ZooKeeperChildrenCache reloading creates heavy load on Zookeeper #6563
Description
When topics are frequently created/deleted, Zookeeper is appears to be heavy loaded, which makes Pulsar cluster unstable: brokers may loose connection to Zookeeper, restart themselves, etc.
Increasing brokers number from 3 to 12 increased duration of operations that involve topics creation by 3 times: from 0.5s to 1.5s in our case. Send message operations duration has not increased.
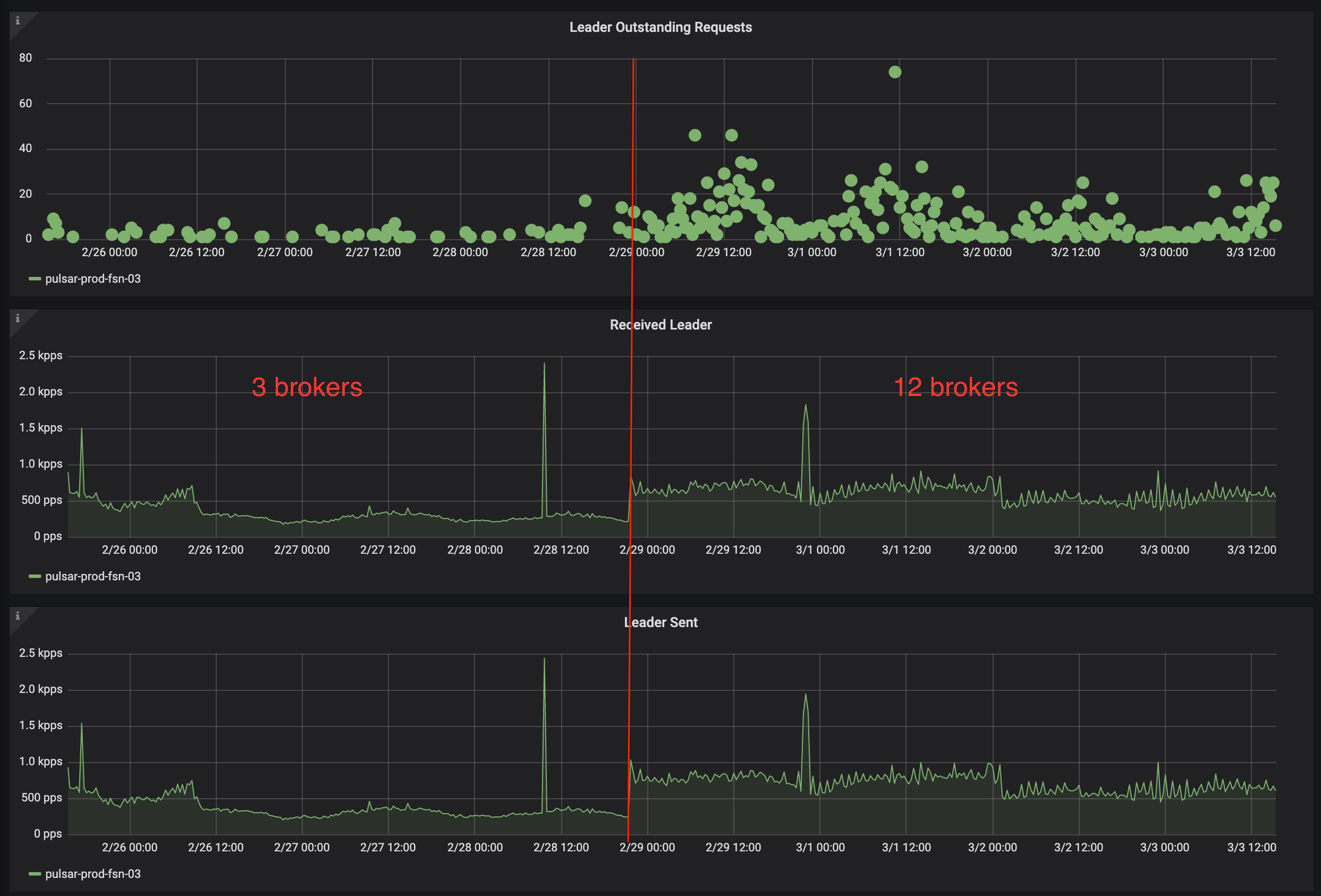
As you can see on the screenshot, before adding brokers there are also >0 outstanding request to the zk leader.
Before Zookeeper restart, there are lots of messages (tens in second) like this in the log:
Mar 10 18:29:29 pulsar[39841]: [pulsar-ordered-OrderedExecutor-5-0-EventThread]
INFO org.apache.pulsar.zookeeper.ZooKeeperChildrenCache -
[State:CONNECTED Timeout:30000 sessionid:0x2000739aa380002 local:/xxx remoteserver:xxx:2181 lastZxid:4295513491 xid:268976 sent:268977 recv:287904 queuedpkts:1 pendingresp:3 queuedevents:0]
Received ZooKeeper watch event: WatchedEvent state:SyncConnected type:NodeChildrenChanged path:/managed-ledgers/<tenant_name>/<cluster_name>/<namespace_name>/persistent
Mar 10 18:29:29 pulsar[39841]: [pulsar-ordered-OrderedExecutor-6-0] INFO org.apache.pulsar.zookeeper.ZooKeeperChildrenCache - reloadCache called in zookeeperChildrenCache for path /managed-ledgers/<tenant_name>/<cluster_name>/<namespace_name>/persistent
How to reproduce
Pulsar 2.4.1.
Approximately 2000 create/delete topic operations in a minute. 130000 short-living topics exist on average.
How to mitigate
Restart all Zookeeper instances one by one. After that topic create/delete operation duration decreased dramatically, overall performance improved and Pulsar cluster stabilized. Number of messages about reloading zk cache is decreased significantly.
On screenshots below, last zk instance was restarted at 1:46 PM. As you can see after that there is no excessive requests/ zk cache reloading.
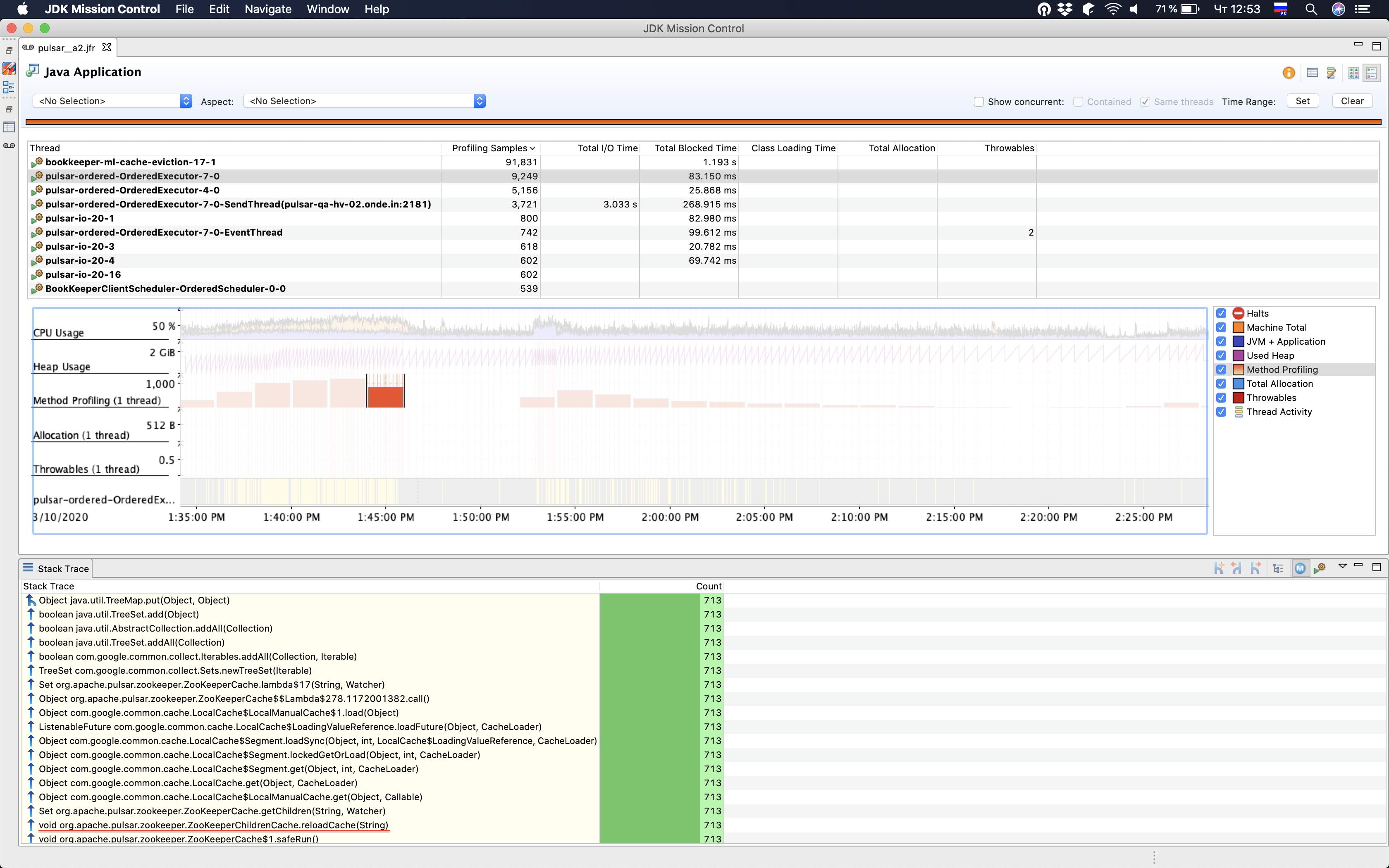
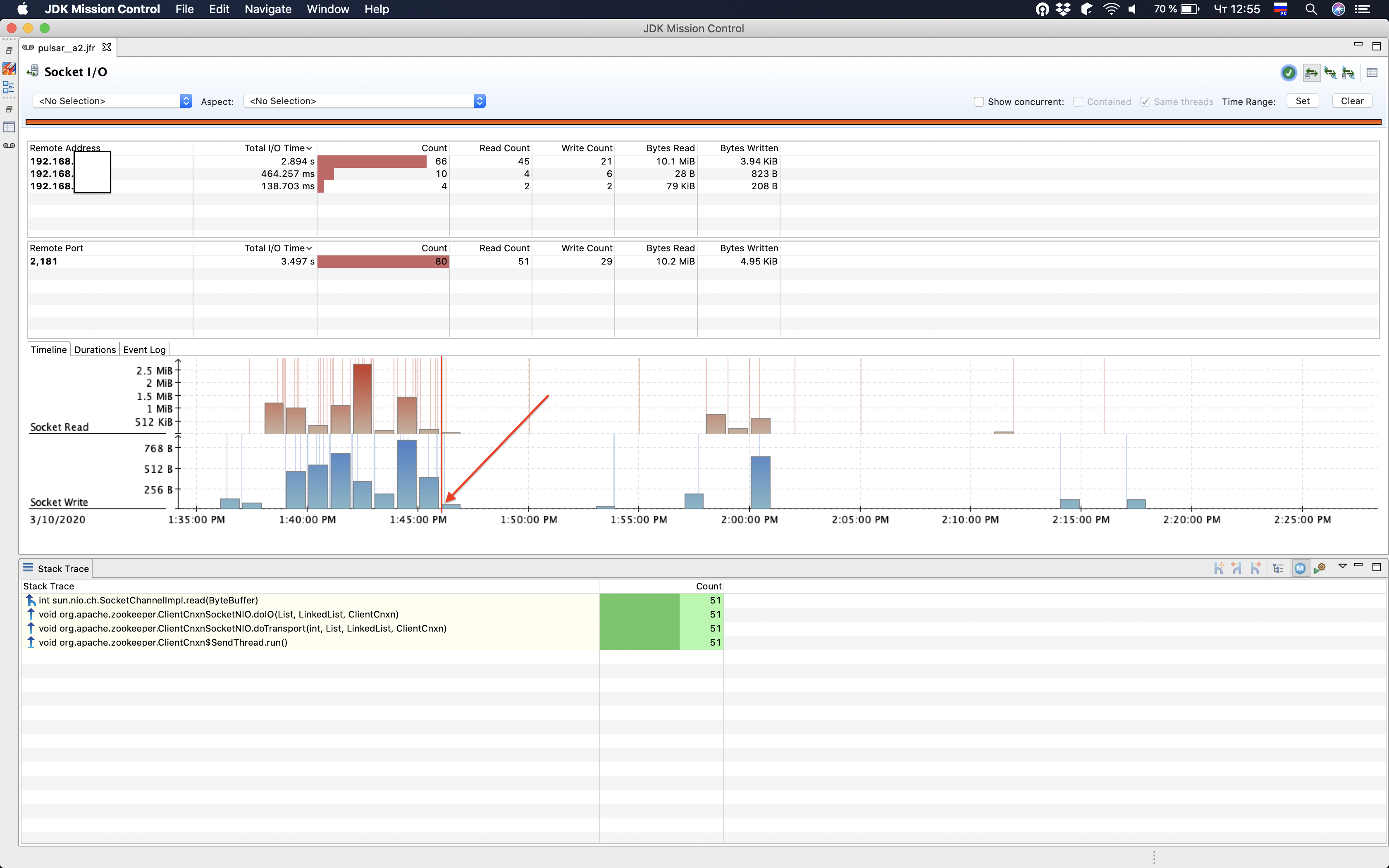
Assumption about cause
z-nodes like this contain all persistent topic names that belong to the particular namespace.
/managed-ledgers/<tenant_name>/<cluster_name>/<namespace_name>/persistent
Initially they are loaded and cached (with watcher set) during clean start of Pulsar cluster:
NamespaceService#findBrokerServiceUrl:
in method searchForCandidateBroker:
// Schedule the task to pre-load topics
pulsar.loadNamespaceTopics(bundle);
Then, each time topic is created/deleted (which happens frequently in our case), watcher is triggered, cache is reloaded (by making request to zk) and watcher is set again.
This repeats very often, and creates heavy load on Zookeeper.
However it looks like that children of nodes /managed-ledgers/<tenant_name>/<cluster_name>/<namespace_name>/persistent aren't used that often, which is proved by restarting zookeeper.
When zookeeper is restarted, zk-sessions are closed and watchers are disconnected.
So cache is not reloaded unless the /managed-ledgers/<tenant_name>/<cluster_name>/<namespace_name>/persistent node is requested again by broker, which is not the case according to logs and JFRs.
Expected behavior
Pulsar cluster is stable and shows good performance when topics are created/deleted frequently w/o Zookeeper restart.