rebased against the latest commit within the target branch (typically master)?
Is your initial contribution a single, squashed commit?
For code changes:
For documentation related changes:
Note:
Please ensure that once the PR is submitted, you check travis-ci for build issues and submit an update to your PR as soon as possible.