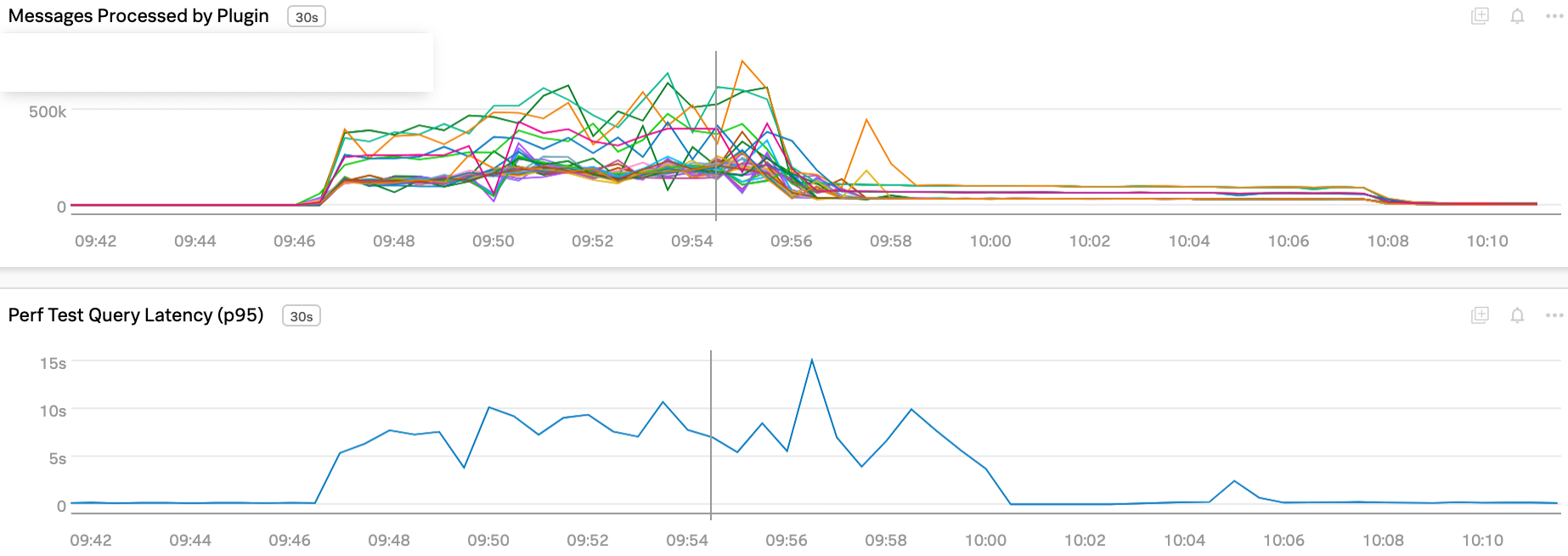
Right now our upstream Kafka log has a "batching" behavior that every a few minutes there is a sudden spike in Kafka traffic (due to upstream Flink job's checkpointing behavior). This cause a periodical Kafka backlog for our Pinot server. For example, every 30 minutes, we will suddenly have lots of Kafka backlog to catch up.
This is fine but the query performance suffers a lot during that backlog period. Based on our quick chart analysis it could be I/O bound.
Below are some of the charts we can share, showing correlation.


Right now our upstream Kafka log has a "batching" behavior that every a few minutes there is a sudden spike in Kafka traffic (due to upstream Flink job's checkpointing behavior). This cause a periodical Kafka backlog for our Pinot server. For example, every 30 minutes, we will suddenly have lots of Kafka backlog to catch up.
This is fine but the query performance suffers a lot during that backlog period. Based on our quick chart analysis it could be I/O bound.



Below are some of the charts we can share, showing correlation.