Search before asking
Apache SkyWalking Component
OAP server (apache/skywalking)
What happened
skywalking: 8.5.0
es : 7.8.0
25,000 log errors are reported every day and crashes once a week(may be related it)
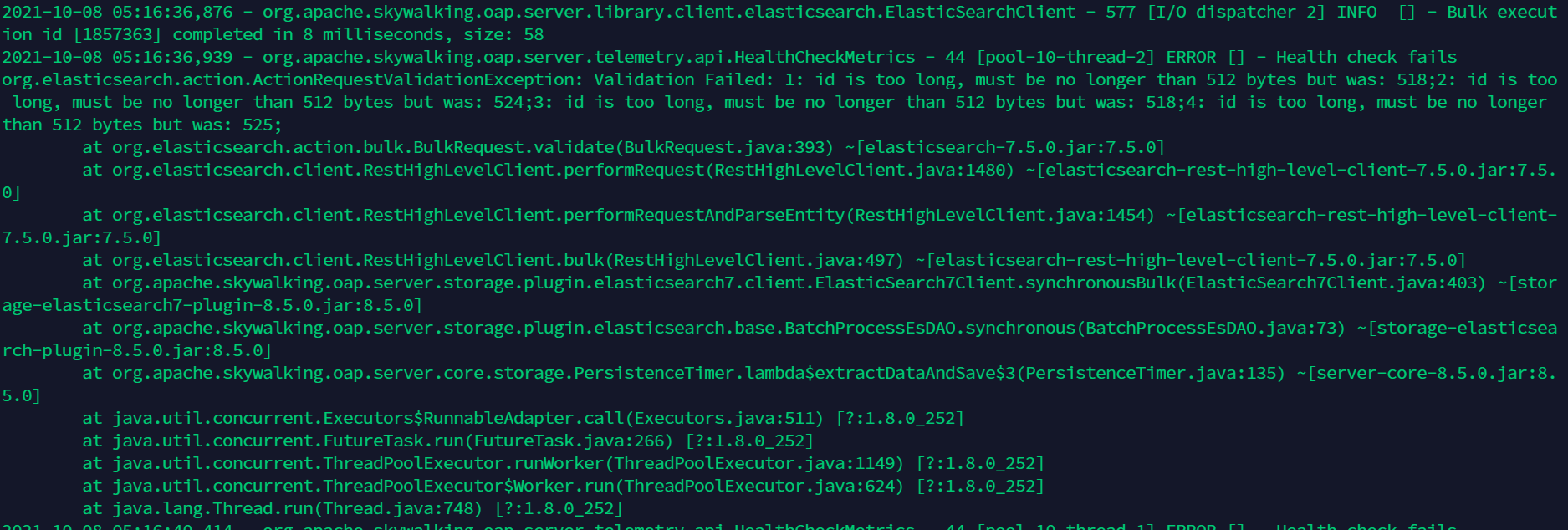
2021-10-08 05:16:36,939 - org.apache.skywalking.oap.server.telemetry.api.HealthCheckMetrics - 44 [pool-10-thread-2] ERROR [] - Health check fails
org.elasticsearch.action.ActionRequestValidationException: Validation Failed: 1: id is too long, must be no longer than 512 bytes but was: 518;2: id is too long, must be no longer than 512 bytes but was: 524;3: id is too long, must be no longer than 512 bytes but was: 518;4: id is too long, must be no longer than 512 bytes but was: 525;
at org.elasticsearch.action.bulk.BulkRequest.validate(BulkRequest.java:393) ~[elasticsearch-7.5.0.jar:7.5.0]
at org.elasticsearch.client.RestHighLevelClient.performRequest(RestHighLevelClient.java:1480) ~[elasticsearch-rest-high-level-client-7.5.0.jar:7.5.0]
at org.elasticsearch.client.RestHighLevelClient.performRequestAndParseEntity(RestHighLevelClient.java:1454) ~[elasticsearch-rest-high-level-client-7.5.0.jar:7.5.0]
at org.elasticsearch.client.RestHighLevelClient.bulk(RestHighLevelClient.java:497) ~[elasticsearch-rest-high-level-client-7.5.0.jar:7.5.0]
at org.apache.skywalking.oap.server.storage.plugin.elasticsearch7.client.ElasticSearch7Client.synchronousBulk(ElasticSearch7Client.java:403) ~[storage-elasticsearch7-plugin-8.5.0.jar:8.5.0]
at org.apache.skywalking.oap.server.storage.plugin.elasticsearch.base.BatchProcessEsDAO.synchronous(BatchProcessEsDAO.java:73) ~[storage-elasticsearch-plugin-8.5.0.jar:8.5.0]
at org.apache.skywalking.oap.server.core.storage.PersistenceTimer.lambda$extractDataAndSave$3(PersistenceTimer.java:135) ~[server-core-8.5.0.jar:8.5.0]
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) [?:1.8.0_252]
at java.util.concurrent.FutureTask.run(FutureTask.java:266) [?:1.8.0_252]
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) [?:1.8.0_252]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) [?:1.8.0_252]
at java.lang.Thread.run(Thread.java:748) [?:1.8.0_252]
What you expected to happen
normal
How to reproduce
using es 7.8.0 cluster , skywalking 8.5.0 and about 400 pod agent;
Anything else
Are you willing to submit PR?
Code of Conduct
Search before asking
Apache SkyWalking Component
OAP server (apache/skywalking)
What happened
skywalking: 8.5.0
es : 7.8.0
25,000 log errors are reported every day and crashes once a week(may be related it)
2021-10-08 05:16:36,939 - org.apache.skywalking.oap.server.telemetry.api.HealthCheckMetrics - 44 [pool-10-thread-2] ERROR [] - Health check fails
org.elasticsearch.action.ActionRequestValidationException: Validation Failed: 1: id is too long, must be no longer than 512 bytes but was: 518;2: id is too long, must be no longer than 512 bytes but was: 524;3: id is too long, must be no longer than 512 bytes but was: 518;4: id is too long, must be no longer than 512 bytes but was: 525;
at org.elasticsearch.action.bulk.BulkRequest.validate(BulkRequest.java:393) ~[elasticsearch-7.5.0.jar:7.5.0]
at org.elasticsearch.client.RestHighLevelClient.performRequest(RestHighLevelClient.java:1480) ~[elasticsearch-rest-high-level-client-7.5.0.jar:7.5.0]
at org.elasticsearch.client.RestHighLevelClient.performRequestAndParseEntity(RestHighLevelClient.java:1454) ~[elasticsearch-rest-high-level-client-7.5.0.jar:7.5.0]
at org.elasticsearch.client.RestHighLevelClient.bulk(RestHighLevelClient.java:497) ~[elasticsearch-rest-high-level-client-7.5.0.jar:7.5.0]
at org.apache.skywalking.oap.server.storage.plugin.elasticsearch7.client.ElasticSearch7Client.synchronousBulk(ElasticSearch7Client.java:403) ~[storage-elasticsearch7-plugin-8.5.0.jar:8.5.0]
at org.apache.skywalking.oap.server.storage.plugin.elasticsearch.base.BatchProcessEsDAO.synchronous(BatchProcessEsDAO.java:73) ~[storage-elasticsearch-plugin-8.5.0.jar:8.5.0]
at org.apache.skywalking.oap.server.core.storage.PersistenceTimer.lambda$extractDataAndSave$3(PersistenceTimer.java:135) ~[server-core-8.5.0.jar:8.5.0]
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) [?:1.8.0_252]
at java.util.concurrent.FutureTask.run(FutureTask.java:266) [?:1.8.0_252]
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) [?:1.8.0_252]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) [?:1.8.0_252]
at java.lang.Thread.run(Thread.java:748) [?:1.8.0_252]
What you expected to happen
normal
How to reproduce
using es 7.8.0 cluster , skywalking 8.5.0 and about 400 pod agent;
Anything else
Are you willing to submit PR?
Code of Conduct